python基础—05内置数据结构:列表与元组
文章目录
一、序列
定义:成员有序排列的,且可以通过下标偏移量访问到它的一个或者几个成员
序列包括:字符串、列表、元组
序列都支持下面的特性:
1)索引与切片操作符(s[i],s[i,j])
2)成员关系操作符(in , not in)
3)连接操作符(+) & 重复操作符(*)
字符串和元组都不可变,列表可变
二、列表list[]
1、列表和数组的区别
在c和java中常常会用到数组,但是在python中却有一个列表
数组的定义是:存储同一种数据类型的集合,即数组中的元素必须是同一个类型
而列表:是可以存储任意数据类型的集合,即列表中的元素可以是不同的类型
数组和列表在内存中的存储方式

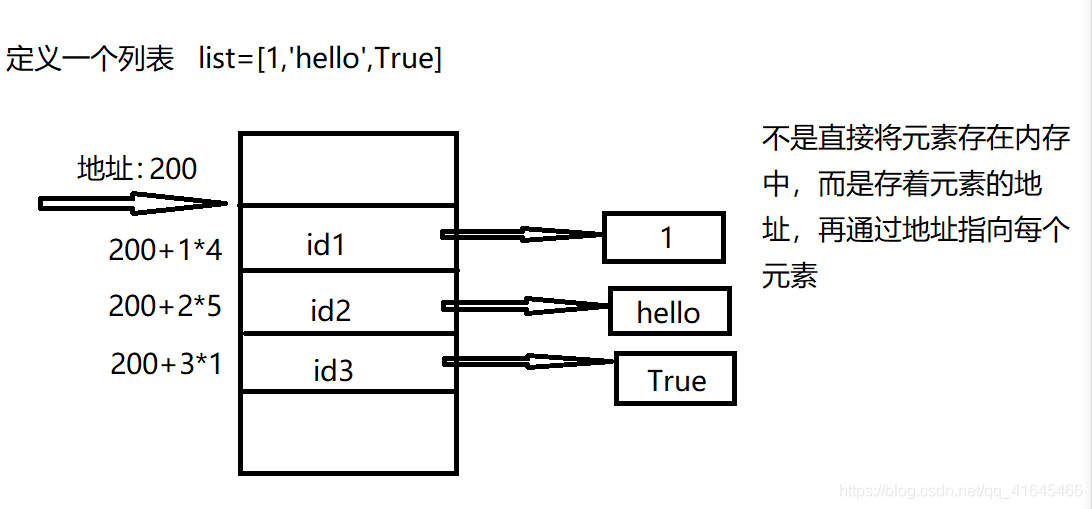
2、创建列表
创建一个空列表
list = []
创建一个包含元素的列表,元素可以是任意类型
包括数值类型,列表,字符串等均可, 也可以嵌套列表。
list = ['hello',4,True,1+2j] list = [[2,3,4],'python',10]
3、列表的特性
连接、重复、成员操作、索引、切片
#连接 list = [1,1.2,True,'hello',[1,2,3]] list1 = [2+3j,[1,1,1],4] print(list + list1) #[1, 1.2, True, 'hello', [1, 2, 3], (2+3j), [1, 1, 1], 4] #重复 print(list[3] * 3) #hellohellohello #成员操作符 print(1.2 in list) #True #索引和切片 print(list[3]) #hello print(list[-4]) #1.2 print(list[1:4]) #[1.2,True,'hello'] print(list[2:]) #[True,'hello',[1,2,3]] print(list[:3]) #[1,1.2,True] print(list[:]) #list = [1,1.2,True,'hello',[1,2,3]] print(list[::-1]) #反转 print(list[4]) #[1,2,3] print(list[4][0]) #1 嵌套索引
4、列表的内置方法
由于列表是可变的所以列表可以进行 添加、修改、删除等操作
(1)列表的添加
.append() #在列表的末尾添加一个指定元素 .extend() #在列表的末尾添加多个元素 .insert(index,object) #在索引的前面添加指定元素
eg.
li = [1,2,3]
li.append(4)
print(li) # [1,2,3,4]
li.extend(['happy',1,2]) #一定要写成[] 列表形式进行添加,不加[]就报错了
print(li) #[1, 2, 3, 4, 'happy', 1, 2]
li.insert(0,'hello') #在第0个前面添加'hello'
print(li) #['hello', 1, 2, 3, 4, 'happy', 1, 2]
#还有一点
lii = [1,2]
lii.extend('happy')
print(lii) # [1, 2, 'h', 'a', 'p', 'p', 'y'],所以还是要加[]
(2)列表的修改
修改列表的元素:直接重新赋值;
list = [1,2,3,'hello'] list[0] = 'hello' print(list) #['hello',2,3,'hello']
还可以通过切片修改:
li = [1,2,3] li[:2] = [3,4] #将前2个元素修改为3,4 print(li) #[3,4,3]
(3)列表的查看
.index() #查看元素下标 .count() #查看里表中指定元素出现的次数
eg.
list1 = ['hello','python',2,2]
print(list1.index('python')) # 1
print(list1.count(2)) # 2
(4)列表的删除
.remove() #删除列表中的指定元素 .pop() #根据索引删除指定元素,默认删除最后一个元素 .clear() #清空列表中的所有元素 del list[] #直接del通过索引删除指定元素
eg.
list = ['one','two',1,2,3] list.remove(2) print(list2) #['one', 'two', 1, 3] list.pop(1) print(list) #['one',1,3] del list[2] #['one',1]
(5)列表的一些其他操作
.reverse() #反转 .sort(reverse=True/False) # 排序,是否要反转
eg.
li = [1,2,5] li.reverse() print(li) #[5, 2, 1] li.sort(reverse=True) print(li) #[1, 2, 5]
三、元组tuple()
1、元组的创建
元组中的各个元素也可以是任意类型,
元组不可变,不能对元组的值任意更改;
判断它可不可变,就看它有没有增删改的这些方法,字符串和元组都没有这些方法,所以他们是不可变的,而列表可以改变
定义空元组
tuple = ()
定义只有一个值的元组
tuple = (1,) #一定要写 ,
一般的元组
tuple = ('hello',1,2)
2、元组的特性
连接、重复、成员操作、索引、切片
#连接
tuple1 = (1,2,3,4)
tuple2 = ('hello','world')
print(tuple1 + tuple2) #(1, 2, 3, 4 'hello', 'world')
#重复
print(tuple1 * 2) #(1, 2, 3, 4, 1, 2, 3, 4)
#成员操作符
print('python' in tuple1) #False
print(1 not in tuple2) #True
#索引和切片
print(tuple1[0]) # 1
print(tuple1(:2)) # (1,2) 截取前两个元素
print(tuple1[1:]) # (2,3,4) 截取除了第一个剩下的元素
print(tuple1[:]) # 拷贝
print(tuple1[::-1]) # 反转
print(tuple1[1:3]) # (2,3)
3、元组的内置方法
(1)元组的查看
.index() #返回指定元素下标 .count() #统计指定元素个数
eg.
t = (1,2,3,'python','python')
print(t.index(2)) # 1
print(t.count('python')) # 2
3、元组赋值
对元组分别赋值,引申对多个变量也可通过元组方式分别赋值
(name,age,gender) = ('xiaoming',10,'male') #括号可以不写
t = ('xiaohong',9,100)
name,age,score = t #有多少个元素,就用多少个变量接收
示例:
#去掉最高分和最低分,求平均得分
scores = [98,80,90,100,95]
scores.sort() #进行排序
low_score,*other_score,high_score = scores #分别进行赋值
print("最低分:",low_score)
print("最高分:",high_score)
print("中间分:",other_score)
print("平均分:", round(sunm(other_score)/len(other_score),2))
4、变量交换
在c语言中,变量交换需要通过一个中间变量来实现:
int a = 3,b = 2; int c; c = a; a = b; b = c;
而在python中,根本不用这么麻烦,
x = 2 y = 3 x,y = y,x
他具体的实现机制是:
1). 构造一个元组(y, x);
2). 构造另一个元组(x, y);
3). 元组(y, x)赋值给(x, y),元组赋值过程从左到右,依次进行
四、命名元组namedtuple
命名元组是一个类,两种方式定义
form collections import namedtuple
User = namedtuple('User',['name','age']) #创建出一个User类,包含两个属性'name','password'
User = namedtuple('User','name age')
实例化命名元组,获得类的一个实例:
user = User('xiaoming','18') #也就是传入具体的属性值
访问命名元组:逗号加属性名
user.name user.age
#在使用命名元组之前,要从collections模块中导入namedtuple命名元组类 from collections import namedtuple
小例子:
from collections import namedtuple
AccountInfo = namedtuple('AccountInfo',['name','password']) #创建AccountInfo类,包含name,password两个属性
root_account = AccountInfo('root','123') #实例化出一个对象root_acount,传属性值
print(root_account.name) #打印对象root_acount中的属性值 ,root
print(root_account.password) #打印对象root_acount中的属性值 ,123
命名元组的属性:
(1)类属性 _fields : 包含这个类所有字段名的元组
from collections import namedtuple
User = namedtuple('User',['name','age'])
user = User('xiaoming','18')
print(user._fields) #('name','age')
(2)类方法 _make() :接收一个可迭代对象来产生这个类的实例
print(User._make(['westos',10])) #User(name='westos', age=10)
(3)实例方法 _replace() :用来修改实例的属性
print(user._replace())
五、is 和 == 的区别
1). Python中对象的三个基本要素,分别是:id(身份标识)、type(数据类型)和value(值)。
2). is和 == 都是对对象进行比较判断作用的,但对对象比较判断的内容并不相同。
3).
==用来比较判断两个对象的value(值)是否相等;(type和value)
is也被叫做同一性运算符, 会判断id是否相同;(id, type 和value)

六、深拷贝和浅拷贝


会发现,在对普通数组进行拷贝时,只是将值拷贝了,地址是不一样的,所以他们就是两个不同的数组
而在嵌套数组中,会出现这样的问题:

当利用copy()拷贝后,被嵌套的数组拷贝后地址仍然不变 ,也就是说,拷贝前和拷贝后的嵌套数组是is的关系,这样,当我去改变其中一个嵌套数组里的数值时,另外一个被拷贝的数组里的嵌套数组的相对应的数值也随之改变,因此,没有做到彻底的拷贝,这就需要 深拷贝。

如此深拷贝 deepcopy()

这样就彻底拷贝了
需要在使用前导入copy模块
import copy copy.deepcopy()
来总结一下浅拷贝和深拷贝的区别:
赋值: 创建了对象的一个新的引用,修改其中任意一个变量都会影响到另一个。(=)
浅拷贝: 对另外一个变量的内存地址的拷贝,这两个变量指向同一个内存地址的变量值。(li.copy(), copy.copy())
- 公用一个值;
- 这两个变量的内存地址一样;
- 对其中一个变量的值改变,另外一个变量的值也会改变;
深拷贝: 一个变量对另外一个变量的值拷贝。(copy.deepcopy())
- 两个变量的内存地址不同;
- 两个变量各有自己的值,且互不影响;
- 其任意一个变量的值的改变不会影响另外一个;
七、一个命名元组应用的实例
"""
项目背景: 腾讯云服务器 CVM(Cloud Virtual Machine)是腾讯云提供的可扩展的计算服务。
使用 CVM 避免了使用传统服务器时需要预估资源用量及前期投入,帮助您在短时间内快速启动任意
数量的云服务器并即时部署应用程序。腾讯云 CVM 支持用户自定义一切资源:CPU、内存、硬盘、
网络、安全等等,并可以在需求发生变化时轻松地调整它们。
需求:
******************************************
***************云主机管理系统 ***************
******************************************
1). 添加云主机
2). 删除云主机
3). 修改云主机
4). 查看云主机
0). 退出系统
******************************************
云主机的属性信息:
id: 递增,主机id
IPv4: 主机IP
disk: 主机硬盘大小
memory: 主机内存大小
name: 主机别名
分析:要进行添加云主机,删除云主机,修改云主机,查看云主机的操作
(1)添加云主机:用哪种数据类型来存储云主机的信息,云主机的信息不止一个有很多,所以选择列表来存储,并且通过命名元组来存储
(2)删除云主机:通过用户输入的id号来删除
"""
# 使用命名元组namedtuple ,导入模块
from collections import namedtuple
# 创建表格形式显示云主机信息,需要导入prettytable模块
from prettytable import PrettyTable
# 创建云主机管理系统菜单栏
prompt = """
******************************************
***************云主机管理系统 ***************
******************************************
1. 添加云主机
2. 删除云主机
3. 修改云主机
4. 查看云主机
0. 退出系统
******************************************
请输入选择>>>
"""
# 需要一个存储所有云主机信息的数据库列表
hosts_db = []
# 通过命名元组来定义云主机需要存储的信息
Host = namedtuple('Host',['Id','IPv4','Disk','Memory','Name'])
# Id号递增,先设置一个初始值
id = 0
while True:
choice = input(prompt) #用户选择
# 如果用户选择(1),进行添加云主机
if choice == '1':
#pass
print("添加云主机".center(40,'*'))
# 用户开始添加云主机信息
id += 1 #Id号递增
ipv4 = input("主机IP(eg:172.25.254.111)>>>")
disk = input("主机硬盘大小(eg:500G)>>>")
memory = input("主机内存大小(eg:4G)>>>")
name = input("主机别名(eg:数据库服务器)>>>")
# 用户输入云主机的信息后,实例化出一个具体的Host对象,将每个属性值传入Host()
# 再将这个对象添加到数据库列表hosts_db = []中,append()
hosts_db.append(Host(Id=id , IPv4=ipv4 , Disk=disk , Memory=memory , Name=name))
# 添加完毕,显示信息
print("添加云主机 %s 成功"%(name))
# 如果用户选择(2),进行删除云主机
elif choice == '2':
#pass
print("删除云主机".center(40, '*'))
# 用户输入云主机id进行删除
del_id = int(input("要删除的主机Id>>>"))
# 遍历数据库列表hosts_db来寻找这个id,找到并删除
for host in hosts_db:
if host.Id == del_id: #访问命名元组: 对象名.属性
hosts_db.remove(host)
print("删除Id=%d的云主机成功"%(del_id))
break
else:
print("没有找到Id=%d的云主机,删除失败"%(del_id))
# 如果用户选择(3),进行修改云主机
elif choice == '3':
# 如果我们的目标是定义一个高效的数据结构,而且将来会修改各种实例属性,那么使用 namedtuple 并不是最佳选择
# 修改云主机暂时不处理
pass
# 如果用户选择(4),进行查看云主机
elif choice == '4':
#pass
# 用一个表格来显示信息更美观
# 创建表格,并指定表头信息和格式,需要导入 prettytable 模块,
# 这里要手动安装这个第三方模块 ,在Terminal中敲入 pip install prettytable
hosts_table = PrettyTable(field_names=['Id','IPv4','Disk','Memory','Name'])
# 遍历主机信息,按行添加数据到表格中
for host in hosts_db:
hosts_table.add_row(host)
# 打印表格
print(hosts_table)
# 如果用户选择(0),退出系统
elif choice == '0':
#pass
exit(0)
else:
print("请输入正确的选项")
- 点赞
- 收藏
- 分享
- 文章举报
 小黑--
发布了32 篇原创文章 · 获赞 1 · 访问量 863
私信
关注
小黑--
发布了32 篇原创文章 · 获赞 1 · 访问量 863
私信
关注

- python基础(5)---整型、字符串、列表、元组、字典内置方法和文件操作介绍
- python基础知识——内置数据结构(列表)
- python课程第二周 内置数据结构——列表和元组
- Python基础语法-内置数据结构之列表
- Python基础学习之基本数据结构详解【数字、字符串、列表、元组、集合、字典】
- python基础系列教程——数据结构(列表、元组、字典、集合、链表)
- Python内置数据结构——列表list,元组tuple
- python基础知识——内置数据结构(元组)
- Python中几种数据结构的整理,列表、字典、元组、集合
- python字符串,元组,列表,集合的基础总结
- A Byte of Python 笔记(7)数据结构:列表、元组、字典,序列
- python学习(基础补充)--字符串、列表、元组
- 刻意练习Python基础 ——day 03:列表与元组(上)
- Python数据结构(列表、字典、集合、元组)详细解析
- Python基础学习简记--列表与元组(Day3)
- Python数据结构:列表、字典、元组、集合
- Python 入门学习 -----变量及基础类型(元组,列表,字典,集合)
- python基础教程总结1——列表和元组
- 小甲鱼python零基础013元组:戴上了枷锁的列表
- Python基础【数据结构:列表 | 元组 | 集合 | 字典】