数据结构-python
1 概念
1.1 时间复杂度
假设存在函数g,使得算法A处理规模为n的问题示例所用时间为T(n)=O(g(n))则称T(n)为算法A的渐近时间复杂度,简称时间复杂度。
g(n)则称为一个时间复杂度的大O表示法。
渐近函数定义:考虑一个函数
 ,我们需要了解当
,我们需要了解当
 变得非常大的时候
变得非常大的时候
 的性质。令
的性质。令
 ,在
,在
 特别大的时候,第二项
特别大的时候,第二项

比起第一项
 要小很多。于是对于这个函数,有如下断言:
要小很多。于是对于这个函数,有如下断言:
 在
在
 的情况下与
的情况下与
 渐近等价”,记作
渐近等价”,记作
 。
。
最坏时间复杂度:算法完成工作最多需要多少基本操作。
时间复杂度的基本计算规则:
- 基本操作,即只有常数项,认为其时间复杂度为O(1)
- 顺序结构,时间复杂度按加法进行计算
- 循环结构,时间复杂度按乘法进行计算
- 分支结构,时间复杂度取最大值
- 判断一个算法的效率时,往往只需要关注操作数量的最高次项,其它次要项和常数项可以忽略
常见时间复杂度:
| 执行次数函数举例 | 阶 | 非正式术语 |
|---|---|---|
| 12 | O(1) | 常数阶 |
| 2n+3 | O(n) | 线性阶 |
| 3n^2+2n+1 | O(n^2) | 平方阶 |
| 5log2n+20 | O(logn) | 对数阶 |
| 2n+3nlog2n+19 | O(nlogn) | nlogn阶 |
| 6n^3+2n^2+3n+4 | O(n^3) | 立方阶 |
| 2^n | O(2^n) | 指数阶 |
常见时间复杂度之间的关系:
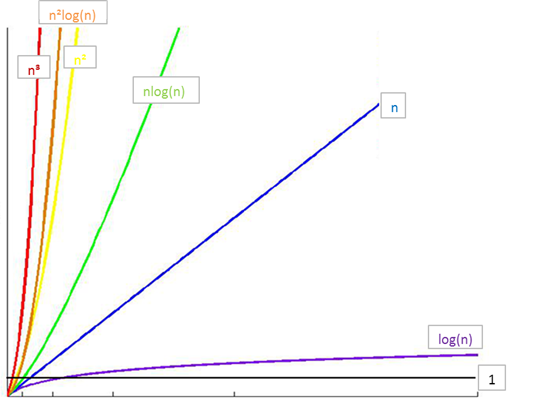
所消耗的时间从小到大:O(1) < O(logn) < O(n) < O(nlogn) < O(n^2) < O(n^3) < O(2^n) < O(n!) < O(n^n)
1.2 timeit模块(python内置模块分析性能)
class timeit.Timer(stmt='代码', setup='运行代码的设置', timer=<定时器函数>)
timeit.Timer.timeit(number=1000000):Timer类中测试语句执行速度的对象方法。number参数是测试代码时的测试次数。
def cal():
for a in range(1001):
for b in range(1001-a):
c = 1000-a-b
if a**2 + b**2 == c**2 :
return a,b,c
t = timeit.Timer('cal()','from __main__ import cal')
print(t.timeit(number=1000))
1.3 数据结构
数据结构只是静态的描述了数据元素之间的关系。Python的内置数据结构:列表、元组、字典。
程序 = 数据结构 + 算法
抽象数据类型(ADT):一个数学模型以及定义在此数学模型上的一组操作。
常用数据运算:插入、删除、修改、查找、排序。
2 线性表
- 顺序表,将元素顺序地存放在一块连续的存储区里,元素间的顺序关系由它们的存储顺序自然表示。
- 链表,将元素存放在通过链接构造起来的一系列存储块中。
2.1 顺序表
eg.python中list为线性表。
eg.int类型在32位计算机中,存储空间为4个字节(8位),在内存中按照连续存储单元(1个字节)进行存储。
1、连续存储元素信息 2、连续存储地址信息

2.1.1 线性表结构
线性表的空间是固定的,若要进行扩充:1、增加固定数目 2、每次扩充容量加倍
头部插入数据时间复杂度为O(1),中间插入和尾部插入时间复杂度为O(n)。
list内置操作的时间复杂度:

dict内置操作的时间复杂度:
2.2 链表
在每一个节点(数据存储单元)里存放下一个节点的位置信息(即地址)。链表需要额外开销存储位置信息,但是在内存中是分散存储的,所以可以充分离散的内存空间。
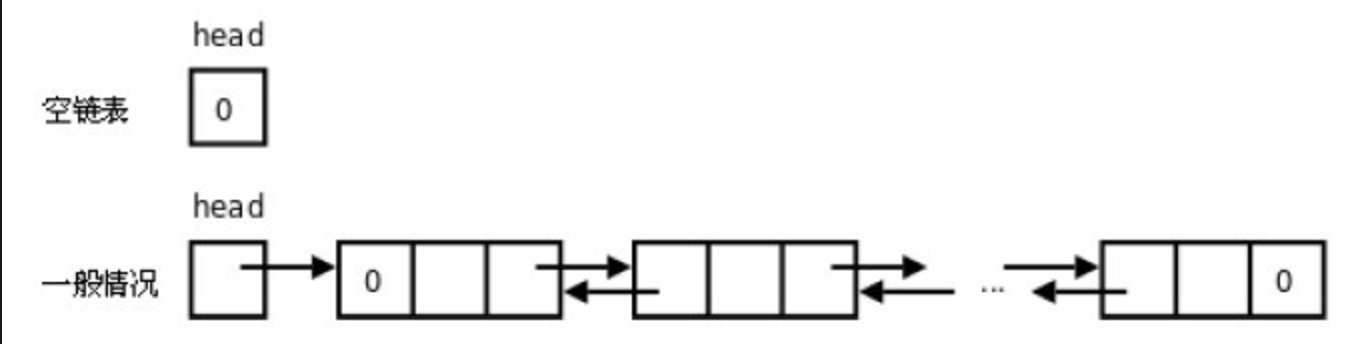
2.2.1 单向链表

class SingleNode(object): '''节点''' def __init__(self,item): self.elem = item self.next = None class SingleLink(object): def __init__(self): self.__head =None def is_empty(self): '''链表是否为空''' return self.__head ==None def length(self): '''链表长度''' #cur游标,用来移动遍历节点 cur = self.__head count = 0 while cur != None: count +=1 cur = cur.next return count def travel(self): '''遍历整个链表''' cur = self.__head while cur != None: print(cur.elem,end= '') cur = cur.next def add(self,item): '''链表头部添加元素''' # 先创建一个保存item值的节点 node = SingleNode(item) node.next = self.__head self.__head = node def append(self,item): '''链表尾部添加元素''' node = SingleNode(item) if self.__head == None: self.__head = node else: cur = self.__head while cur.next != None: cur = cur.next cur.next = node def insert(self,pos,item): '''指定位置添加元素''' node = SingleNode(item) cur = self.__head if pos ==0: node.next = cur self.__head = node elif self.length()-1< pos: while cur != None: cur = cur.next cur.next =item else: count = 0 while count != pos-1: count +=1 cur = cur.next node.next = cur.next cur.next = node def remove(self,item): '''指定元素删除节点''' node = SingleNode(item) cur = self.__head pre = None while cur!= None: if cur.elem == node.elem: # 如果第一个就是删除的节点 if not pre: self.__head = cur.next else: pre.next = cur.next break else: pre = cur cur = cur.next def search(self,item): '''查找节点是否存在''' cur = self.__head node = SingleNode(item) while cur !=None: if cur.elem == node.elem: return True else: cur = cur.next return False if __name__ == '__main__': l = SingleLink() print(l.is_empty()) l.add(1) l.add(2) l.append(0) l.insert(0,3) l.insert(2, 0) l.remove(0) l.remove(4) print(l.is_empty()) print(l.search(4)) print(l.search(0)) print(l.length()) l.travel()
2.2.2 双向链表
class DoubleNode(object):
def __init__(self,item):
self.elem = item
self.pre = None
self.next = None
class DoubleLink(object):
def __init__(self):
self.__head = None
def is_empty(self):
return self.__head == None
def length(self):
cur = self.__head
count = 0
while cur!=None:
count +=1
cur= cur.next
return count
def travel(self):
cur = self.__head
if self.__head ==None:
return
else:
while cur!=None:
print(cur.elem,end="")
cur = cur.next
print("")
def add(self,item):
node = DoubleNode(item)
if self.__head ==None:
self.__head = node
else:
node.next =self.__head
self.__head.pre = node
self.__head = node
def append(self,item):
node =DoubleNode(item)
if self.__head ==None:
self.__head = node
else:
cur = self.__head
while cur.next!=None:
cur = cur.next
node.pre = cur
cur.next = node
def insert(self,pos,item):
node = DoubleNode(item)
if pos <=0:
self.add(item)
elif pos >= self.length():
self.append(item)
else:
count = 0
cur = self.__head
if count != pos:
count +=1
cur = cur.next
node.next = cur
node.pre = cur.pre
cur.pre.next = node
cur.pre = node
def remove(self,item):
node = DoubleNode(item)
if self.__head ==None:
return
else:
cur = self.__head
if cur.elem == item:
# 如果首节点的元素即是要删除的元素
if cur.next == None:
# 如果链表只有这一个节点
self.__head = None
else:
# 将第二个节点的prev设置为None
cur.next.pre = None
# 将_head指向第二个节点
self.__head = cur.next
return
while cur.next!= None:
if cur.elem == item:
# 将cur的前一个节点的next指向cur的后一个节点
cur.pre.next = cur.next
# 将cur的后一个节点的prev指向cur的前一个节点
cur.next.pre = cur.pre
break
cur = cur.next
#删除的是最后一个
if cur.elem ==item:
cur.pre.next = None
else:
return
def search(self,item):
node = DoubleNode(item)
cur = self.__head
while cur !=None:
if cur.elem != node.elem:
cur =cur.next
else:
return True
return False
2.2.3 单向循环列表

class SingleCircleNode(object): def __init__(self,item): self.elem = item self.node =None class SingleCircleLink(object): def __init__(self): self.__head = None def is_empty(self): return self.__head == None def length(self): if self.__head == None: return 0 else: count = 1 cur = self.__head while cur.next != self.__head: count +=1 cur = cur.next return count def travel(self): if self.__head == None: return else: cur = self.__head while cur.next !=self.__head: print(cur.elem,end="") cur = cur.next print(cur.elem) def add(self,item): node = SingleCircleNode(item) if self.__head == None: self.__head = node node.next = self.__head else: cur = self.__head while cur.next !=self.__head: cur = cur.next node.next = self.__head self.__head = node cur.next = self.__head def append(self,item): node = SingleCircleNode(item) if self.__head ==None: self.__head = node node.next = self.__head else: cur = self.__head while cur.next !=self.__head: cur =cur.next node.next = self.__head cur.next = node def insert(self,pos,item): node = SingleCircleNode(item) if pos <=0: self.add(item) elif pos >= self.length(): self.append(item) else: count =1 cur = self.__head while pos !=count: count +=1 cur = cur.next node.next = cur.next cur.next = node def remove(self,item): """删除一个节点""" # 若链表为空,则直接返回 if self.is_empty(): return # 将cur指向头节点 cur = self.__head pre = None # 若头节点的元素就是要查找的元素item if cur.elem == item: # 如果链表不止一个节点 if cur.next != self.__head: # 先找到尾节点,将尾节点的next指向第二个节点 while cur.next != self.__head: cur = cur.next # cur指向了尾节点 cur.next = self.__head.next self.__head = self.__head.next else: # 链表只有一个节点 self.__head = None else: pre = self.__head # 第一个节点不是要删除的 while cur.next != self.__head: # 找到了要删除的元素 if cur.elem == item: # 删除 pre.next = cur.next return else: pre = cur cur = cur.next # cur 指向尾节点 if cur.elem == item: # 尾部删除 pre.next = cur.next # node = SingleCircleNode(item) # if self.__head == None: # return # cur = self.__head # pre = None # while cur.next != self.__head: # if cur.elem == node.elem: # if pre is None: # rear = self.__head # while rear.next != self.__head: # rear = rear.next # self.__head = cur.next # rear.next = self.__head # else: # pre.next = cur.next # break # else: # pre = cur # cur = cur.next # if cur.elem == node.elem: # #匹配只有一个元素且是第一个元素 # if pre is None: # self.__head ==None # #匹配最后一个元素 # else: # pre.next = self.__head # else: # return # else: # cur = self.__head # pre = None # if cur.elem == node.elem: # if cur.next == None: # self.__head = None # else: # node.next = cur.next # self.__head = node # while cur.next != self.__head: # if cur.elem == node.elem: # pre.next = cur.next # else: # pre = cur # cur = cur.next # break # if cur.elem == node.elem: # pre.next = self.__head # else: # return def search(self,item): if self.__head ==None: return False else: cur = self.__head while cur.next != self.__head: if cur.elem == item: return True else: cur =cur.next if cur.next == item: return True else: return False
3 栈(stack)
也称堆栈,是一种容器,可存入数据元素、访问元素、删除元素。由于栈数据结构只允许在一端进行操作,因而按照后进先出(LIFO, Last In First Out)的原理运作。
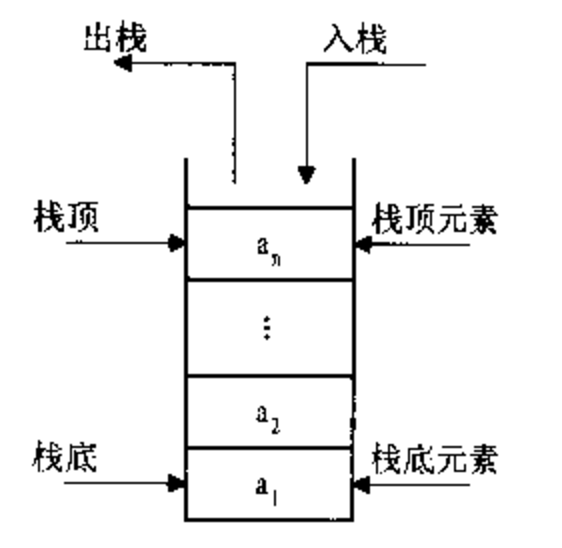
class Stack(object): def __init__(self): self.items = [] def is_empty(self): '''判断栈是否为空''' return self.items ==[] def size(self): '''返回栈的元素个数''' return len(self.items) def push(self,item): '''添加一个新的元素item到栈顶''' self.items.append(item) def pop(self): '''弹出栈顶元素''' return self.items.pop() def peek(self): '''返回栈顶元素''' return self.items[len(self.items)-1] if __name__ == '__main__': s = Stack() s.push(1) s.push(2) print(s.pop()) print(s.peek())
4 队列(queue)
class Queue(object): def __init__(self): self.items = [] def is_empty(self): '''判断一个队列是否为空''' return self.items == [] def size(self): '''返回队列的大小''' return len(self.items) def enqueue(self,item): '''往队列中添加一个item元素''' self.items.append(item) def dequeue(self): '''从队列头部删除一个元素''' return self.items.pop(0)
4.1 双端队列
双端队列(deque,全名double-ended queue),是一种具有队列和栈的性质的数据结构。
双端队列中的元素可以从两端弹出,其限定插入和删除操作在表的两端进行。双端队列可以在队列任意一端入队和出队。
class Deque(object): '''创建一个空的双端队列''' def __init__(self): self.items = [] def is_empty(self): '''判断双端队列是否为空''' return self.items == [] def size(self): '''返回队列的大小''' return len(self.items) def add_front(self,item): '''从队头加入一个item元素''' self.items.insert(0,item) def add_rear(self,item): '''从队尾加入一个item元素''' self.items.append(item) def remove_front(self): '''从队头删除一个item元素''' return self.items.pop(0) def remove_rear(self): '''从队尾删除一个item元素''' return self.items.pop()
5 排序与算法
算法的稳定性:稳定性:稳定排序算法会让原本有相等键值的纪录维持相对次序。
5.1 冒泡排序(Bubble Sort)
冒泡排序算法如下:
- 比较相邻的元素。如果第一个比第二个大(升序),就交换他们两个。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
时间复杂度:
- 最优时间复杂度:O(n) (表示遍历一次发现没有任何可以交换的元素,排序结束。)
- 最坏时间复杂度:O(n2)
- 稳定性:稳定
def BubbleSort(alist): n = len(alist)
count =0 for j in range(n-1): for i in range(n-1-j): if alist[i] > alist[i+1]: alist[i],alist[i+1] = alist[i+1],alist[i]
count +=1
if count ==0
return
if __name__ == '__main__': alist = [7,2,5,7,1,9,0,3,4] BubbleSort(alist) print(alist)
5.2 选择排序(Selection sort)
- 在未排序序列中找到最小(大)元素,存放到排序序列的起始位置
- 再从剩余未排序元素中继续寻找最小(大)元素,放到已排序序列的末尾
- 以此类推,直到所有元素均排序完毕
时间复杂度:
- 最优时间复杂度:O(n2)
- 最坏时间复杂度:O(n2)
- 稳定性:不稳定(考虑升序每次选择最大的情况)
def SelectionSort(alist): n = len(alist) for j in range(n-1): min_index = j for i in range(j+1,n): if alist[min_index] > alist[i]: min_index=i alist[min_index],alist[j] = alist[j],alist[min_index] if __name__ == '__main__': alist = [7,2,5,7,1,9,0,3,4] SelectionSort(alist) print(alist)
5.3 插入排序(Insertion Sort)
通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
时间复杂度:
- 最优时间复杂度:O(n) (升序排列,序列已经处于升序状态)
- 最坏时间复杂度:O(n2)
- 稳定性:稳定
def InsertionSort(alist): n = len(alist) for i in range(n): while i>0: if alist[i] < alist[i-1]: alist[i],alist[i-1]=alist[i-1],alist[i] i -=1 if __name__ == '__main__': alist = [7,2,5,7,1,9,0,3,4] InsertionSort(alist) print(alist)
5.4 希尔排序(Shell Sort)
也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本。
时间复杂度:
- 最优时间复杂度:根据步长序列的不同而不同
- 最坏时间复杂度:O(n2)
- 稳定想:不稳定
def ShellSort(alist): n = len(alist) gap = n//2 while gap >0: for i in range(gap,n): while i>0: if alist[i] < alist[i-gap]: alist[i],alist[i-gap]= alist[i-gap],alist[i] i -=gap gap = gap//2 if __name__ == '__main__': alist = [7,2,5,7,1,9,0,3,4] ShellSort(alist) print(alist)
5.5 快速排序(Quick Sort)
也称划分交换排序(partition-exchange sort)
快速排序步骤为:
- 从数列中挑出一个元素,称为"基准"(pivot);
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序,递归的最底部情形,是数列的大小是零或一。
时间复杂度:
- 最优时间复杂度:O(nlogn)
- 最坏时间复杂度:O(n2)
- 稳定性:不稳定
def QuickSort(alist,first,last): if first >= last: return mid = alist[first] low = first high = last while low<high: while low<high and alist[high]>=mid: high -=1 alist[high],alist[low]=alist[low],alist[high] while low <high and alist[low]<mid: low +=1 alist[low],alist[high]=alist[high],alist[low] alist[low]=mid QuickSort(alist,first,low-1) QuickSort(alist,low+1,last) if __name__ == '__main__': alist = [7,2,5,7,1,9,0,3,4] QuickSort(alist,0,len(alist)-1) print(alist)
5.6 归并排序
归并排序的思想就是先递归分解数组,再合并数组。
将数组分解最小之后,比较两个数组的最前面的数,谁小就先取谁,取了后相应的指针就往后移一位。然后再比较,直至一个数组为空,最后把另一个数组的剩余部分复制过来即可。
时间复杂度:
- 最优时间复杂度:O(nlogn)
- 最坏时间复杂度:O(nlogn)
- 稳定性:稳定
def MergeSort(alist): n = len(alist) if n <=1: return alist mid = n//2 left_list = MergeSort(alist[:mid]) right_list = MergeSort(alist[mid:]) left_point,right_point = 0,0 result = [] while left_point<len(left_list) and right_point<len(right_list): if left_list[left_point] <= right_list[right_point]: result.append(left_list[left_point]) left_point +=1 else: result.append(right_list[right_point]) right_point+=1 #将循环剩下的的元素添加到列表的最后 result += left_list[left_point:] result += right_list[right_point:] return result if __name__ == '__main__': alist = [7,2,5,7,1,9,0,3,4] l = MergeSort(alist) print(l)
5.7 算法效率比较

5.8 搜索
搜索的几种常见方法:顺序查找、二分法查找、二叉树查找、哈希查找
二分查找:作用于有序的线性表。
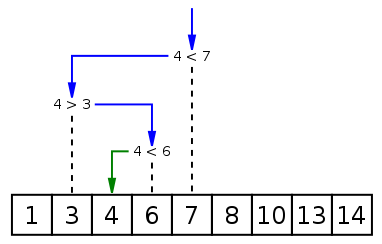
时间复杂度:
- 最优时间复杂度:O(1)
- 最坏时间复杂度:O(logn)
def BinarySearch(alist,item): if len(alist) == 0: return False else: mid = len(alist)//2 if alist[mid] == item: return True elif alist[mid] > item: return BinarySearch(alist[:mid-1],item) else: return BinarySearch(alist[mid+1:],item) if __name__ =='__main__': print(BinarySearch([4,6,7,8],4))
6 树与树的算法
树的概念:树(tree)是一种抽象数据类型(ADT)或是实作这种抽象数据类型的数据结构。
特点:
- 每个节点有零个或多个子节点;
- 没有父节点的节点称为根节点;
- 每一个非根节点有且只有一个父节点;
- 除了根节点外,每个子节点可以分为多个不相交的子树。
术语:
- 节点的度:一个节点含有的子树的个数称为该节点的度;
- 树的度:一棵树中,最大的节点的度称为树的度;
- 叶节点或终端节点:度为零的节点;
- 父亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点;
- 孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点;
- 兄弟节点:具有相同父节点的节点互称为兄弟节点;
- 节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
- 树的高度或深度:树中节点的最大层次;
- 堂兄弟节点:父节点在同一层的节点互为堂兄弟;
- 节点的祖先:从根到该节点所经分支上的所有节点;
- 子孙:以某节点为根的子树中任一节点都称为该节点的子孙。
- 森林:由m(m>=0)棵互不相交的树的集合称为森林。
种类:
- 无序树:树中任意节点的子节点之间没有顺序关系,这种树称为无序树,也称为自由树;
- 有序树:树中任意节点的子节点之间有顺序关系,这种树称为有序树; 二叉树:每个节点最多含有两个子树的树称为二叉树; 完全二叉树:对于一颗二叉树,假设其深度为d(d>1)。除了第d层外,其它各层的节点数目均已达最大值,且第d层所有节点从左向右连续地紧密排列,这样的二叉树被称为完全二叉树,其中满二叉树的定义是所有叶节点都在最底层的完全二叉树;
- 平衡二叉树(AVL树):当且仅当任何节点的两棵子树的高度差不大于1的二叉树;
- 排序二叉树(二叉查找树(英语:Binary Search Tree),也称二叉搜索树、有序二叉树);
存储:顺序存储和链式存储(通过lchild和rchild指针)。
class Node(object): def __init__(self,item,lchild=None,rchild=None): self.root = item self.lchild = lchild self.rchild = rchild class Tree(object): def __init__(self,root=None): self.root = root def add(self,elem): node = Node(elem) if self.root ==Node: self.root = node #如果根节点不为空 else: queue = [] queue.append(self.root) while queue: cur = queue.pop(0) if cur.lchild == Node: cur.lchild ==node return elif cur.rchild ==None: cur.rchild ==node return else: queue.append(cur.lchild) queue.append(cur.rchild)
6.1 二叉树
二叉树是每个节点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。
性质:
- 在二叉树的第i层上至多有2^(i-1)个结点(i>0)
- 深度为k的二叉树至多有2^k - 1个结点(k>0)
- 对于任意一棵二叉树,如果其叶结点数为N0,而度数为2的结点总数为N2,则N0=N2+1;
- 具有n个结点的完全二叉树的深度必为 log2(n+1)
- 对完全二叉树,若从上至下、从左至右编号,则编号为i 的结点,其左孩子编号必为2i,其右孩子编号必为2i+1;其双亲的编号必为i/2(i=1 时为根除外)
6.2 二叉树的遍历
深度优先遍历和广度优先遍历,深度优先一般用递归,广度优先一般用队列。
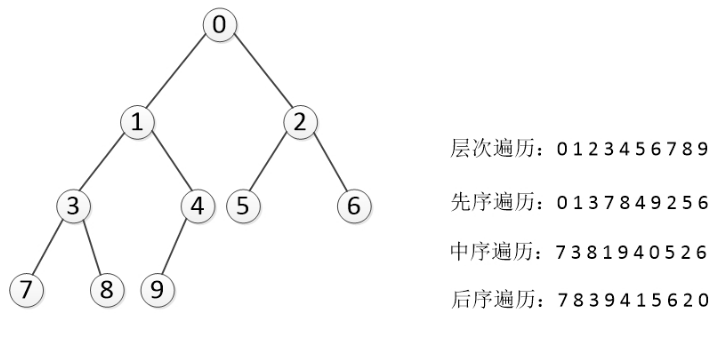
6.2.1 广度遍历(层次遍历)
def breadth_travel(self, root): """利用队列实现树的层次遍历""" if root == None: return queue = [] queue.append(root) while queue: node = queue.pop(0) print (node.elem) if node.lchild != None: queue.append(node.lchild) if node.rchild != None: queue.append(node.rchild)
6.2.2 先序遍历历(preorder)
根节点->左子树->右子树
def preorder(self, root): """递归实现先序遍历""" if root == None: return print (root.elem) self.preorder(root.lchild) self.preorder(root.rchild)
6.2.3 中序遍历(inorder)
左子树->根节点->右子树
def inorder(self, root): """递归实现中序遍历""" if root == None: return self.inorder(root.lchild) print (root.elem) self.inorder(root.rchild)
6.2.4 后序遍历(postorder)
左子树->右子树->根节点
def postorder(self, root): """递归实现后续遍历""" if root == None: return self.postorder(root.lchild) self.postorder(root.rchild) print (root.elem)
ps.有中序遍历和先序遍历或后序遍历可以确定一棵树。
转载于:https://www.cnblogs.com/cirr-zhou/p/9427568.html
- 点赞
- 收藏
- 分享
- 文章举报
 a510396
发布了0 篇原创文章 · 获赞 0 · 访问量 50
私信
关注
a510396
发布了0 篇原创文章 · 获赞 0 · 访问量 50
私信
关注

- Python算法和数据结构(一)——collections模块
- python实现基础的数据结构(二)
- python数据结构(整理)
- Python数据结构——解析树及树的遍历
- 用Python实现数据结构中的单向循环链表
- 基础篇11-python基本数据结构-元组和集合
- python基础语法-python三大内建数据结构之列表(list)
- python数据结构之栈与队列
- Python入门_浅谈数据结构的4种基本类型
- python内置数据结构 - list
- Python学习笔记 - 基本数据结构:元组,列表,字典,集合
- python的第四数据结构-set
- 【Python数据分析】pandas数据结构简介
- python数据结构之Numpy
- Python数据结构之双向链表的定义与使用方法示例
- python教程(二)·数据结构初探
- 简明Python3教程 11.数据结构
- python——python数据结构之栈、队列的实现
- Python数据结构列表list
- Python数据分析 | (2)Python数据结构和序列