《数据密集型应用系统设计》笔记一:第一章 可靠、可扩展与可维护的应用系统
文章目录
1.认识数据系统
1.1 数据密集型 VS 计算密集型
数据密集型侧重于“数据”,关键在于数据量、数据的复杂度及数据的快速多变性。
计算密集型侧重于“运算”,CPU的处理能力往往是关键考量。
1.2 数据密集型应用系统的架构
数据密集型应用通常也是基于各自独立的标准模块构建而成,这些模块有着各自不同的性能特征和设计实现,每个模块负责单一的功能,一般都包含如下五个模块:
数据库、高速缓存、索引、流式处理、批处理。
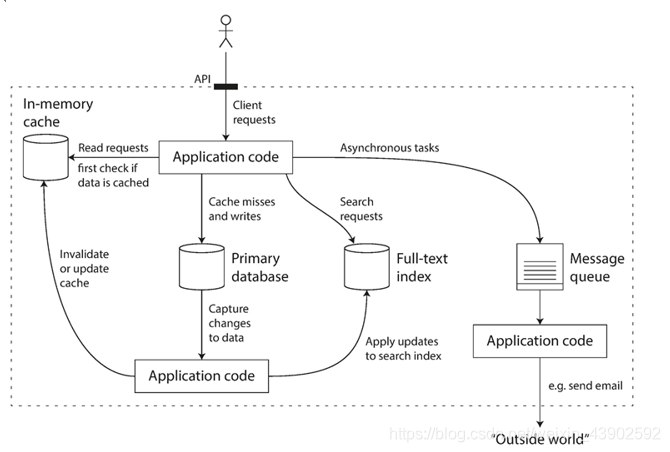
流式处理:关注实时性。kafka,storm,spark streaming,flink等
批处理:关注处理性能,不太要求实时性。MapReduce,spark.
2.可靠性
可靠性意味着:即使发生了某些错误故障,系统仍然可以继续正常工作。
针对不同类型的故障,如何实现可靠性?
硬件故障:冗余。
软件错误:通常认为硬件故障之间是相互独立的,而软件之间的关联非常紧密,错误往往会导致连锁的一连串故障。所以,软件容错的主要目的和方法是:提供足够的冗余信息和算法程序,使系统在实际运行时能够及时发现程序设计错误,及时采取补救措施,以提高软件可靠性,保证整个计算机系统的正常运行。主要的软件容错手段有:恢复快方法,N-版本程序设计,防卫式程序设计。
人为失误:充分的测试,快速完善的恢复机制,细致清晰的监控子系统,包括指标和错误率。
3. 可扩展性
可扩展性是用来描述系统应对负载增加能力的术语。
3.1 描述负载
负载参数:web服务器的每秒请求处理次数,数据库中写入的比例,同时活动用户数量,缓存命中率等。
tweet的例子:
场景:浏览tweet的压力比发布tweet要高出两个数量级。
第一种方法采用传统的关系型数据模型来支持时间线,这种方法在查询时需要查找所有的关注对象(而不管是否发布了tweet),读负载压力很大。根据业务场景,随着用户规模的日益增加,已经不再适合了。优点是写压力小,直接把tweet插入到全局tweet集合即可(无需向关注者发送),只用当关注者读取时才进行合并提取。网络明星红人和普通用户的写入压力是相同的,可以减小写入压力。
第二种方法采用数据流水线方式来推送tweet。它巧妙的转换思路,为了缓解浏览压力,在发布时多做一些事情,采取了一个扇出结构:将tweet发布到每个关注者,用户浏览时无需查找所有tweet集,只需在自己的tweet邮箱中进行查询即可,从而大幅缓解了浏览压力。缺点是增加了发布压力,当某些关注者众多的名人发布tweet时,有很大的写入压力,峰值压力过大。
最后的解决是:两种方法进行混合,广大的普通用户发布tweet就使用第二种方法,红人明星发布tweet就使用第一种方法。
3.2 描述性能
批处理系统中,我们通常关心吞吐量。
在线系统通常更看重服务的响应时间。
平均数指标 VS 百分位数指标
生活的常识使我们知道,平均是个好(坏)东西!它掩盖了许多问题。
对于响应时间,如果想要知道更典型的响应时间,平均值并不是一个合适的指标,它无法告诉有多少用户实际经历了多少延迟。比如有100个响应,其中90个都是100ms响应,其余10个是10s响应,平均下来就是1s左右,如果以此作为响应时间的衡量指标,看起来还能接受。但是用户实际体验到的是10s响应,无法满足需求。
如果用百分位数指标,比如95%分位数,则得到95分位数响应时间是10s,技术人员就知道性能出了问题,需要改进了。
百分位数通常用于描述、定义服务质量目标(Service Level Objectives,SLO)和服务质量协议(Service Level Agreements, SLA),这些是规定服务预期质量和可用性的合同。
3.3 应对负载增加的方法
具体问题具体分析。
超大规模的系统往往针对特定应用而高度定制,很难有一种通用的架构。背后取舍因素包括数据读取量、写入量、待存储的数据量、数据的复杂度、响应时间要求、访问模式等,或者更多的是上述所有因素的叠加,再加上其他更复杂的问题。
垂直扩展 VS 水平扩展
垂直扩展:升级到更强大的机器。传统做法,优点是简单,缺点是局限性太大,成本过高还无法解决问题,大数据时代随着数据量和负载的急剧膨胀,不适用。
水平扩展:将负载分散到多个更小的机器。优点是便宜,高可用,更能适应大数据时代的要求,是当前和未来的必然选择。缺点是结构部署复杂,协调调度难度增大,相对于简单的垂直扩展,分布式的水平扩展产生了一系列新的问题。
4. 可维护性
众所周知(无人关心),软件的大部分成本并不在最初的开发阶段,而是在于整个生命周期内的持续投入。我们可以从软件设计时开始考虑,尽可能较少维护期间的麻烦。为此,我们需要特别关注软件系统的三个设计原则:
可运维性:方便运营团队来保持系统平稳运行。
简单性:简化系统复杂性。简化系统设计并不意味着减少系统功能,而主要意味着消除意外方面的复杂性。Moseley和Marks把复杂性定义为一种“意外”,即它并非软件固有、被用户所见或感知,而是实现本身所衍生出来的问题。复杂性是可以消除的,最好手段之一就是“抽象”。
可演化性:后续工程师能够轻松地对系统进行改进,并根据需求变化将其适配到非典型场景。可以理解为“敏捷开发”。
- 点赞
- 收藏
- 分享
- 文章举报
 喵帕斯日常大王
发布了4 篇原创文章 · 获赞 1 · 访问量 81
私信
关注
喵帕斯日常大王
发布了4 篇原创文章 · 获赞 1 · 访问量 81
私信
关注

- 设计数据密集型应用笔记1:可靠 可扩展可维护的应用
- 《数据密集型应用系统设计》笔记二:第二章 数据模型与查询语言
- 《数据密集型应用系统设计》笔记四:第四章 数据编码与演化
- 《数据密集型应用系统设计》笔记三:第三章 数据存储与检索
- 《华油能源OA系统数据同步和扩展的设计与实现_张宇峰》阅读笔记
- 可靠的、可扩展的、可维护的数据系统 ------《Designing Data-Intensive Applications》读书笔记1
- 设计数据密集型应用第一部分:数据系统的基石
- 设计数据密集型应用:分布式系统的机遇与挑战
- 可靠的、可扩展的、可维护的数据系统 ------《Designing Data-Intensive Applications》读书笔记1...
- 基于RBAC模型的通用权限管理系统的设计(数据模型)的扩展
- 中央电视台硬盘播出系统的扩展应用与维护经验(mxf 格式)
- 基于usb的数据采集系统设计 学习笔记一
- 系统分析与设计--学习笔记4(建模应用)
- 系统设计与架构笔记:键值对在架构设计里的应用
- (笔记)电路设计(十二)之高速数字系统滤波电容的设计应用
- 设计数据密集型应用-第四章-编码和应用演进 (涉及的问题和方案)
- 分布式系统概念与设计-第一章笔记
- 数据密集型系统架构设计
- 基于云计算和大数据的图书馆 应用系统建设设计
- 基于RBAC模型的通用权限管理系统的设计(数据模型)的扩展