python爬虫数据库 --关于Mongodb数据库语法
Mongodb数据库
一、MongoDB简介
二、MongoDB基础增删改查操作
1、增:insert方法
2、删除:remove
3、更新:update
4、查: find
5、查询表达式:
三、游标操作
四、索引创建
1、btree索引
2、hash索引
3、常用命令:
五、MongoDB数据的导入导出
1、通用选项:
2、mongoexport 导出json格式的文件
3、Mongoimport 导入
4、mongodump 导出二进制bson结构的数据及其索引信息
5、mongorestore 导入二进制文件
六、replaction复制集
一、MongoDB简介
|SQL术语/概念 | MongoDB术语/概念 |解释/说明
|-database-|-database-|数据库
|table | collection |数据库表/集合
|row|document|数据记录行/文档
| column | field |数据字段/域
| index | index | 索引
| table joins | | 表连接, MongoDB不支持
| primary key | primary key | 主键, MongoDB自动将_id字段设置为主键
1、mongodb 文档数据库,存储的是文档(Bson->json的二进制化).
{name:‘zhangsan’,age:‘9’}
2、MongoDB特点:内部执行引擎为JS解释器, 把文档存储成bson结构,在查询时,转换为JS对象,并可以通过熟悉的js语法来操作.
2、mongo和传统型数据库相比,最大的不同:
传统型数据库: 结构化数据, 定好了表结构后,每一行的内容,必是符合表结构的,就是说–列的个数,类型都一样.
mongo文档型数据库: 集合中存储的每篇文档,都可以有自己独特的结构(json对象都可以有自己独特的属性和值)
mongo数据库的collection不用提前创建(可以隐式创建。)。关系型数据库的表必须提前创建
3、mongodb数据库bin目录下的文件意义
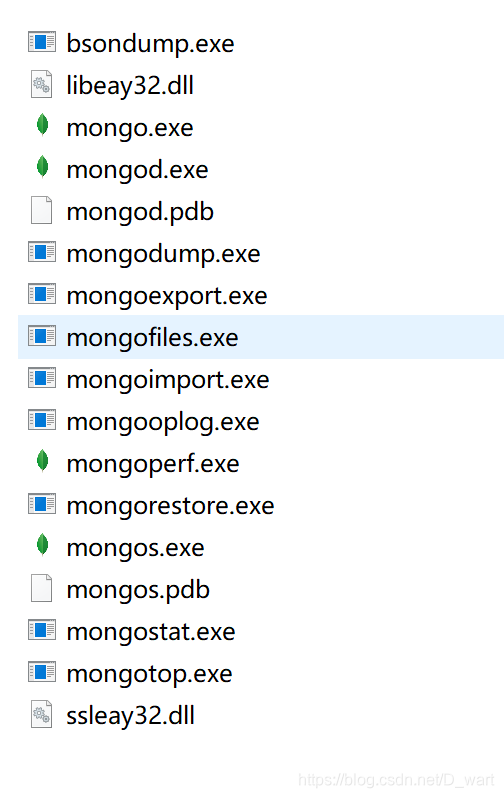
bsondump.exe :导出bsondump结构
mongo.exe:客户端—开启一个客户端,连接指定服务,crud
mongod.exe:服务端–开启一个mongo服务器
mongodump.exe:整体数据库导出(备份工具)
mongoexport.exe:导出易识别的json文档
mongofiles.exe:GridFS工具,内建的分布式文件系统
mongoimport.exe:数据导入程序
mongorestore.exe:数据恢复工具
mongos.exe:路由器(分片时使用)
mongostat.exe:监视程序
4、mongo入门命令
show dbs 查看当前的数据库
use databaseName 选库
show collections 查看当前库下的collection,show tables
如何创建库?
Mongodb的库是隐式创建,你可以use 一个不存在的库,然后在该库下创建collection,即可创建库
use dbname —ues一个不存在的库
db.createCollection(‘collectionName’) —在该库下面创建集合,就可以创建一个数据库
即可创建一个集合。
其实在MongoDB中,collection也是可以隐身创建的
db.collectionName.insert(document)
如何删除数据库和集合?
db.collectionName.drop()//删除集合
db.dropDatabase()//删除数据库
二、MongoDB基础增删改查操作
1、增:insert方法
首先要明确一点,MongoDB存储的时文档,文档其实就是json格式的对象。
语法:
db.collectionName.insert(document)
增加单篇文档:
db.collectionName.insert({title:’nice day’})
增加单个文档,并指定_id
db.collectionName.insert({_id:8,age:78,name:’lisi’})
增加多个文档
db.collectionName.insert(
[
{time:‘friday’,study:‘mongodb’},
{_id:9,gender:‘male’,name:‘QQ’}
]
)
2、删除:remove
语法:
db.collection.remove(查询表达式, 选项)
选项是指 {justOne:true/false},是否只删一行, 默认为false
注意:
1: 查询表达式依然是个json对象 {age:20}
2: 查询表达式匹配的行,将被删掉.
3: 如果不写查询表达式,collections中的所有文档将被删掉
例1:删除stu表中 sn属性值为’001’的文档
db.stu.remove({sn:’001’})
例2: 删除stu表中gender属性为m的文档,只删除1行.
db.stu.remove({gender:’m’,true});
3、更新:update
语法: db.collection.update(查询表达式,新值,选项)
改谁? — 查询表达式
改成什么样? – 新值 或 赋值表达式
操作选项 ----- 可选参数
例:
db.news.update({name:‘QQ’},{name:‘MSN’});
是指选中news表中,name值为QQ的文档,并把其文档值改为{name:’MSN’},结果: 文档中的其他列也不见了,改后只有_id和name列了,即–新文档直接替换了旧文档,而不是修改
如果是想修改文档的某列,可以用KaTeX parse error: Expected '}', got 'EOF' at end of input: ….update(query,{set:{name:’QQ’}})
修改时的赋值表达式
$set 修改某列的值
$unset 删除某个列
$rename 重命名某个列
KaTeX parse error: Expected '}', got 'EOF' at end of input: …ame:'wuyong'},{set:{name:‘junshiwuyong’}},{upsert:true});
如果有name=’wuyong’的文档,将被修改,如果没有,将添加此新文档
db.news.update({_id:99},{x:123,y:234},{upsert:true});
没有_id=99的文档被修改,因此直接插入该文档
multi: 是指修改多行(即使查询表达式命中多行,默认也只改1行,如果想改多行,可以用此选项)
db.news.update({age:21},{$set:{age:22}},{multi:true});
则把news中所有age=21的文档,都修改
4、查: find
语法: db.collection.find(查询表达式,查询的列);
db.collections.find(表达式,{列1:1,列2:1});
在查询的列参数中,1表示显示,0表示不显示
例1:db.stu.find()
查询所有文档 所有内容
例2: db.stu.find({},{gendre:1})
查询所有文档,的gender属性 (_id属性默认总是查出来)
例3: db.stu.find({},{gender:1, _id:0})
查询所有文档的gender属性,且不查询_id属性
例4: db.stu.find({gender:’male’},{name:1,_id:0});
查询所有gender属性值为male的文档中的name属性
2. MongoDB AND 条件
MongoDB 的 find() 方法可以传入多个键(key),每个键(key)以逗号隔开,及常规 SQL 的 AND 条件。类似于 WHERE 语句:WHERE by=‘优就业’ AND title='MongoDB 教程。
语法格式如下:
db.col.find({key1:value1, key2:value2}).pretty()
3、常用方法:
limit()
db.COLLECTION_NAME.find().limit(NUMBER)
skip()
db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
sort()
db.COLLECTION_NAME.find().sort({KEY:1})
count()
db.mycol.count()
5、查询表达式:
最简单的查询表达式
{filed:value} ,是指查询field列的值为value的文档
KaTeX parse error: Expected '}', got 'EOF' at end of input: …stu.find({age:{lt:10}},{name:1,age:1})
$lte小于等于
$gt 大于
$gte大于等于
KaTeX parse error: Expected '}', got 'EOF' at end of input: … 查询表达式
{field:{nq:value}} —作用:查filed列的值 不等于 value 的文档
db.goods.find({cat_id:{$nq:3}},{cat_id:1,goods_id:1,goods_name:1,_id:0})
//查询cat_id不等3的数据
KaTeX parse error: Expected '}', got 'EOF' at end of input: …stu.find({age:{nin:[1,16]}})
KaTeX parse error: Expected '}', got 'EOF' at end of input: …u.find({hobby:{all:[‘aa’,‘bb’]}},{name:1,age:1,_id:0})
KaTeX parse error: Expected '}', got 'EOF' at end of input: …ts
语法: {field:{exists:1}}
作用: 查询出含有field字段的文档
db.stu.find({hobby:{$exists:1}})
KaTeX parse error: Expected '}', got 'EOF' at end of input: nor
{nor:[条件1,条件2]} 是指 所有条件都不满足的文档为真返回
KaTeX parse error: Expected '}', got 'EOF' at end of input: and
{and:[条件1,条件2]} 是指 所有条件都满足,就为真
KaTeX parse error: Expected '}', got 'EOF' at end of input: or
{or:[条件1,条件2]} 是指 条件1和条件2有一个满足,就为真
基础查询 where的练习
//主键为32的商品
db.goods.find({goods_id:32});
//不属第3栏目的所有商品(KaTeX parse error: Expected '}', got 'EOF' at end of input: ….find({cat_id:{ne:3}},{goods_id:1,cat_id:1,goods_name:1});
//本店价格高于3000元的商品{KaTeX parse error: Expected 'EOF', got '}' at position 3: gt}̲ db.goods.find(…gt:3000}},{goods_name:1,shop_price:1});
//本店价格低于或等于100元的商品(KaTeX parse error: Expected '}', got 'EOF' at end of input: …d({shop_price:{lte:100}},{goods_name:1,shop_price:1});
//取出第4栏目或第11栏目的商品(KaTeX parse error: Expected '}', got 'EOF' at end of input: ….find({cat_id:{in:[4,11]}},{goods_name:1,shop_price:1});
//取出100<=价格<=500的商品(KaTeX parse error: Expected '}', got 'EOF' at end of input: …db.goods.find({and:[{price:{KaTeX parse error: Expected 'EOF', got '}' at position 7: gt:100}̲,{price:{$lt:500}}}]);
//取出不属于第3栏目且不属于第11栏目的商品($and nin和nin和nin和nor分别实现)
db.goods.find({KaTeX parse error: Expected '}', got 'EOF' at end of input: and:[{cat_id:{ne:3}},{cat_id:{KaTeX parse error: Expected 'EOF', got '}' at position 6: ne:11}̲}]}
,{goods_nam…nin:[3,11]}},{goods_name:1,cat_id:1});
db.goods.find({$nor:[{cat_id:3},{cat_id:11}]},{goods_name:1,cat_id:1});
//取出价格大于100且小于300,或者大于4000且小于5000的商品()
db.goods.find({
$or:[
{
KaTeX parse error: Expected '}', got 'EOF' at end of input: … {shop_price:{gt:100}},
{shop_price:{$lt:300}}
]
},
{
KaTeX parse error: Expected '}', got 'EOF' at end of input: … {shop_price:{gt:4000}},
{shop_price:{$lt:5000}}
]
}
]},{goods_name:1,shop_price:1});
//取出goods_id%5 == 1, 即,1,6,11,…这样的商品
db.goods.find({goods_id:{$mod:[5,1]}});
//取出有age属性的文档
db.stu.find({age:{$exists:1}});
含有age属性的文档将会被查出
6、MongoDB 聚合(db.col.aggregate())
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的 count(*)。
语法:
db.COLLECTION_NAME.aggregate(
[
{管道1},
{管道2},
{管道3},
…
]
)
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理,管道操作是可以重复的。
聚合框架中常用的几个管道操作:
$project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
match:用于过滤数据,只输出符合条件的文档。match:用于过滤数据,只输出符合条件的文档。match:用于过滤数据,只输出符合条件的文档。match使用MongoDB的标准查询操作。
$limit:用来限制MongoDB聚合管道返回的文档数。
$skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
$group:将集合中的文档分组,可用于统计结果。
$sort:将输入文档排序后输出。
group中的一下操作表达式:
表达式
描述
$sum
计算总和。
$avg
计算平均值
$min
获取集合中所有文档对应值得最小值。
$max
获取集合中所有文档对应值得最大值。
$first
根据资源文档的排序获取第一个文档数据。
KaTeX parse error: Expected '}', got 'EOF' at end of input: …aggregate(); [{group:{_id:“KaTeX parse error: Expected '}', got 'EOF' at end of input: cat_id",total:{sum:1}}}]
2.查询goods下有多少条商品
db.goods.aggregate([{KaTeX parse error: Expected '}', got 'EOF' at end of input: …id:null,total:{sum:1}}}])
3.查询每个栏目下价格大于50元的商品个数
db.goods.aggregate([{KaTeX parse error: Expected '}', got 'EOF' at end of input: …h:{shop_price:{gt:50}}}, {KaTeX parse error: Expected '}', got 'EOF' at end of input: group:{_id:"cat_id”,total:{KaTeX parse error: Expected 'EOF', got '}' at position 6: sum:1}̲}}])
4.查询每个栏目下的…group:{_id:"KaTeX parse error: Expected '}', got 'EOF' at end of input: …t_id" , total:{sum:“KaTeX parse error: Expected 'EOF', got '}' at position 14: goods_number"}̲}}])
5.查询每个栏目下 …match:{shop_price:{KaTeX parse error: Expected 'EOF', got '}' at position 6: gt:50}̲}}
(2)要想查出个数大于3…group:{_id:“KaTeX parse error: Expected '}', got 'EOF' at end of input: cat_id",total:{sum:1}}}
(3)最后用match来去除大于3个的栏目
{KaTeX parse error: Expected '}', got 'EOF' at end of input: match:{total:{gte:3}}}
6.查询每个栏目下的库存量,并按库存量排序
思路:
(1)按栏目的库存量分组(2)排序
{KaTeX parse error: Expected '}', got 'EOF' at end of input: group:{_id:"cat_id” , total:{sum:"sum:"sum:"goods_number”}}}
{KaTeX parse error: Expected 'EOF', got '}' at position 15: sort:{total:1}}̲
db.goods.aggre…group:{_id:“KaTeX parse error: Expected '}', got 'EOF' at end of input: …t_id" , total:{sum:“KaTeX parse error: Expected 'EOF', got '}' at position 14: goods_number"}̲}}, {sort:{total:1}}])
1是正序,-1是逆序
7.查询每个栏目的商品平均价格,并按平均价格由高到低排序
db.goods.aggregate([{KaTeX parse error: Expected '}', got 'EOF' at end of input: group:{_id:"cat_id”,avg:{avg:"avg:"avg:"shop_price”}}},{$sort:{avg:-1}}])
三、游标操作
前面给大家讲过,MongoDB在底层上时用js来实现的,所以我们可以通过以下代码,在数据库中插入1000条数据。
for (var i=0;i<1000;i++){
db.bar.insert({_id:i+1,title:‘hello world’+i,content:‘aaa’+i})
}
我们可以看出,上面就是js的for循环代码。所以在MongoDB中可以将js代码和我们的数据库做操作指令一起配合来使用。
如果数据库中很多数据,比如刚刚插入的1000条,我们执行以下命令:
db.bar.find()
他会将所有的数据都查询出来给我们,此时我们考虑是否能让我们在查询的时候,像python中生成器那样,每次给我们返回一个数据。其实在MongoDB中也有类似生成器这样的东东,他叫游标
1、游标是什么?
mongo的游标相当于python中的迭代器。通过将查询结构定义给一个变量,这个变量就是游标。通过这个游标,我们可以每次获取一个数据。
2、游标的声明:
var curor_name = db.bar.find()
3、游标的操作:
curor.hasNext()//判断游标是否已经取到尽头,|true表示没有到尽头。
curor.next()//取出游标的下一个单元
例如:
var mycusor = db.bar.find().limit(5)
print(mycusor.next())//会显示是一个bson格式的数据
printjson(mycusor.next())
我们可以写一个while循环来打印游标结果:
while(mycusor.hasNext()){
printjson(mycusor.next())
}
游标还有一个toArray()方法,方便我们可以看到所有行
print(mycusor.toArray())//看到所有行
print(mycusor.toArray()[2])//看到第二行
注意不要使用toArray(),原因是会把所有的行立即以对象的形式放在内存中,可以再取出少数几行时,使用此功能。
4、cursor.forEach(回调函数)
var gettile = function(obj){print(obj.goods_name)}
var cursor = db.goods.find()
cursor.forEach(gettile)
5、游标在分页中的应用
一般的,我们假设每页N行,当前是page页,就需要跳过(page-1)*N,再取N行,在mysql中,用limit,offset,N来实现,在MongoDB中,用skip(),limit()函数来实现。
var mycusor = db.bar.find().skip(90).limit(10)//跳过90条,取10条。
var mycursor = db.bar.find().skip(9995);
则是查询结果中,跳过前9995行
查询第901页,每页10条
则是 var mytcursor = db.bar.find().skip(9000).limit(10);
四、索引创建
索引提高查询速度,降低写入速度,[权衡常用的查询字段,不必在太多列上建索引]
在mongodb中,索引可以按字段升序/降序来创建,便于排序
默认是用btree来组织索引文件,2.4版本以后,也允许建立hash索引
常用命令:
(1)查看当前索引状态:db.collection.getIndexes()
(2)创建普通单列索引:db.collection.ensureIndex({field:1/-1})//1为正序,-1为逆序
(3)删除单个索引:db.collection.dropIndex({field:1/-1})
(4)删除所有索引:db.collection.dropIndexes()
_id所在的列的索引不能删除。
(5)创建多列索引:db.collection.ensureIndex({field1:1/-1,field2:1/-1})
多列索引的使用范围更广,因为一般情况下,我们都是通过多个字段来进行查询数据的,这时候单列索引其实用不到。
两个列一起建立索引其实就是将两个列绑定到一起,来创建索引
(6)子文档索引:
子文档查询:
1.插入两条带子文档的数据
db.shop. insert({name: ‘N0kia’ , SPC: {weight: 120 , area: ’ taiwan ’ } } ) ;
db.shop. insert({name: 'sanxing ’ , SPC :{weight: 100 , area: ‘hanguo’} } ) ;
2.查询出产地在台湾的手机
db.shop.find({‘spc.area’:‘taiwan’})
给子文档加索引:
db.shop.ensureIndex({‘spc.area’:1})//子文档就点就可以了
(7) 唯一索引:{unique:true}
db.collection.ensureIndex({field:1/-1},{unique:true})
唯一索引的列不能重复插入
(8)hash索引:
db.collection.ensureIndex({field:‘hashed’})
五、MongoDB数据的导入导出
1、通用选项:
导入/导出可以操作的是本地的mongodb服务器,也可以是远程的.
所以,都有如下通用选项:
-h host 主机
–port port 端口
-u username 用户名
-p passwd 密码
2、mongoexport 导出json格式的文件
-d 库名
-c 表名
-f field1,field2…列名
-q 查询条件
-o 导出的文件名
–type csv 导出csv格式(便于和传统数据库交换数据)
例1:
mongoexport -d test -c news -o test.json
例2: 只导出goods_id,goods_name列
mongoexport -d test -c goods -f goods_id,goods_name -o goods.json
例3: 只导出价格低于1000元的行
mongoexport -d test -c goods -f goods_id,goods_name,shop_price -q ‘{shop_price:{$lt:200}}’ -o goods.json
注: _id列总是导出
当初csv文件的时候,需要制定到处哪些列。
mongoexport -d shop -c goods -o goods.csv --type csv -f goods_id,cat_id,goods_name,shop_price
3、Mongoimport 导入
-d 待导入的数据库
-c 待导入的表(不存在会自己创建)
–file 备份文件路径
例1: 导入json
mongoimport -d test -c goods --file ./goodsall.json
例2: 导入csv
mongoimport -d test -c goods --type csv -f goods_id,goods_name --file ./goodsall.csv
4、mongodump 导出二进制bson结构的数据及其索引信息
-d 库名
-c 表名
mongodum -d test [-c 表名] 默认是导出到mongo下的dump目录
规律:
导出的文件放在以database命名的目录下
每个表导出2个文件,分别是bson结构的数据文件, json的索引信息
如果不声明表名, 导出所有的表
5、mongorestore 导入二进制文件
mongorestore -d shop -c goods --dir ./dump/shop/goods.bson
二进制备份,不仅可以备份数据,还可以备份索引,备份数据比较小.速度比较快。
六、replaction复制集
一般情况下,我们通常在机器上安装了一个数据库,这是我们的数据都是存在这个数据库中的,如果有一天,因为一些不可控因素导致数据库宕机或者数据库的文件丢失,此时损失就很大了。针对于这种问题,我们希望有一个数据库集,在我们其中一个数据库进行插入的时候,其他数据库也能插入数据,这样其中一台服务器宕机了,也能够使我们的数据正常存取。
在MongoDB中,是通过replaction复制集来实现此功能的。
在Windows下实现复制集的方法:
创建复制集之前,把所有的mongo服务器都关掉
1、创建三个存储数据库的文件夹,用来保存数据文件
2、打开三个cmd窗口,分别启动三个mongodb
mongod --dbpath C:\MongoDB\Server\3.4\data\m1 --logpath C:\MongoDB\Server\3.4\data\logs\mongo1.log --port 27017 --replSet rs
mongod --dbpath C:\MongoDB\Server\3.4\data\m2 --logpath C:\MongoDB\Server\3.4\data\logs\mongo2.log --port 27018 --replSet rs
mongod --dbpath C:\MongoDB\Server\3.4\data\m3 --logpath C:\MongoDB\Server\3.4\data\logs\mongo3.log --port 27019 --replSet rs
其中的–replSet就表示创建的数据集的名称,必须指定相同的名称才可以。
3、配置
var rsconf = {
_id:‘rs’,
members:[
{_id:0,host:‘127.0.0.1:27017’},
{_id:1,host:‘127.0.0.1:27018’},
{_id:2,host:‘127.0.0.1:27019’}
]
}
这时候我们可以打印rsconf来看一下
printjson(rsconf)
接下来需要将配置初始化
rs.initiate(rsconf)
现在我们看到,现在登录客户端已经不是哪台机器,而是rs复制集

我们在主机上插入一条数据,再从机上必须输入rs.slaveOk()之后才能被允许查看数据
5、删除复制集
rs.remove(‘127.0.0.1:27019’)
删除节点后,如果想再添加,必须重新配置才可以。
var rsconf = {
_id:‘rs’,
members:[
{_id:0,host:‘127.0.0.1:27017’},
{_id:1,host:‘127.0.0.1:27018’},
{_id:2,host:‘127.0.0.1:27019’}
]
}
在输入:rs.reconfig(rsconf)
在输入rs.status(),可以看到数据集现在又是三个了。
- 点赞
- 收藏
- 分享
- 文章举报
 D_dalei
发布了48 篇原创文章 · 获赞 22 · 访问量 1607
私信
关注
D_dalei
发布了48 篇原创文章 · 获赞 22 · 访问量 1607
私信
关注

- 关于Python爬虫之获取海量表情包+存入数据库+搭建网站通过关键字查询表情包
- 关于Python爬虫爬淘宝mm详细教程+存入数据库
- 关于Python爬虫无数据库的存储1之存储为csv格式
- python关于链家网房子的一次爬虫
- 关于Python爬虫程序scrapy的安装问题
- 【脚本语言系列】关于Python数据库编程ODBC,你需要知道的事
- 【脚本语言系列】关于Python数据库访问DAO, 你需要知道的事
- Python爬虫:Xpath语法笔记
- Python爬虫番外篇之关于登录
- python 爬虫爬取几十家门店在美团外卖上的排名,并插入数据库,最后在前端显示
- 关于python的基础知识15 -- 语法错误和异常
- Python程序员关于爬虫的一些常见面试题
- Python语法基础——关于全局变量与局部变量
- 关于python爬虫的编码错误
- Python语法基础——关于全局变量与局部变量
- Python爬虫利器三之Xpath语法与lxml库的用法
- python 爬虫抓豆瓣电影,并存入数据库
- 【脚本语言系列】关于PythonNoSQL数据库处理memcached,你需要知道的事
- python一个关于贴吧的小爬虫(二)
- 关于Python 3.x爬虫爬取某些网站资源时,碰到UnicodeDecodeError: 'utf-8' codec can‘t......的解决办法