Spark 小文件合并优化实践
文章目录
对 spark 任务数据落地(HDFS) 碎片文件过多的问题的优化实践及思考。
背景
此文是关于公司在 Delta Lake 上线之前对Spark任务写入数据产生碎片文件优化的一些实践。
-
形成原因
shuffle 分区过多过碎,写入性能会较差且生成的小文件会非常多。
数据在流转过程中经历 filter/shuffle 等过程后,开发人员难以评估作业写出的数据量。即使使用了 Spark 提供的AE功能,目前也只能控制 shuffle read 阶段的数据量,写出数据的大小实际还会受压缩算法及格式的影响,因此在任务运行时,对分区的数据评估非常困难。 - shuffle 分区过少过大,则写入并发度可能会不够,影响任务运行时间。
不利影响
在产生大量碎片文件后,任务数据读取的速度会变慢(需要寻找读入大量的文件,如果是机械盘更是需要大量的寻址操作),同时会对 hdfs namenode 内存造成很大的压力。
在这种情况下,只能让业务/开发人员主动的合并下数据或者控制分区数量,提高了用户的学习及使用成本,往往效果还非常不理想。
既然在运行过程中对最终落地数据的评估如此困难,是否能将该操作放在数据落地后进行?对此我们进行了一些尝试,希望能自动化的解决/缓解此类问题。
一些尝试
大致做了这么一些工作:
- 修改 Spark FileFormatWriter 源码,数据落盘时,记录相关的 metrics,主要是一些分区/表的记录数量和文件数量信息。
- 在发生落盘操作后,会自动触发碎片文件检测,判断是否需要追加合并数据任务。
- 实现一个 MergeTable 语法用于合并表/分区碎片文件,通过系统或者用户直接调用。
第1和第2点主要是平台化的一些工作,包括监测数据落盘,根据采集的 metrics 信息再判断是否需要进行 MergeTable 操作,下文是关于 MergeTable 的一些细节实现。
MergeTable
功能:
- 能够指定表或者分区进行合并
- 合并分区表但不指定分区,则会递归对所有分区进行检测合并
- 指定了生成的文件数量,就会跳过规则校验,直接按该数量进行合并
语法:
merge table [表名] [options (fileCount=合并后文件数量)] --非分区表 merge table [表名] PARTITION (分区信息) [options (fileCount=合并后文件数量)] --分区表
碎片文件校验及合并流程图:

性能优化
对合并操作的性能优化
-
只合并碎片文件
如果设置的碎片阈值是128M,那么只会将该表/分区内小于该阈值的文件进行合并,同时如果碎片文件数量小于一定阈值,将不会触发合并,这里主要考虑的是合并任务存在一定性能开销,因此允许系统中存在一定量的小文件。 -
分区数量及合并方式
定义了一些规则用于计算输出文件数量及合并方式的选择,获取任务的最大并发度 maxConcurrency 用于计算数据的分块大小,再根据数据碎片文件的总大小选择合并(coalesce/repartition)方式。-
开启 dynamicAllocation
maxConcurrency = spark.dynamicAllocation.maxExecutors * spark.executor.cores
- 未开启 dynamicAllocation
maxConcurrency = spark.executor.instances * spark.executor.cores
-
修复元数据
因为 merge 操作会修改数据的创建及访问时间,所以在目录替换时需要将元数据信息修改到 merge 前的一个状态,该操作还能避免冷数据扫描的误判。最后还要调用 refresh table 更新表在 spark 中的状态缓存。 -
commit 前进行校验
在最终提交前对数据进行校验,判断合并前后数据量是否发生变化(从数据块元数据中直接获取数量,避免发生IO),存在异常则会进行回滚,放弃合并操作。
以几个场景为例对比优化前后的性能:
场景1:最大并发度100,碎片文件数据100,碎片文件总大小100M,如果使用 coalesce(1),将会只会有1个线程去读/写数据,改为 repartition(1),则会有100个并发读,一个线程顺序写。性能相差100X。
场景2:最大并发度100,碎片文件数量10000,碎片文件总大小100G,如果使用 repartition(200),将会导致100G的数据发生 shuffle,改为 coalesce(200),则能在保持相同并发的情况下避免 200G数据的IO。
场景3:最大并发度200,碎片文件数量10000,碎片文件总大小50G,如果使用 coalesce(100),会保存出100个500M文件,但是会浪费一半的计算性能,改为 coalesce(200),合并耗时会下降为原来的50%。
上述例子的核心都是在充分计算资源的同时避免不必要的IO。
数据写入后,自动合并效果图:
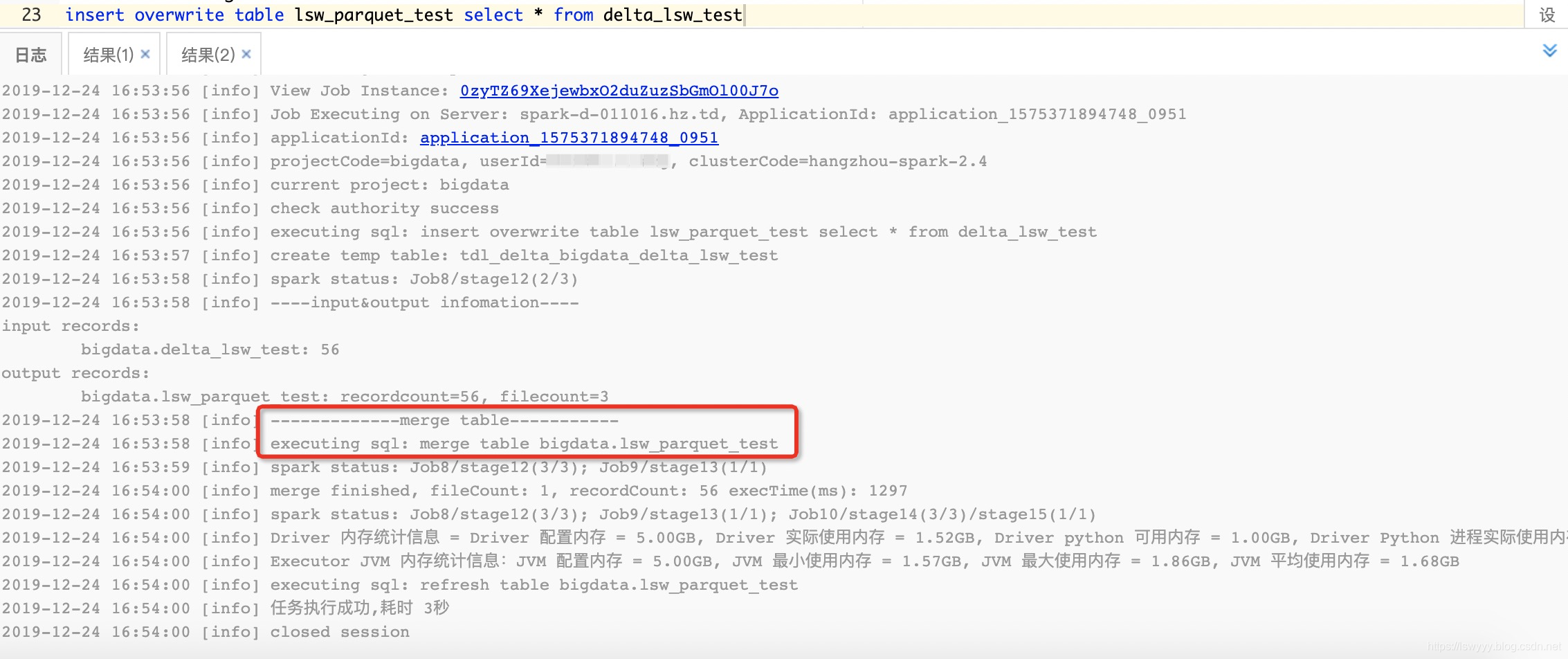
后记
收益
该同步合并的方式已经在我们的线上稳定运行了1年多,成功的将平均文件大小从150M提升到了270M左右,提高了数据读取速度,与此同时 Namenode 的内存压力也得到了极大缓解。
对 MergeTable 操作做了上述的相关优化后,根据不同的数据场景下,能带来数倍至数十倍的性能提升。
缺陷
因为采用的是同步合并的方式,由于没有事务控制,所以在合并过程中数据不可用,这也是我们后来开始引入 Delta Lake 的一个原因。
- 点赞 4
- 收藏
- 分享
- 文章举报
 breeze_lsw
博客专家
发布了129 篇原创文章 · 获赞 180 · 访问量 70万+
他的留言板
关注
breeze_lsw
博客专家
发布了129 篇原创文章 · 获赞 180 · 访问量 70万+
他的留言板
关注

- spark实现hive的合并输入很多小文件为指定大小的大文件的优化功能
- hive优化之自动合并输出的小文件
- Web性能优化之动态合并JS/CSS文件并缓存客户端
- 服务器端文件分片合并的思考和实践
- [前端优化]使用Combres合并对js、css文件的请求
- hadoop mapreduce开发实践文件合并(join)
- Spark Streaming实践和优化
- [转][前端优化]使用Combres合并对js、css文件的请求
- 服务器端文件分片合并的思考和实践
- python spark中parquet文件写到hdfs,同时避免太多的小文件(block小文件合并)
- 数据库优化实践【文件、文件组、分区篇】
- [前端优化]使用Combres合并对js、css文件的请求
- Spark小文件合并
- Spark:spark df插入hive表后小文件数量多,如何合并?
- 用python合并N个不同字符集编码的sql文件的实践
- 用python合并N个不同字符集编码的sql文件的实践
- [前端优化]使用Combres合并对js、css文件的请求
- 《Python编程快速上手》实践项目:将多个pdf文件内容合并为一个pdf,并去除首页
- 数据库优化实践【文件、文件组、分区篇】
- 黄洁:Intel Spark应用优化和实践经验