常见的五种神经网络(4)-深度信念网络(下)篇之深度信念网络的原理解读、参数学习
该系列的其他文章:
- 常见的五种神经网络(1)-前馈神经网络
- 常见的五种神经网络(2)-卷积神经网络
- 常见的五种神经网络(3)-循环神经网络(上篇)
- 常见的五种神经网络(3)-循环神经网络(中篇)
- 常见的五种神经网络(3)-循环神经网络(下篇)
- 常见的五种神经网络(4)-深度信念网络(上篇)
- 常见的五种神经网络(4)-深度信念网络(下篇)
- 常见的五种神经网络(5)-生成对抗网络
在上一篇文章中介绍了玻尔兹曼机和受限玻尔兹曼机(阅读详情),这篇文章中介绍一下深度信念网络。
深度信念网络介绍
深度信念网络(Deep Belief Netword, DBN)是一种深层的概率有向图模型,其图结构有多层的节点构成。每层节点的内部没有连接,相邻两层的节点之间为全连接。网络的最底层为可观测的变量,其他层节点都为隐变量。最顶部的两层间的连接是无向的,其他层之间的连接是有向的。下图给出了一个深度信念网络的示例。

对一个有LLL层隐变量的深度信念网络,令v=h(0)v=h^{(0)}v=h(0)表示最底层(第0层)为可观测变量,h(1),...,h(L)h^{(1)}, ..., h^{(L)}h(1),...,h(L)表示其余每层的变量。顶部的两层是一个无向图,可以看作是一个受限玻尔兹曼机,用来产生p(h(L−1))p(h^{(L-1)})p(h(L−1))的先验分布。除了最顶上两层外,每一层变量h(l)h^{(l)}h(l)依赖于其上面一层h(l+1)h^{(l+1)}h(l+1),即:
p(h(l)∣h(l+1),...,h(L))=p(h(l)∣h(l+1))
p(h^{(l)} | h^{(l+1)}, ..., h^{(L)}) = p(h^{(l)} | h^{(l+1)})
p(h(l)∣h(l+1),...,h(L))=p(h(l)∣h(l+1))
其中l={0,...,L−2}l=\{0,...,L-2\}l={0,...,L−2}
深度信念网络中所有变量的联合概率可以分解为:
p(v,h(1),...,h(L))=p(v∣h(1))(∏l=1L−2p(h(l)∣h(l+1)))p(h(L−1),h(L))=∏l=0L−1p(h(l)∣h(l+1))p(h(L−1),h(L))
p(v,h^{(1)},...,h^{(L)}) = p(v|h^{(1)})( \prod_{l=1}^{L-2} p(h^{(l)} | h^{(l+1)} ) )p( h^{(L-1)}, h^{(L)})
\\
= \prod_{l=0}^{L-1} p(h^{(l)} | h^{(l+1)} ) p(h^{(L-1)},h^{(L)})
p(v,h(1),...,h(L))=p(v∣h(1))(l=1∏L−2p(h(l)∣h(l+1)))p(h(L−1),h(L))=l=0∏L−1p(h(l)∣h(l+1))p(h(L−1),h(L))
其中p(hl∣h(l+1))p(h^{l} | h^{(l+1)})p(hl∣h(l+1))为sigmoid型条件概率分布为:
p(h(l)∣h(l+1))=σ(a(l)+W(l+1)h(l+1))
p(h^{(l)} | h^{(l+1)}) = \sigma (a^{(l)}+W^{(l+1)} h^{(l+1)})
p(h(l)∣h(l+1))=σ(a(l)+W(l+1)h(l+1))
其中σ(.)\sigma(.)σ(.) 为按位计算的logistic sigmoid函数,a(l)a^{(l)}a(l)为偏置参数,W(l+1)W^{(l+1)}W(l+1)为权重参数。这样,每一个层都可以看作是一个Sigmoid信念网络。
生成模型
DBN是一个生成模型,可以用来生成符合特定分布的样本。隐变量用来描述在可观测变量之间的高阶相关性。假如训练数据服从分布p(v)p(v)p(v),通过训练得到一个深度信念网络。
在生成样本时,首先在最顶两层进行足够多次的吉布斯采样,生成h(L−1)h^{(L-1)}h(L−1),然后依次计算下一层隐变量的分布。因为在给定上一层变量取值时,下一层的变量是条件独立的,因为可以独立采样。这样我们就可以从第L−1L-1L−1层开始,自顶向下进行逐层采样,最终得到可观测层的样本。
参数学习
DBN最直接的训练方式可以通过最大似然方法使得可观测变量的边际分布p(v)p(v)p(v)在训练集合上的似然达到最大。但在深度信念网络中,隐变量hhh之间的关系十分复杂,由于“贡献度分配问题”,很难直接学习。即使对于简单的单层Sigmoid信念网络
p(v=1∣h)=σ(b+wTh)
p(v=1 | h) = \sigma (b + w^Th)
p(v=1∣h)=σ(b+wTh)
在已知可观察变量时,其隐变量的联合后验概率p(h∣v)p(h|v)p(h∣v)不再相互独立,因此很难精确估计所有隐变量的后验概率。早起深度信念网络的后验概率一般通过蒙特卡洛方法或变分方法来近似估计,但是效率比较低,而导致其参数学习比较困难。
为了有效地训练深度信念网络,我们将每一层的Sigmoid信念网络转换为受限玻尔兹曼机。这样做的好处是隐变量的后验概率是相互独立的,从而可以很容易地进行采样。这样,深度信念网络可以看作是由多个受限玻尔兹曼机从上到下进行堆叠,第lll层受限玻尔兹曼机的隐层作为第l+1l+1l+1层受限玻尔兹曼机可观测层。进一步地,深度信念网络可以采用逐层训练的方式来快速训练,即从最底层开始,每次只训练一层,直到最后一层。
深度信念网络的训练过程可以分为预训练和精调两个阶段。先通过逐层预训练将模型的参数初始化为较优的值,再通过传统学习方法对参数进行精调。
逐层预训练
在预训练阶段,采用逐层训练的方式,将深度信念网络的训练简化为多个玻尔兹曼机的训练。下图给出了深度信念网络的逐层预训练过程。
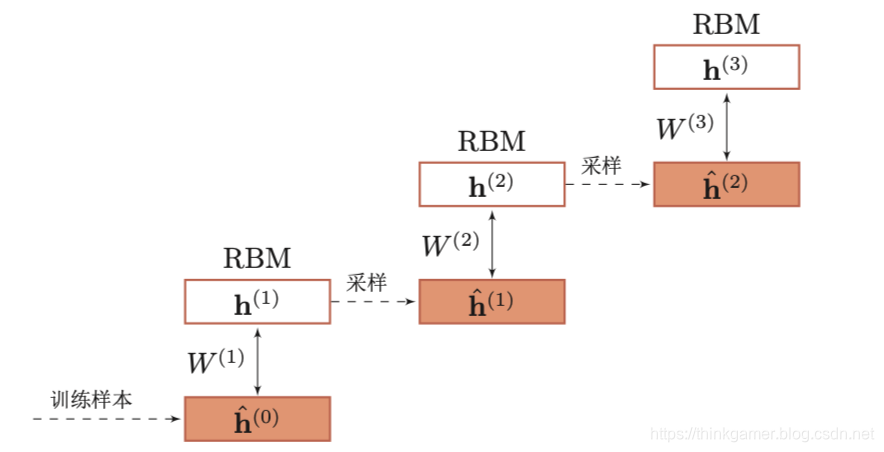
具体的逐层训练过程为自下而上依次训练每一层的受限玻尔兹曼机。假设我们已经训练好了前l−1l-1l−1层的受限玻尔兹曼机,那么可以计算隐变量自下而上的条件概率
p(h(i)∣h(i−1))=σ(b(i)+W(i)h(i−1)),1≤i≤(l−1)
p(h^{(i)} | h^{(i-1)}) = \sigma( b^{(i)} + W^{(i) h^{(i-1)}} ), 1 \leq i \leq (l-1)
p(h(i)∣h(i−1))=σ(b(i)+W(i)h(i−1)),1≤i≤(l−1)
其中b(i)b^{(i)}b(i)为第iii层受限玻尔兹曼机的偏置,W(i)W^{(i)}W(i)为连接权重。这样,可以按照 v=h(0)−>h(1)−>...−>h(l−1)v=h^{(0)} -> h^{(1)} -> ... -> h^{(l-1)}v=h(0)−>h(1)−>...−>h(l−1)的顺序生成一组h(l−1)h^{(l-1)}h(l−1)的样本,记为H^(l−1)=h^(l,1),...,h^(l,M)\hat{H} ^{(l-1)} = {\hat{h}^{(l,1)}, ..., \hat{h}^{(l,M)} }H^(l−1)=h^(l,1),...,h^(l,M)。然后将h(l−1)h^{(l-1)}h(l−1)和h(l)h^{(l)}h(l)组成一个受限玻尔兹曼机,用H^(l−1)\hat{H}^{(l-1)}H^(l−1)作为训练集充分训练第lll层的受限玻尔兹曼机。
下图的算法流程给出了一种深度信念网络的逐层预训练方法。大量的实践表明,逐层预训练可以产生非常好的参数初始值,从而极大的降低了模型的学习难度。

精调
经过预训练之后,再结合具体的任务(监督学习或无监督学习),通过传统的全局学习算法对网络进行精调(fin-tuning),使模型收敛到更好的局部最优点。
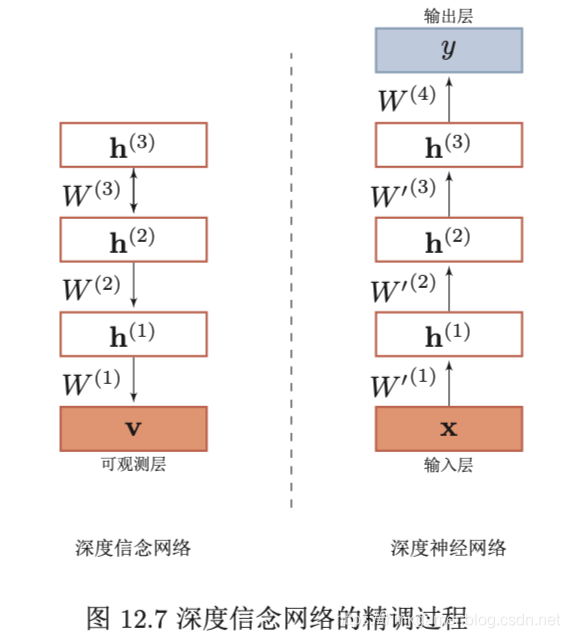
作为生成模型的精调,除了顶层的受限玻尔兹曼机,其他层之间的权重被分成向上的认知权重(recognition weights)W′W'W′和向下的生成权重(generative weights)WWW。认知权重用来进行后验概率计算,而生成权重用来进行定义模型。认知权重的初始值W′(l)=W(l)TW'^{(l)}=W^{(l)T}W′(l)=W(l)T。
深度信念网络一般采用contrastive wake-sleep算法进行精调,其算法过程是:
- Wake阶段:认知过程,通过外界输入(可观测变量)和向上认知权重,计算每一层隐变量的后验概率并采样。然后,修改下行的生成权重使得下一层的变量的后验概率最大。也就是“如果现实跟我想象的不一样,改变我的权重使得我想象的东西就是这样的”
- Sleep阶段:生成过程,通过顶层的采样和向下的生成权重,逐层计算每一层的后验概率并采样。然后,修改向上的认知权重使得上一层变量的后验概率最大。也就是“如果梦中的景象不是我闹中的相应概念,改变我的认知权重使得这种景象在我看来就是这个概念”
- 交替进行Wake和Sleep过程,直到收敛
作为深度神经网络的精调 深度信念网络的一个应用是作为深度神经网络的预训练部分,提供神经网络的初始权重。
在深度信念网络的最顶层再增加一层输出层,然后再使用反向传播算法对这些权重进行调优。特别是在训练数据比较少的时候,预训练的作用非常大。因为不恰当的初始化权重会显著影响最终模型的性能,而预训练获得的权重在权重空间中比随机权重更接近最优的权重,避免了反向传播算法因随机初始化权重参数而容易陷入局部最优和训练时间长的缺点。这不仅仅提升了模型的性能,也加快了调优阶段的收敛速度。
下图给出了深度信念网络作为生成模型和判断模型的精调过程。
总结
玻尔兹曼机能够学习数据的内部表示,并且其参数学习的方式和赫布型学习十分类似。没有任何约束的玻尔兹曼机因为过于复杂,难以应用在实际问题上。通过引入一定的约束(即变为二分图),受限玻尔兹曼机在特征提取、协同过滤、分类等多个任务上取得了广泛的应用。
和深度信念网络十分类似的一种深度概率模型是深度玻尔兹曼机(deep Boltzmann Machines ,DBM)。深度玻尔兹曼机是由多层的受限玻尔兹曼机堆叠而成,是真正的无向图模型,其联合概率是通过能量函数来定义。和深度信念网络相比,深度玻尔兹曼机的学习和推断要更加困难。
尽管深度信念网络作为一种深度学习模型已经很少使用,但其在深度学习发展过程中的贡献十分巨大,并且其理论基础为概率图模型,有非常好的解释性,依然是一种值得深入研究的模型。
 扫一扫 关注微信公众号!号主 专注于搜索和推荐系统,尝试使用算法去更好的服务于用户,包括但不局限于机器学习,深度学习,强化学习,自然语言理解,知识图谱,还不定时分享技术,资料,思考等文章!
扫一扫 关注微信公众号!号主 专注于搜索和推荐系统,尝试使用算法去更好的服务于用户,包括但不局限于机器学习,深度学习,强化学习,自然语言理解,知识图谱,还不定时分享技术,资料,思考等文章!
扫一扫 关注微信公众号!号主 专注于搜索和推荐系统,尝试使用算法去更好的服务于用户,包括但不局限于机器学习,深度学习,强化学习,自然语言理解,知识图谱,还不定时分享技术,资料,思考等文章!
扫一扫 关注微信公众号!号主 专注于搜索和推荐系统,尝试使用算法去更好的服务于用户,包括但不局限于机器学习,深度学习,强化学习,自然语言理解,知识图谱,还不定时分享技术,资料,思考等文章!

- 点赞 1
- 收藏
- 分享
- 文章举报
 Thinkgamer_
博客专家
发布了319 篇原创文章 · 获赞 472 · 访问量 179万+
他的留言板
关注
Thinkgamer_
博客专家
发布了319 篇原创文章 · 获赞 472 · 访问量 179万+
他的留言板
关注

- 技术文章 | 深度学习的这些坑你都遇到过吗?神经网络11大常见陷阱及应对方法
- 深度学习源码剖析:使用双线性插值方式初始化神经网络的可训练参数
- 深度学习的这些坑你都遇到过吗?神经网络 11 大常见陷阱及应对方法
- 深度学习-深度信念(置信)网络(DBN)-从原理到实现(DeepLearnToolBox)
- 深度学习算法原理——神经网络的基本原理
- 【深度学习_2.1.1】神经网络参数初始化
- 深度学习算法原理——栈式自编码神经网络
- 深度学习第二课 改善深层神经网络:超参数调试、正则化以及优化 第二周Mini_batch+优化算法 笔记和作业
- 物理学家揭示深度学习原理:神经网络与宇宙本质惊人关联
- 最新深度学习之神经网络(CNN/RNN/GAN)算法原理+实战(完整版)
- 深度学习算法实践7---前向神经网络算法原理
- 深度学习-神经网络参数(hyper-parameters)选择
- 《深度学习工程师-吴恩达》02改善深层神经网络--超参数优化、batch正则化和程序框架 学习笔记
- 吴恩达-深度学习笔记《改善深层神经网络:超参数调试、正则化以及优化》
- 深度学习常见主流经典算法概述(一)(从k近邻,线性分类器,SVM,神经网络讲起)
- 深度学习-深度信念(置信)网络(DBN)-从原理到实现(DeepLearnToolBox)
- Coursera deeplearning.ai 深度学习笔记1-3-Shallow Neural Networks-浅层神经网络原理推导与代码实现
- 深度学习之神经网络(CNN/RNN/GAN)算法原理+实战 完整版
- 深度学习的这些坑你都遇到过吗?神经网络11大常见陷阱及应对方
- 深度学习:原理简明教程03-神经网络基础——作者:Ling