Python爬虫实现多语言翻译词典
2019-12-27 17:07
746 查看
【推荐】2019 Java 开发者跳槽指南.pdf(吐血整理) >>>

代码如下:
import urllib.request
from lxml.html import etree
import os
from urllib.parse import urlencode
def InputWord(step, type = 0):
_type = type
if step == 1:
_type = input("\n1.中 => 英\n2.英 => 中\n3.中 => 日\n4.日 => 中\n(1/2/3/4)请选择:")
if _type != '1' and _type != '2' and _type != '3' and _type != '4':
InputWord(step, 0)
step = 2
tips = '\n请输入要查询的中文(输入*返回上一级):'
tmp_url = 'https://dict.youdao.com/w/{a}/'
data_xpath = '//*[@id="phrsListTab"]/div/ul/p/span/a/text()'
if _type == '2':
tips = '\n请输入要查询的英文(输入*返回上一级):'
data_xpath = '//*[@id="phrsListTab"]/div/ul/li/text()'
if _type == '3':
tmp_url = 'https://dict.youdao.com/w/jap/{a}/'
data_xpath = '//div/ul/li/p[@class="sense-title"]/text()'
if _type == '4':
tips = '\n请输入要查询的日文(输入*返回上一级):'
tmp_url = 'https://dict.youdao.com/w/jap/{a}/'
data_xpath = '//div/ul/li/span[@class="field"]/text()'
word = input(tips)
if str(word) == '*':
InputWord(1, 0)
params = {
"value": word.replace(' ', '-')
}
url = tmp_url.format(a=urlencode(params)[6:urlencode(params).__len__()])
req = urllib.request.Request(url)
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36')
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
data = etree.HTML(html).xpath(data_xpath)
if not data:
print("未能查询到结果")
else:
print('===================================\n查询结果:')
for d in data:
print(d)
print('===================================')
InputWord(step, _type)
InputWord(1, 0)
os.system('pause')
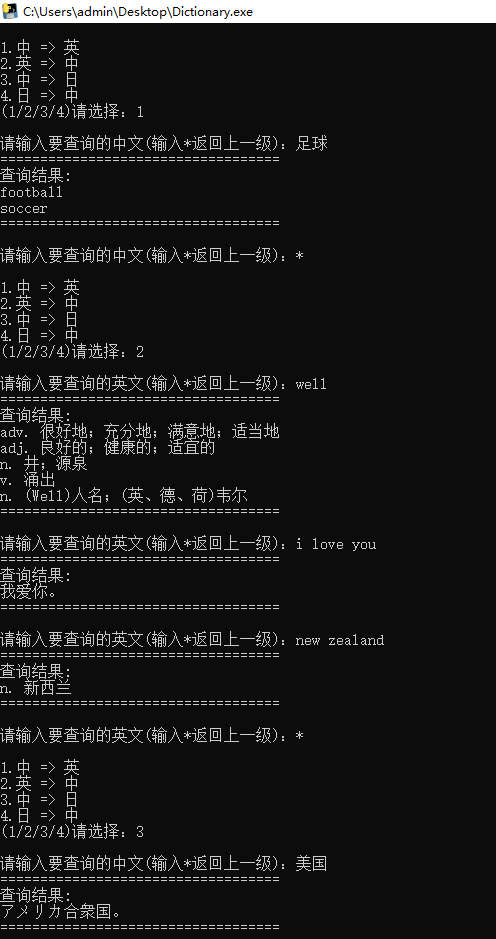
实现结果:


相关文章推荐
- python爬虫实现中英翻译词典
- 网络爬虫:利用有道实现“语言翻译”功能
- python语言-实现半自动爬虫
- python爬虫实现有道自动化翻译
- Python 小工具:调用「百度翻译API」实现英汉互译及多语言翻译
- 拉勾网爬虫-python语言实现
- python与百度翻译实现简单词典
- 利用python爬虫实现简单翻译软件
- Python有道翻译2.1版本爬虫实现
- 利用python实现新浪微博爬虫
- Python爬虫的学习和实现-双福菜价爬取
- 用python实现网络爬虫
- 基于Python实现微信公众号爬虫进行数据分析
- 使用python语言结合beautifulsoup编写简单的网络爬虫
- python实现简易采集爬虫
- python 简单爬虫实现
- python利用beautifulSoup实现爬虫
- python实现网络爬虫学习总结
- Python实现简单的爬虫
- 利用python实现网络爬虫