机器学习笔记--鸢尾花分类(二)
2019-11-22 17:31
239 查看
【推荐】2019 Java 开发者跳槽指南.pdf(吐血整理) >>>

· 训练和测试数据
要验证模型是否成功,通常会把收集好带标签的数据分成两部分,一部分用来构建机器学习模型,叫做训练数据(training data),其余的用来测试,叫做测试数据(test data)。scikit-learn 中的 train_test_split 函数一般会把75%的数据作为训练集,25%的数据作为测试集。 根据train_test_split对数据分类:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
iris_dataset['data'], iris_dataset['target'], random_state=0)
#random_state = 0 是他的随机种子
print("X_train shape: {}".format(X_train.shape))
print("y_train shape: {}".format(y_train.shape))
print("X_test shape: {}".format(X_test.shape))
print("y_test shape: {}".format(y_test.shape))
得到结果:
X_train shape: (112, 4) y_train shape: (112,) X_test shape: (38, 4) y_test shape: (38,)
说明训练集输入的是一个112*4的二维数组,得到的是一个长度112的一维数组;测试集输入的是一个38*4的二维数组,得到的是一个长度38的一维数组。
· 观察数据
沿用上面的代码,我们用pandas里一个绘制散点图矩阵的函数,叫作scatter_matrix绘制一下散点图:
import mglearn
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
iris_dataset = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
iris_dataset['data'], iris_dataset['target'], random_state=0)
iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names)
grr = pd.plotting.scatter_matrix(iris_dataframe, c=y_train, figsize=(15, 15), marker='o',
hist_kwds={'bins': 20}, s=60, alpha=.8, cmap=mglearn.cm3)
可以得到下图:
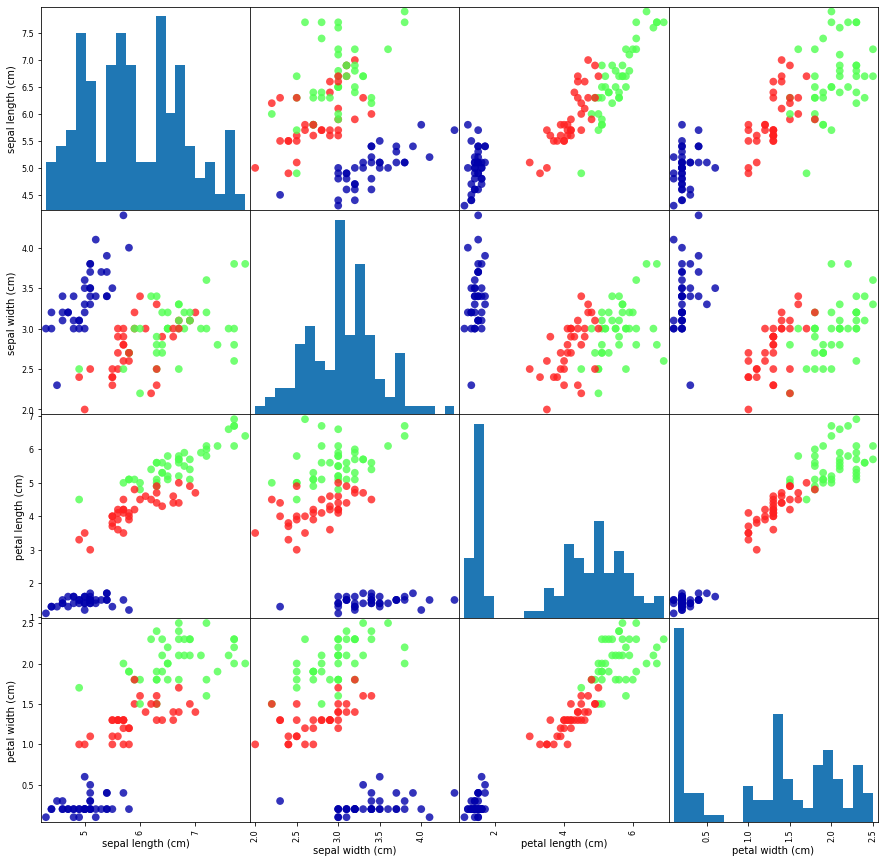
可以看出根据任意两两特征基本都可以把这三个类别区分开来,说明机器学习模型很可能是可以被学会的。
· KNN算法
KNN算法总结起来就是保存训练集,然后有一个新点加入时寻找与他最近的k个点,然后根据这些邻居中数量最多的类别进行判断,这里我们设k为1。
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=1) #根据最近的一个点判断
knn.fit(X_train, y_train) #用训练组建模
y_pred = knn.predict(X_test) #用测试组得到预测的数据
print("Test set predictions:\n {}".format(y_pred)) #打印预测的数据
print("Test set score: {:.2f}".format(np.mean(y_pred == y_test))) #和我们的测试集的结果比较
得到结果:
Test set predictions: [2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0 2] Test set score: 0.97
对于这个模型来说,测试集的精度约为 0.97,比较能够接受了。

相关文章推荐
- 机器学习笔记——利用sklearn中KNN算法实现鸢尾花分类
- 上课笔记-机器学习(1)-鸢尾花分类
- 机器学习框架ML.NET学习笔记【2】入门之二元分类
- 机器学习问题分类--机器学习基石笔记
- [机器学习笔记]二:Classification and logistic regression(分类和逻辑回归)
- 《Python机器学习》笔记--感知机分类鸢尾花数据集
- 机器学习笔记1——机器学习算法分类整理
- 机器学习笔记3——朴素贝叶斯算法(分类)
- 机器学习笔记04:逻辑回归(Logistic regression)、分类(Classification)
- 【吴恩达机器学习笔记】分类问题之逻辑回归模型(二元分类及多分类问题)
- 听课笔记(第十一讲): 线性分类模型 (台大机器学习)
- python机器学习-----文本分类笔记
- 【机器学习入门】Andrew NG《Machine Learning》课程笔记之四:分类、逻辑回归和过拟合
- 机器学习框架ML.NET学习笔记【4】多元分类之手写数字识别
- 王小草【机器学习】笔记--分类算法之朴素贝叶斯
- 机器学习笔记-决策树跟分类规则
- 【机器学习笔记四】分类算法 - 逻辑回归
- 机器学习笔记之朴素贝叶斯分类算法
- 机器学习实战 笔记一:kNN分类算法
- Coursera机器学习(Andrew Ng)笔记:回归与分类问题