软件技术架构:通过限流与熔断,打造一个“靠谱”的系统
如果“高并发”是为了让系统变得“有效率”,可以抵抗大规模用户访问,那限流与熔断就是为了让系统变得“更靠谱”。靠谱包括了高可用性、稳定性、可靠性,做一个“靠谱”的系统需要从很多方面着手,本文着重与大家探讨“限流”与“熔断”。
本文选自《软件架构设计:大型网站技术架构与业务架构融合之道》一书。

限流在日常生活中很常见,景点限流、早晚高峰限流等。对应到计算机中,比如要办活动、秒杀等,通常会限流。限流可以分为技术层面的限流和业务层面的限流。技术层面的限流比较通用,各种业务场景都可以用到;业务层面的限流需要根据具体的业务场景做开发。
**(1)技术层面的限流。**一种是限制并发数,也就是根据系统的最大资源量进行限制,比如数据库连接池、线程池、Nginx的limit_conn模块;另一种是限制速率(QPS),比如Guava的RateLimiter、Nginx的limit_req模块。
限制速率的这种方式对于服务的接口调用非常有用。比如通过压力测试可以知道服务的QPS是2000,就可以限流为2000QPS。当调用方的并发量超过了这个数字,会直接拒绝提供服务。这样一来,即使突然有大量的请求进来,服务也不会被压垮,虽然部分请求被拒绝了,但保证了其他的服务可以正常处理。一般成熟的RPC框架都有相应的配置,可以对每个接口进行限流,不需要业务人员自己开发。
**(2)业务层面的限流。**比如在秒杀系统中,一个商品的库存只有100件,现在有2万人抢购,没有必要放2万个人进来,只需要放前500个人进来,后面的人直接返回已售完即可。
针对这种业务场景,可以做一个限流系统,或者叫售卖的资格系统(票据系统),票据系统里面存放了500张票据,每来一个人,领一张票据。领到票据的人再进入后面的业务系统进行抢购;对于领不到票据的人,则返回已售完。
在具体实现上,有团队使用Redis,也有团队直接基于Nginx + Lua脚本来实现,两者的思路类似。
**(3)限流算法。**限制并发数的计算原理很简单,系统只需要维护正在使用的资源数或空闲数,比如数据库的连接数、线程池的线程数。限制速率的算法稍微复杂,常用的有漏桶算法和令牌桶算法,下面详细介绍。
▊ 漏桶算法
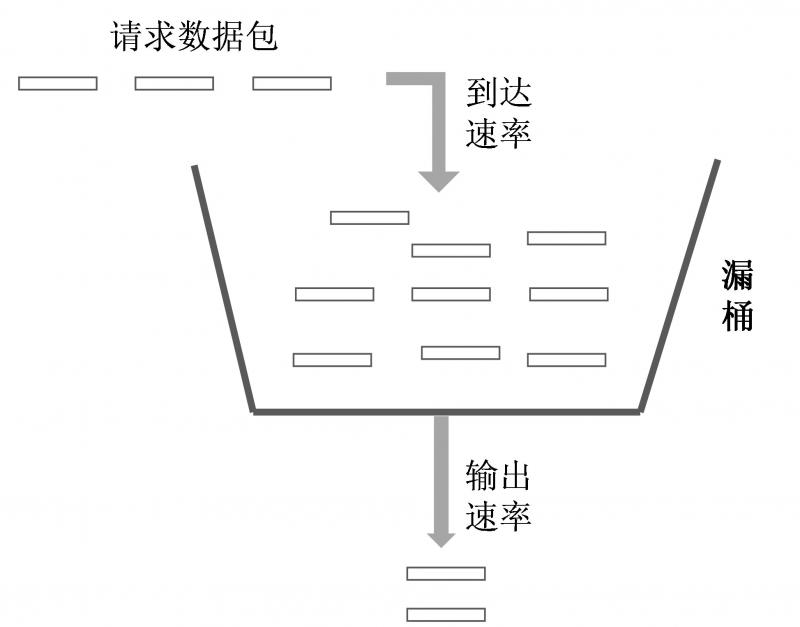
- 漏桶的容量是固定的,流出的速率是恒定的;
- 流入的速率是任意的;
- 如果桶是空的,则不需流出;
- 如果流入数据包超出了桶的容量,则流入的数据包溢出了(被丢弃),而漏桶容量不变。
▊ 令牌桶算法
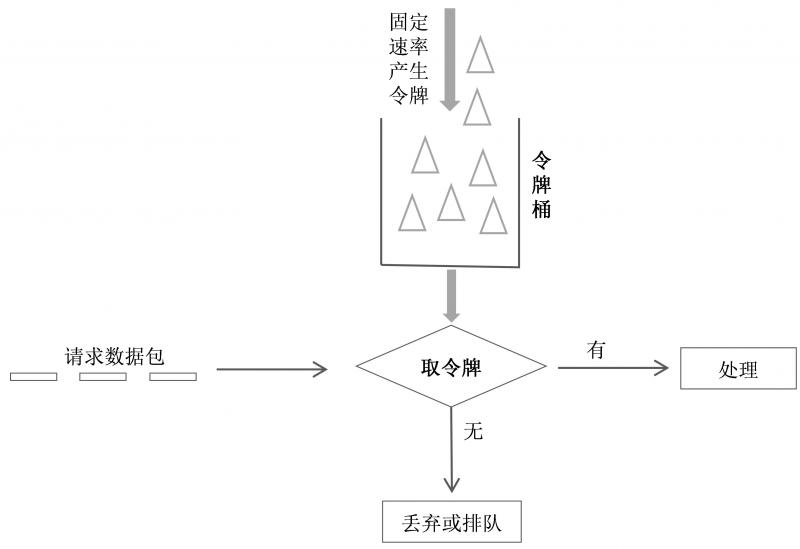
- 令牌桶的容量也是固定的,向里流入令牌的速率是恒定的;
- 当令牌桶满时,新加入的令牌会被丢弃;
- 当一个请求到达之后,从桶中取出一个令牌。如果能取到令牌,则该请求将被处理;
- 如果取不到令牌,则该请求要么被丢弃,要么排队。
对比两个算法会发现,二者的原理刚好相反,一个是流出速率保持恒定,一个是流入速率保持恒定。二者的用途有一定差别:令牌桶限制的是平均流入速率,而不是瞬时速率,因为可能出现一段时间没有请求进来,令牌桶里塞满了令牌,然后短时间内突发流量过来,一瞬间(可以认为是同时)从桶里拿几个令牌出来;漏桶有点类似消息队列,起到了削峰的作用,平滑了突发流入速率。

当电路发生短路、温度升高,可能烧毁整个电路的时候,保险丝会自动熔断,切断电路,从而保护整个电路系统。
在计算机系统中,也有类似设计保险丝的思路。熔断有两种策略:一种是根据请求失败率,一种是根据请求响应时间。
**(1)根据请求失败率做熔断。**对于客户端调用的某个服务,如果服务在短时间内大量超时或抛错,则客户端直接开启熔断,也就是不再调用此服务。然后过一段时间,再把熔断打开,如果还不行,则继续开启熔断。这也正是经常提到的“快速失败(Fail Fast)”原则。
以Hystrix为例,它有几个参数来配置熔断器的策略:
circuitBreaker.requestVolumeThreshold //滑动窗口的大小,默认为20 circuitBreaker.sleepWindowInMilliseconds //过多长时间,熔断器再次检测是否开启,默认为5000,即5s circuitBreaker.errorThresholdPercentage //失败率,默认为50%
三个参数放在一起,所表达的意思是:每20个请求中,有50%失败时,熔断器就会打开,此时再调用此服务,将会直接返回失败,不再调用远程服务。直到5s之后,重新检测该触发条件,判断是否把熔断器关闭,或者继续打开。
**(2)根据请求响应时间做熔断。**除了根据请求失败率做熔断,阿里巴巴公司的Sentinel还提供了另外一种思路:根据请求响应时间做熔断。当资源的平均响应时间超过阈值后,资源进入准降级状态。接下来如果持续进入5个请求,且它们的RT持续超过该阈值,那么在接下来的时间窗口内,对这个方法的调用都会自动地返回。代码样例如下:
DegradeRule rule = new DegradeRule(); rule.setResource(“xxx”); rule.setCount(50); rule.setGrade(RuleConstant.DEGRADE_GRADE_RT); rule.setTimeWindow(5000);
样例中的时间单位是ms,意思是当平均响应时间大于50ms,并且接下来持续5个请求的RT都超过50ms时,熔断将开启。5000ms之后,熔断将再次关闭。
与限流进行对比会发现:限流是服务端,根据其能力上限设置一个过载保护;而熔断是调用端对自己做的一个保护。
注意:能熔断的服务肯定不是核心链路上的必选服务。如果是的话,则服务如果超时或者宕机,前端就不能用了,而不是熔断。所以,说熔断其实也是降级的一种方式。
《软件架构设计:大型网站技术架构与业务架构融合之道》
余春龙 著
自成一派的架构设计方法论,教你体系化的架构设计思维,点击了解本书详情。
系统的高可用性、稳定性与可靠性需要从很多方面着手,本文带你了解如何通过“限流”与“熔断”让系统变得“更靠谱”。

- K8 系统中省市县数据表的设计可以反映出什么? 通过一个基础业务表的设计品味软件系统的整体架构
- 通过学习学生信息管理系统软件,C程序中,如何设计和编写一个应用系统?
- 基于DotNet构件技术的企业级敏捷软件开发平台 AgileEAS.NET - 系统架构
- 一个数据分析系统的技术架构设计浅析
- GIS系统与一个好的软件架构,Why not and how?
- 系统架构、软件架构、物理架构、总体架构、业务架构、应用架构、数据架构、技术架构
- 对于一个管理性的软件来讲,数据主键的产生策略是很关键的一点,这个关系到整个系统的基础架构思想。
- WCF技术剖析之一:通过一个ASP.NET程序模拟WCF基础架构
- 一个软件系统的架构到底应该包含些什么?
- 一个定期翻译国外Android优质的技术、开源库、软件架构设计、测试等文章的开源项目
- 综合图形学算法及OpenGL技术开发一个小型图形软件系统
- 通过学习学生信息管理系统软件,C程序中,如何设计和编写一个应用系统
- WCF技术剖析之一:通过一个ASP.NET程序模拟WCF基础架构
- 通过学习学生信息管理系统软件,C程序中,如何设计和编写一个应用系统
- 大型企事业信息管理系统非功能性需求&软件架构技术参考 (转)
- 【大型web架构】一个大型web系统架构设计和技术选型的讨论摘录
- 软件选型 系统技术路线和架构是重点
- 学习笔记1:《大型网站技术架构 核心原理与案例分析》之 大型网站软件系统的特点
- [原创]WCF技术剖析之一:通过一个ASP.NET程序模拟WCF基础架构