Spark ML使用DataFrame进行K-Means
2019-10-18 07:10
1676 查看
1.前言
前一篇文章使用了RDD的方式,进行了K-Means聚类.
从Spark 2.0开始,程序包中基于RDD的API spark.mllib已进入维护模式.现在,用于Spark的主要机器学习API是软件包中基于DataFrame的API spark.ml.
这次使用DataFrame的方式 进行K-Means聚类.
数据集和基本配置查看前一篇文章
2.KMeansDataFrame
package com.htkj.spark.mllib;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.MapFunction;
import org.apache.spark.ml.Pipeline;
import org.apache.spark.ml.PipelineModel;
import org.apache.spark.ml.PipelineStage;
import org.apache.spark.ml.clustering.KMeans;
import org.apache.spark.ml.clustering.KMeansModel;
import org.apache.spark.ml.feature.StringIndexer;
import org.apache.spark.ml.feature.StringIndexerModel;
import org.apache.spark.ml.feature.VectorAssembler;
import org.apache.spark.ml.linalg.Vector;
import org.apache.spark.sql.*;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import java.util.ArrayList;
public class KMeansDataFrame {
public static void main(String[] args) {
//创建SparkSession
SparkSession spark = SparkSession
.builder()
.master("local")
.appName("K-Means-DataFrame")
.getOrCreate();
//读取数据 转换为RDD
JavaRDD<String> clusterRDD = spark.sparkContext()
.textFile("C:\\Users\\Administrator\\Desktop\\cluster.txt", 1)
.toJavaRDD();
//设置列的名称
String schemaString="region x1 x2 x3 x4 x5 x6 x7 x8";
//创建集合 存储字段名称
ArrayList<StructField> fields = new ArrayList<>();
//将schemaString 切割 遍历 存储到字段中
for (int i = 0; i < schemaString.split(" ").length; i++) {
String fieldName = schemaString.split(" ")[i];
if (i==0){
StructField field = DataTypes.createStructField(fieldName, DataTypes.StringType, true);
fields.add(field);
}else {
StructField field = DataTypes.createStructField(fieldName, DataTypes.DoubleType, true);
fields.add(field);
}
}
//设置字段
StructType schema = DataTypes.createStructType(fields);
//存储数据
JavaRDD<Row> rowRDD = clusterRDD.map(record -> {
String[] split = record.split("\t");
return RowFactory.create(split[0]
, Double.valueOf(split[1])
, Double.valueOf(split[2])
, Double.valueOf(split[3])
, Double.valueOf(split[4])
, Double.valueOf(split[5])
, Double.valueOf(split[6])
, Double.valueOf(split[7])
, Double.valueOf(split[8])
);
});
//将RDD转化为dataFrame形式
Dataset<Row> dataFrame = spark.createDataFrame(rowRDD, schema);
//输出表结构
dataFrame.printSchema();
//创建临时视图
dataFrame.createOrReplaceTempView("cluster");
//查询
Dataset<Row> results = spark.sql("select region from cluster");
//单独提取某个字段的内容
Dataset<String> regionsDS = results.map((MapFunction<Row, String>) row -> "region:" + row.getString(0), Encoders.STRING());
//展示
regionsDS.show();
//查询所有
Dataset<Row> dataAll = spark.sql("select * from cluster");
//将region字段 转换为数字的 label
StringIndexerModel labelIndex = new StringIndexer().setInputCol("region").setOutputCol("label").fit(dataAll);
//将x1-x8字段 拼接为向量
VectorAssembler assembler = new VectorAssembler().setInputCols("x1,x2,x3,x4,x5,x6,x7,x8".split(",")).setOutputCol("features");
//如果有离散的数据 就使用OneHotEncoder
// OneHotEncoder x1 = new OneHotEncoder().setInputCol("x1").setOutputCol("x1").setDropLast(false);
//使用Pipeline 转化模型
Pipeline pipeline = new Pipeline().setStages(new PipelineStage[]{labelIndex, assembler});
PipelineModel model = pipeline.fit(dataAll);
Dataset<Row> dataset = model.transform(dataAll);
//输出
dataset.show(100,100);
//设置聚类数量为5 迭代100次 随机数种子为100
KMeans kMeans = new KMeans().setK(5).setMaxIter(100).setSeed(100L);
//建立模型
KMeansModel kMeansModel = kMeans.fit(dataset).setFeaturesCol("features").setPredictionCol("prediction");
//输出误差平方和
double WSSSE = kMeansModel.computeCost(dataset);
System.out.println("误差平方和 "+WSSSE);
//输出聚类中心
Vector[] centers = kMeansModel.clusterCenters();
System.out.println("聚类中心: ");
for (Vector center : centers) {
System.out.println(center);
}
//输出预测结果
Dataset<Row> transform = kMeansModel.transform(dataset);
transform.foreach(s->{
int length = s.toString().length();
String[] split = s.toString().substring(1, length - 1).split(",");
String region = split[0];
String cluster = split[split.length - 1];
System.out.println(region+"属于聚类:"+cluster);
});
}
}
3.输出内容
3.1表结构

3.2单独提取某个字段的内容

3.3dataset展示内容
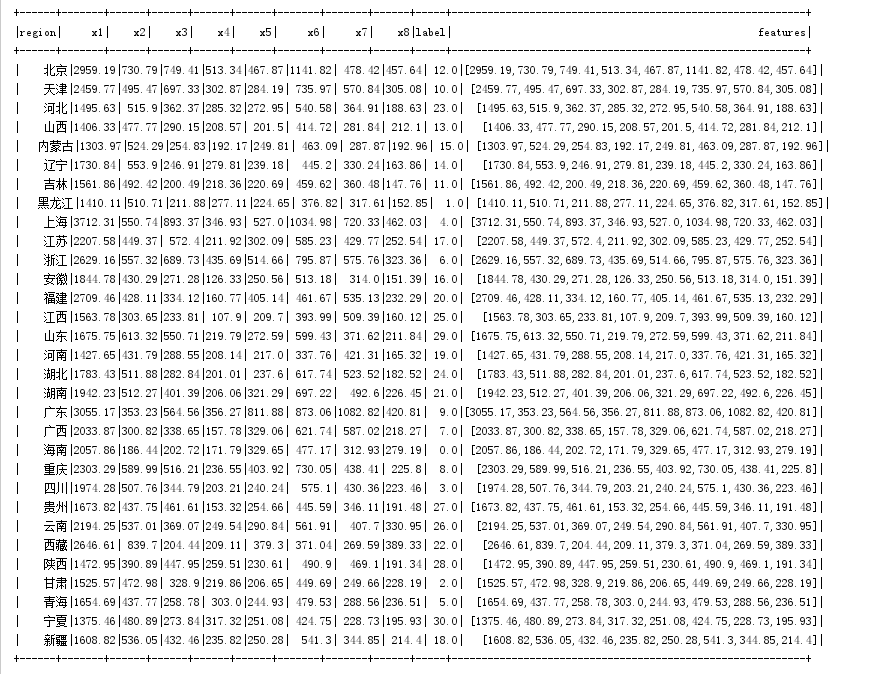
3.4误差平方和

3.5聚类中心

3.6预测结果

可以看到,北京 上海 广东 浙江 归为一类,可以认为分类结果基本准确

相关文章推荐
- python中使用iterrows()对dataframe进行遍历的实例
- 『 Spark 』7. 使用 Spark DataFrame 进行大数据分析
- 使用Spark DataFrame进行大数据处理
- 使用pandas对两个dataframe进行join的实例
- 使用pandas对两个dataframe进行join
- python里使用iterrows()对dataframe进行遍历
- spark scala 对dataframe进行过滤----filter方法使用
- 『 Spark 』7. 使用 Spark DataFrame 进行大数据分析
- 使用stack,unstack对dataframe进行行列转换
- 使用FormData,进行Ajax请求并上传文件
- .Net——使用DataContractJsonSerializer进行序列化及反序列化基本操作
- python如何对dataframe下面的值进行大规模赋值
- 使用Spring-data进行Redis操作
- python报错:对dataframe进行修改时产生SettingWithCopyWarning
- 使用 FormData 进行 Ajax 请求并上传文件
- 使用ASIHTTPRequest的ASIDataCompressor与ASIDataDecompressor进行gzip压缩与解压缩,出现的问题
- 使用spring-session-data-redis来进行session共享
- Hbase总结(三)--使用spring-data-hadoop进行hbase的读写操作
- 使用.net 3.5的DataContractJsonSerializer进行JSON Serialization
- 使用Spring DATA JPA进行数据库开发