如何设计出一个比较合理的数据归档系统


在任何的数据库系统中,大部分都会有一个需求,数据归档,业务数据库不应该是永无止境的进行数据存取的目的地。业务数据库主要的功能是满足业务的保留数据的需求,以及相关保证性能等目的。如果留存的数据业务已经不再需要,并且已经影响了性能,则归档是必须要做的一件事情。
首先如果要做数据归档,我会想到以下问题
1 首先需要和业务以及开发确认哪些表时可以被归档的
2 需要确认业务数据库中数据的留存时间,例如保留5年以内的数据,或者3个月以内的数据,这都是一个数据留存的范围,
3 每次归档的时间段,例如一个月一归档,还是一年做一次归档,如果数据量大的情况下,自动化的数据归档是比较省心省力的
4 一些意外情况,例如写好的归档程序,运行良好,但某天开始不能进行归档,首先要考虑是不是原表的结构有变动,例如增加了字段,或者字段的类型可能有变化
5 数据的归档,采用的方式也很多,例如可以通过传统的数据备份的方式进行数据的归档,通过实践条件,将需要备份的数据导出,在将其删除,也可以通过数据EXPORT 到其他位置的方式,至于那种好,那就要看具体的情况而定了。
6 数据归档后的数据留存的介质以及留存的时间,一般来说这个很少被提起,在数据归档的初期,但如果你不说,经过几年下来,你会发现你归档数据的位置也会产生某些问题,例如存储空间的问题,或者业务要查询这些历史记录,而发现查的非常慢,或者根本就查不到的问题
7 数据的归档中,也可能产生各种错误,而怎么将这些情况如实的反应到归档系统中,则是必须的工作。
8 数据归档的精度的问题,很可能由于某些原因,某些数据已经被复制到归档系统,但由于错误,数据再次通过程序导入到归档系统怎么处理的问题,容错率的问题需要被考虑。

下面举一个列子,请忽略由于不同数据库引起的SQL 语句的不同,只看逻辑
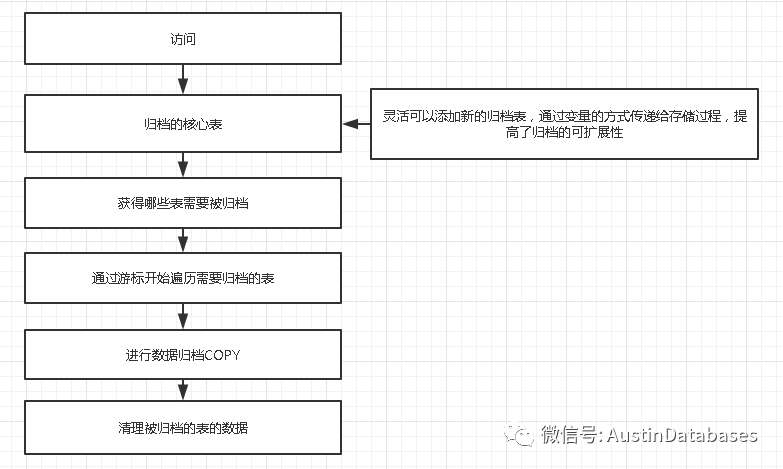
REATE PROCEDURE archive_table
AS
BEGIN
SET NOCOUNT ON;
if Exists(select top 1 * from sysObjects where Id=OBJECT_ID(N'core_archive') and xtype='U')
DECLARE @source_database nvarchar(50),@source_table nvarchar(100),@destination_table nvarchar(100),@skip_status tinyint,@archive_num tinyint,@key_column varchar(100)
DECLARE @sql NVARCHAR(500)
DECLARE cur CURSOR STATIC
FOR
SELECT source_database,source_table ,destination_table ,skip_status ,archive_num ,key_column FROM [DB_ASC_ACHIVE].[dbo].[core_archive] where skip_status = 0
OPEN cur
FETCH NEXT FROM cur INTO @source_database,@source_table ,@destination_table ,@skip_status ,@archive_num ,@key_column
WHILE ( @@fetch_status = 0 )
BEGIN
select @source_database,@source_table ,@destination_table ,@skip_status ,@archive_num ,@key_column
declare @db nvarchar(50)
if @source_database = 'ACS.dbo.'
set @db= 'acstest.dbo.'
else
set @db = 'aaptest.dbo.'
select @sql = ('insert into ' + 'DB_ASC_ACHIVE.dbo.' + @destination_table + ' select * from ' + @db + @source_table + ' where ' + @key_column + ' < ''' + convert(varchar(20),dateadd(month,-3,getdate()),120) ) + ''''
declare @ssql nvarchar(1000)
declare @rum int
select @ssql = (' select @count=count(*) from ' + @db + @source_table + ' where ' + @key_column + ' < ''' + convert(varchar(20),dateadd(month,-3,getdate()),120) ) + ''''
exec sp_executesql @ssql,N'@count int out', @rum out
select @rum
insert into [dbo].[archive_history] (start_time,end_time,table_name,database_name,row_number,done_status) values (getdate(),'9999-12-12',@source_table,@db,@rum,0)
execute (@sql)
declare @dsql nvarchar(1000)
select @dsql = ('delete from ' + @db + @source_table + ' where ' + @key_column + ' < ''' + convert(varchar(20),dateadd(month,-3,getdate()),120) ) + ''''
select @dsql
execute (@dsql)
update [dbo].[archive_history] set end_time = getdate(),done_status = 1 where id =( select top 1 id from [dbo].[archive_history] order by start_time desc)
FETCH NEXT FROM cur INTO @source_database,@source_table ,@destination_table ,@skip_status ,@archive_num ,@key_column
END
CLOSE cur
DEALLOCATE cur
END
GO
其中有两点需要注意,
1 归档的程序不要写死,如果在存储过程中,指名道姓的写出需要归档的表名,或目的表名,这样虽然简单,但如果后期归档的表变化,或者添加归档的表,则还需要修改存储过程
2 归档必须有历史记录,记录归档的表,以及开始的时间,结束的时间,以及归档的行数,以备运维人员查询。
3 任何程序或者脚本都不可能不出错,而记录错误,终止程序则是必须的设置
以上的存储过程在第三点上还不完善,还需要进行改善。
本文分享自微信公众号 - AustinDatabases(AustinDatabases)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。

- 【数据可视化之采集】如何设计一个前端监控系统
- 【数据可视化之采集】如何设计一个前端监控系统(作者未完成)
- 一个数据分析系统的技术架构设计浅析
- 如何设计一个SEO亲和的CMS系统
- 转载:如何设计一个可扩展的用户登录系统
- 【分享】一个通用强大的主数据管理系统(架构设计讲解及源码下载)
- 如何设计一个可伸缩的计数系统
- 【分享】一个通用强大的主数据管理系统(架构设计讲解及源码下载)
- 转载IBM-如何设计一个小而美的秒杀系统?
- 如何在一个系统中设计权限控制机制(1)
- 从”如何设计一个通用数据类型的数组“谈什么才是程序员真正应该干的事
- 如何把一个数据存到文件系统中?是怎么存的?--【原创】
- 通过学习学生信息管理系统软件,C程序中,如何设计和编写一个应用系统
- 【一个批量计算的调度系统的设计与实现】如果需要对成千上万的网络抓包数据文件在规定的时间内进行解析,应该怎么做?
- 通过学习学生信息管理系统软件,C程序中,如何设计和编写一个应用系统
- 我是如何为技术博客设计一个推荐系统(上):统计与评分加权
- 通过学习学生信息管理系统软件,C程序中,如何设计和编写一个应用系统?
- 一个通用的单元测试框架的思考和设计07-实现篇-自动管理测试数据-如何为自增长主键id赋值
- 建站或者网站搬家换空间的时候,企业站长最关心的一个问题是该如何选择网站空间,而这一问题对于一些擅长的站长来说非常小意思,但对于部分企业站长来说是一个比较头疼的问题。根据不完整数据显示,很多企业站长因为