机器学习入门 笔记(二) 机器学习基础概念
第二章 机器学习基础概念
1、机器的数据
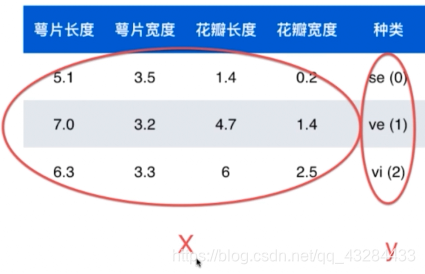
我们以鸢尾花的数据为例。收集大量鸢尾花的数据,花瓣的萼片长度、萼片宽度、花瓣长度、花瓣宽度,同时标记属于se、ve、vi三种鸢尾花之一。
-
数据的整体叫做数据集。
我们收集的所有鸢尾花的数据就是一个数据集。 -
每一行数据称为一个样本。
(萼片长度=5.1,萼片宽度=3.5,花瓣长度=1.4、花瓣宽度=0.2、花期=se(0)),这样一行记录,称之为一个样本。 -
除最后一列,每一列表达样本的一个特征。
我们把萼片长度、萼片宽度、花瓣长度、花瓣宽度,叫做样本的特征。
(萼片长度=5.1,萼片宽度=3.5,花瓣长度=1.4、花瓣宽度=0.2)称为一个样本的特征向量。赋予语义以后,通常用一个列向量表示。

-
最后一列,称之为标记。
根据花朵的所有特征以及采集时花朵的状态,我们可以对花朵的花朵的花期进行标记,标记为待开的se(0)、盛放的ve(1)、凋谢的vi(2)三种。 -
用大写字母X表示特征矩阵,用小写字母表示y表示标记。第i个样本行写作
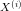
第i个样本第j个特征值
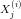
第i个样本的标记写作
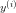 若我们只根据萼片的宽度和长度,把所有花朵映射到一张二维表上,横轴为萼片宽度,纵轴为萼片长度,可以清晰的看到样本主要集中在红蓝两处,样本则被简单的分类。我们把所有特征值组成的空间叫做特征空间,而分类任务本质就是对特征空间的划分。在多属性映射的高维空间同理。
若我们只根据萼片的宽度和长度,把所有花朵映射到一张二维表上,横轴为萼片宽度,纵轴为萼片长度,可以清晰的看到样本主要集中在红蓝两处,样本则被简单的分类。我们把所有特征值组成的空间叫做特征空间,而分类任务本质就是对特征空间的划分。在多属性映射的高维空间同理。
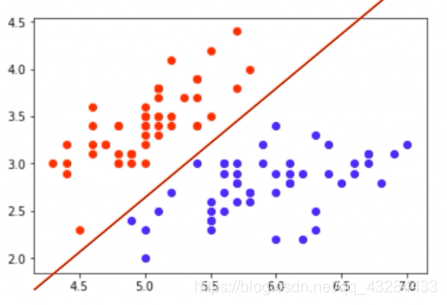
- 特征可以很抽象
特征可以很抽象,甚至没有语义。在图像中,每一个像素点都是特征,28x28的图像有784个特征,如果是彩色图像,特征更多。
2、机器学习的主要任务
本课程专注于机器学习中的监督学习。监督学习的基本任务是分类和回归。
分类
-
二分类
图像识别,判断一张图片是猫还是狗;根据病人各项数据,判断患者是良性肿瘤还是恶性肿瘤等。 -
多分类
手写数字识别,判断手写的数字是0~9中的哪个数字;市场风险评级;下围棋应该走那一步等。 -
多标签分类
例如图像识别中,一张女孩挥球拍的照片,标记女孩、球拍类型、动作等等。
因为是机器学习入门,主要学习二分类,部分多分类任务也能转化为二分类处理。
回归
- 结果是一个连续的数字的值,而非一个类别
一批数据给出房屋的面积、房屋的年龄、卧室数量、离地铁距离,提供房屋的价格等数据,来预测其他房屋的价格。价格是一个连续的值,而非一个类别。类似还有市场分析,预测学生的成绩分数等。 - 有时回归任务可以转化为分类任务
例如学生成绩,在回归任务中预测学生成绩分数,也可以转化为分类任务,对分数进行评级等。
3、监督学习和非监督学习
机器学习分类一:
监督学习
- 给机器的训练数据拥有“标记”或“答案”
例如鸢尾花分类中,及提供的鸢尾花的特征,也标记了鸢尾花的类型。
例如预测房价例子提供的数据中,除了提供房子的面积、卧室数量等信息,也提供了这些房子的售价价格。
监督学习通常采用K临近、线性回归、多项式回归、逻辑回归、SVM决策树和随机森林算法。
非监督学习:
-
给机器的训练数据没有任何“标记”或者“答案”
-
对没有“标记”的数据进行分类——聚类分析
电商网站中收集用户的消费行为,分类理智型消费者、冲动型消费者、性价比消费者等。 -
对数据进行降维处理
对采集的数据样本的特征进行提取或压缩
特征提取:信用卡的信用评级和人的胖瘦无关?
特征压缩:PCA算法处理,有时有的特征间关系很强,我们可以把多特征转化为特征间的映射关系从而减少特征数量,降维的好处也可以方便可视化。 -
异常检测
在二维的样本空间中,例如有异常点,它不具有表达样本特性的普遍性,可以去除。
半监督学习:
- 一部分数据有“标记”或者“答案”,另一部分数据没有
- 更常见:各种原因产生的标记缺失
通常先使用无监督学习手段对数据做处理,之后使用监督学习手段做模型的训练和预测。
增强学习:
- 根据周围环境的情况,采取行动,根据采取行的的结果,学习行为方式。
监督学习和半监督学习是机器学习的基础。
4、批量、在线学习、参数、非参数学习
机器学习分类二:
-
批量学习(离线学习)
先通过批量数据学习到模型,之后利用模型,向模型输入样例预测,模型不改变。
优点:简单
问题:如何适应环境变化?
解决方案:定时重新批量学习,重新训练模型。
缺点:每次重新批量学习,运算量巨大,在某些环境变化非常快情况下不可能实现。 -
在线学习
向学习得来的模型输入样例,得到预测结果,再于实时的正确结果对比,将正确结果放入算法中,继续修改模型。
优点:新的数据带来不好的变化?例如竞争者扰乱市场,使收集的样本中出现过多异常特征值。
解决:需要加强对数据进行监督----异常检测。
当数据数据量巨大时,采用在线学习可使数据被分批处理。 -
参数学习:
我们对房屋的价格进行假设,假设为房屋价格:
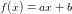
则训练的主要任务就变成了找到参数a、b,一旦学习到了参数,就不再需要原有的数据集。 -
非参数学习:
不对模型过多的假设。
非参数学习也有参数。
5、哲学思考
数据比算法重要?
2001年微软论文中,实验表明只要数据足够多,算法的准确性是相似的。这表明数据非常重要,预测结果依赖大量数据。
算法比数据更重要?
新版的阿尔法GO-zero在围棋比赛中打败阿尔法GO,阿尔法GO-zero具有超强学习算法,并不需要学习以往的棋谱数据,它完全凭借自身的能力,进行强化学习打败阿尔法GO。这说明算法也至关重要。
任意两个的算法,他们的期望性能是相同的。没有觉得的一个算法比另一个算法好,如果脱离具体问题,算法也没有意义。
6、环境的搭建
1、使用JupyterNotebook:
进入anaconda官网:下载3.7版本–>点击download–>windos–>python3.7,下载anaconda后安装,安装教程参考:link ,点击Anaconda Navigator,
安装JupyterNotebook,点击launch,

安装成功后会自动打开默认的浏览器,我使用的是文件是桌面上的test文件夹,所以点击Destktop->test,右上角点击new,python3,创建一个文件,会默认生成一个untitled的文件,点击文件名可以修改文件,保存后可以在桌面上的test文件夹下看到一个后缀名为.ipynb的文件。
2、有时会用到一些更方便的IDE环境,pycharm,下载地址:下载社区版 ,点击tools,pycharm,community,下载安装,安装教程网上也有很多。注意选择anaconda文件夹下的解析器。
关于JupyterNotebook和pycharm的使用网上有很多教程,这里就不细说了。

- 先搞懂这八大基础概念,再谈机器学习入门!
- 【学习笔记】3D图形核心基础精炼版-1:入门概念
- 先搞懂这八大基础概念,再谈机器学习入门
- 【机器学习入门】Andrew NG《Machine Learning》课程笔记之二 :基本概念、代价函数、梯度下降和线性回归
- 先搞懂这八大基础概念,再谈机器学习入门!
- 干货丨八大基础概念带你入门机器学习!
- Go语言笔记一——基础概念以及入门
- 【机器学习入门笔记5:OpenCV像素的基础知识】20190203
- Hadoop基础入门学习笔记(基本概念)
- [机器学习] Coursera ML笔记 - 机器学习基础概念
- 机器学习入门笔记(一):有关概念介绍
- 先搞懂这八大基础概念,再谈机器学习入门!
- (转)先搞懂这八大基础概念,再谈机器学习入门!
- Unity Shader入门精要笔记(八):Unity 的基础光照——概念与理论
- 最新机器学习入门八大基础概念
- 程序员的机器学习入门笔记(一):基本概念介绍
- 机器学习笔记——基础概念汇总
- 机器学习入门-基础琐碎笔记
- 先搞懂这八大基础概念,再谈机器学习入门!
- Java2入门与实例教程笔记-概念,类库,application,applet基础