happen before 原则
并发一直都是程序开发者绕不开的难题,在上一篇文章中我们知道了导致并发问题的源头是 : 多核 CPU 缓存导致程序的可见性问题、多线程间切换带来的原子性问题以及编译优化带来的顺序性问题。
原子性问题我们暂且不谈,Java 中有足够健壮的锁机制来保证程序的原子性,后面学习的重点也是在这方面。今天我们就先来看看 Java 是怎么解决可见性与顺序性问题的。
合理的建议是 按需禁用缓存与编译优化,但是怎么才算是按需禁用呢?这就要具体问题具体分析了。Java 内存模型也规定了 JVM 如何按需提供禁用缓存与编译优化的方法,这些方法就是 volatile、syncronized、final 三个关键字与 happen-before 原则。
-
volatile
volatile 其实是一种稍弱的同步机制,在并发场景下它并不能保证线程安全。
加锁机制既可以保证可见性又可以保证原子性,而 volatile 变量则只能保证可见性。
在 jdk1.5 之前 volatile 给我们最深刻的印象就是 禁用缓存,即每次读写都是直接操作内存(不是 CPU 缓存),从内存中取值。Java 从 jdk1.5 开始对 volatile 进行了优化, 我们先来看下面的例子,再讨论优化了什么和怎么优化的。
假设有线程 A 和线程 B,A 线程调用 write(),将 flag 赋值为 true,B 线程调用 read() ,根据 volatile 定义变量的可见性,B 线程中 flag 为 true 所以会进入if 判断,那么此时的输出 index 的值是多少呢?
class VolatileTest{
int index = 0;
volatile boolean flag = false;
public void write(){
index = 10;
flag = true;
}
public void read(){
if(flag){
System.out.println(index);
}
}
}
这个问题在 jdk1.5 之前,显示的结果可能为 0,也可能为 10,原因在于 CPU 缓存导致的可见性问题,flag 是可以保证可见性,但是 index 却无法保证,当 A 线程执行完写进 CPU 缓存还没有更新的内存时,此时 B 线程读出的 index 值就是 0。
为了解决上述问题,从 jdk1.5 开始对 volatile 修饰的变量进行了优化, 在 jdk1.5 以后 此时 index 输出结果就是 10 。
到底是怎么优化的呢? 答案是 happen-before 原则中的传递性规则。
-
happen before 原则
happen before 并不是字面的英文的意思,想要理解它必须知道 happen before 的含义,它真正的意思是前面的操作对后续的操作都是可见的,比如 A happen before B 的意思并不是说 A 操作发生在 B 操作之前,而是说 A 操作对于 B 操作一定是可见的。
知道了它的意思,我们再来看一下 happen before 原则中与开发相关的几项规则:
-
程序的顺序性规则
这条规则很简单,也符合我们常规的思维,就是说在一个线程中程序的执行顺序,前面的操作对后面的操作是可见的,同样是上面的代码,在执行 write() 方法时,index = 10 对 flag = true 是可见的,如下 :
class VolatileTest{
int index = 0;
volatile boolean flag = false;
public void write(){
index = 10; // index 赋值 对 flag 是可见的
flag = true;
}
public void read(){
if(flag){
System.out.println(index);
}
}
}
-
volatile 变量规则
volatile 修饰的变量,对该变量的写操作一定可见于对该变量的读操作。
同样是上面的代码,A 线程执行 write() 为 flag 变量赋值为 true,B 线程执行 read() 方法,那么此时的 flag 一定为true,与 A B 线程执行顺序无关。
-
传递性
传递性就是 jdk1.5 之后对 volatile 语义的增强。啥叫传递性呢 ?
举个简单的数学比大小的例子,你就明白了。
有 a、b、c 三个数,如果 a > b, b > c, 那么由传递性可知 a > c。
这里的传递性的意思与例子类似, A 操作 happen before 于 B 操作,B 操作 happen before 于 C 操作,那么 A 操作 happen before 于 C 操作。同样是上面的代码,我们来解释下为什么 在 jdk1.5 之后 B 线程执行 read() 方法打印的结果一定为 10 呢?如图:
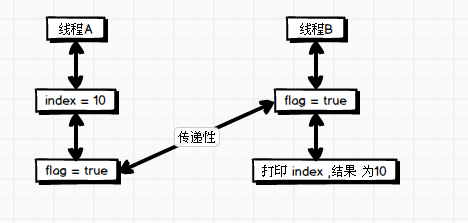
根据第一条程序的顺序性规则可知,A线程中 index = 10 对 flag = true 可见;
根据第二条 volatile 规则可知,flag 使用 volatile 修饰的变量, A 线程 flag 写 对 B 线程 flag 的读可见;
综合以上两条规则:
index = 10 happen before 于 flag 的写 ,
A 线程 flag 的写 happen before 于 B 线程 flag 的读,
根据传递性 , A 线程 对 index 的写 happen before 于 B 线程 对 flag 的读。所以 A 线程对 index 变量的写操作对 B 线程 flag 变量的读操作是可见的,即 B 线程读取 index 的打印结果为 10 。
-
管程中锁的规则
管程是一种通用的同步原语,管程在 java 中指的就是 syncronized。这条规则说的是 线程的解锁 happen before 于对这个线程的加锁。
也就是说线程的解锁对线程的加锁是可见的,那么在一个线程中操作的变量,在这个线程解锁后,根据传递性规则,当另一个线程加锁的时候,就会读到上一个线程对这个变量的操作后的新值。
-
线程的 start 规则
A 线程中调用 B 线程的 start(), 则 start() 操作 happen before 于 B 线程所有操作,也就是说 A 线程调用 start() 操作前对共享变量的赋值,对 B 线程可见,即在 B 线程中能获取 A 对到共享变量操作后的新值。
-
线程的 join 规则
A线程中调用B线程的 join() 操作,如果成功返回 则 B的所有操作对 join() 结果的返回一定是可见的,即在 A 线程能获取到 B 对共享变量操作后的新值。
除了以上列举几条规则,happen before 还有些其他的规则,在开发中不常用到,这里我们就不一一列举了。其实 Java 内存模型大体可以分为两部分,一部分是编写并发程序的开发人员,另一部分是 面向JVM 的实现人员 。当然我们更关注前者,而前者的核心就是 happen before 原则,常用的就是上面我们列举的原则,了解这些也就可以了。
在编译器优化方面使用的最多的就是 final 了, final 修饰变量就是常量,因此编译器可以使劲的优化,在 jdk1.5 以后 Java 内存模型对 final 类型变量的重排进行了约束。现在只要我们提供正确构造函数没有“逸出”,就不会出问题了。
总结:
happen before 原则核心就是可见性,并不是说 一个操作发生在另一个操作前面,它真正要表达的是:前面一个操作的结果对后续操作是可见的。
参考资料 : 《JAVA 并发编程实战》

- 简述Java内存模型的happen before原则
- happen-before原则
- java 8大happen-before原则超全面详解
- java多线程学习(十) happen before 原则
- happen-before原则
- happen-before 原则
- happen-before 原则
- Java 使用 happen-before 规则重庆时时踩源码下载平台出租出售重庆时时踩源实现共享变量的同步操作
- jvm的happens-before原则
- happen-before 规则
- 利用Happen-Before规则分析DCL
- 【Java并发编程】之十六:深入Java内存模型——happen-before规则及其对DCL的分析(含代码)
- 通俗易懂讲解happens-before原则
- Happens-before原则
- Java利用happen-before规则如何实现共享变量的同步操作详解
- 深入Java内存模型:happen-before规则及其对DCL的分析(含代码)
- 【Java并发编程】之十六:深入Java内存模型——happen-before规则及其对DCL的分析(含代码)
- Java 内存模型中的happens-before 原则
- Java并发编程系列之五:happens-before原则
- java并发编程基础--先行发生原则( happens-before)与指令重排序