Python中的相关分析correlation analysis的实现
2019-08-29 15:01
1346 查看
相关分析(correlation analysis)
研究两个或两个以上随机变量之间相互依存关系的方向和密切程度的方法。
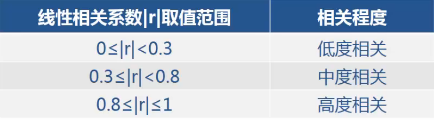
线性相关关系主要采用皮尔逊(Pearson)相关系数r来度量连续变量之间线性相关强度;
r>0,线性正相关;r<0,线性负相关;
r=0,两个变量之间不存在线性关系,并不代表两个变量之间不存在任何关系。
相关分析函数
DataFrame.corr()
Series.corr(other)
函数说明:
如果由数据框调用corr函数,那么将会计算每个列两两之间的相似度
如果由序列调用corr方法,那么只是该序列与传入的序列之间的相关度
返回值:
DataFrame调用;返回DataFrame
Series调用:返回一个数值型,大小为相关度
import numpy import pandas data = pandas.read_csv( 'C:/Users/ZL/Desktop/Python/5.4/data.csv' ) bins = [ min(data.年龄)-1, 20, 30, 40, max(data.年龄)+1 ] labels = [ '20岁以及以下', '21岁到30岁', '31岁到40岁', '41岁以上' ] data['年龄分层'] = pandas.cut( data.年龄, bins, labels=labels ) ptResult = data.pivot_table( values=['年龄'], index=['年龄分层'], columns=['性别'], aggfunc=[numpy.size] File "<ipython-input-1-ae921a24967f>", line 25 aggfunc=[numpy.size] ^ SyntaxError: unexpected EOF while parsing import numpy import pandas data = pandas.read_csv( 'C:/Users/ZL/Desktop/Python/5.4/data.csv' ) bins = [ min(data.年龄)-1, 20, 30, 40, max(data.年龄)+1 ] labels = [ '20岁以及以下', '21岁到30岁', '31岁到40岁', '41岁以上' ] data['年龄分层'] = pandas.cut( data.年龄, bins, labels=labels ) ptResult = data.pivot_table( values=['年龄'], index=['年龄分层'], columns=['性别'], aggfunc=[numpy.size] ) ptResult Out[4]: size 年龄 性别 女 男 年龄分层 20岁以及以下 111 1950 21岁到30岁 2903 43955 31岁到40岁 735 7994 41岁以上 567 886
以上就是本文的全部内容,希望对大家的学习有所帮助

相关文章推荐
- 利用Python进行数据分析_python3实现_pandas入门_相关系数与协方差
- linux路由内核实现分析(二)---FIB相关数据结构
- [转] websocket新版协议分析+python实现 & websocket 通信协议
- 栈和队列数据结构的基本概念及其相关的Python实现
- 用Python实现一个细粒度hadoop作业监控分析工具
- [深度学习]Python/Theano实现逻辑回归网络的代码分析
- 【机器学习算法实现】主成分分析(PCA)——基于python+numpy
- 排序算法—直接插入排序算法分析与实现(Python)
- python等缩进语言的词法分析实现
- python实现词法分析
- Twitter的分布式自增ID算法Snowflake实现分析及其Java、Php和Python版
- python实现bucket排序算法实例分析
- 简介二分查找算法与相关的Python实现示例
- 查找算法—折半查找算法分析与实现(Python)
- 排序算法—快速排序算法分析与实现(Python)
- [Android]使用HorizontalScrollView实现广告栏Banner及相关原理分析
- python实现的AES双向对称加密解密与用法分析
- 一种分析代金券使用分布情况的方法python实现版(下)
- ARM架构kprobe应用及实现分析(9.0 arch_prepare_kprobe平台相关注册)
- 一个简单的语义分析算法:单步算法——Python实现