分库分表中间件-sharding-jdbc学习笔记-基于SpringBoot+TKMybatis搭建
一、前言
常用分库分表的框架或中间件有MyCat和Sharding-JDBC。MyCat是基于中间件的形式,shrrding-jdbc是基于本地jar包的类库。sharding-jdbc属于ShardingSphere体系的一个组件,ShardingSphere体系也有Sharding-Proxy,和MyCat一样,是独立部署的中间件。但sharding-jdbc与其不冲突,今天主要是学习了Sharding-JDBC。现将学习心得记录在这里,方便自己学习和他人参考(估计也不会有人看TAT)。
二、先动手简单写个小demo
(一)数据准备
这里用两个库,一张逻辑表,一个库两张真实表来演示。
sql脚本(基于mysql):
CREATE TABLE `t_order_1` ( `id` bigint(20) NOT NULL, `user_id` bigint(20) NOT NULL, `order_id` bigint(20) NOT NULL, `order_no` varchar(30) NOT NULL, `isactive` tinyint(4) NOT NULL DEFAULT '1', `inserttime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP, `updatetime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
每个库t_order_1和t_order_2各建一张。
(一)引入jar包
maven引入当前最新的jar包:
<dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>sharding-jdbc-core</artifactId> <version>4.0.0-RC1</version> </dependency>
(三)编写真实数据源的方法
采取java配置方式,官方支持javaConfig、yml等配置方式,我这里用的是JavaConfig。
先将数据源信息写入yml:
sharding: datasources: test1: driver-class-name: com.mysql.jdbc.Driver password: 123456 url: jdbc:mysql://localhost:3306/test1?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC&useSSL=false username: root test2: driver-class-name: com.mysql.jdbc.Driver password: 123456 url: jdbc:mysql://localhost:3306/test2?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC&useSSL=false username: root
然后建个配置信息类,保存所有的数据源信息:
@Component
@ConfigurationProperties(prefix = "sharding")
@Data
public class DataSourceInfo {
private Map<String, Map<String,String>> datasources;
}
对应的,创建真实数据源的方法,等会sharding-jdbc会用这些数据源封装为一个统一数据源入口。
public class DataSourceUtil {
public static DataSource createDataSource(String data,DataSourceInfo dataSourceInfo){
DataSourceBuilder dataSourceBuilder = DataSourceBuilder.create();
dataSourceBuilder.url(dataSourceInfo.getDatasources().get(data).get("url"));
dataSourceBuilder.driverClassName(dataSourceInfo.getDatasources().get(data).get("driver-class-name"));
dataSourceBuilder.username(dataSourceInfo.getDatasources().get(data).get("username"));
dataSourceBuilder.password(dataSourceInfo.getDatasources().get(data).get("password"));
DataSource dataSource = dataSourceBuilder.build();
return dataSource;
}
}
(四)配置sharding-JDBC的数据源
/**
* @author chenzhicong
* @time 2019/8/21 16:40
* @description
*/
@Configuration
public class ShardingJdbcConfig {
@Autowired
private DataSourceInfo dataSourceInfo;
@Bean(name = "shardingDataSource")
@Primary
DataSource getShardingDataSource() throws SQLException {
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
//添加t_order表逻辑表的分片规则配置对象
shardingRuleConfig.getTableRuleConfigs().add(getOrderTableRuleConfiguration());
//shardingRuleConfig.getTableRuleConfigs().add(getOrderItemTableRuleConfiguration());
//添加绑定表
//shardingRuleConfig.getBindingTableGroups().add("t_order, t_order_item");
//添加广播表
//shardingRuleConfig.getBroadcastTables().add("t_config");
//设置分库策略
//参数:第一个为分片列名称,第二个分片算法行表达式,需符合groovy语法
shardingRuleConfig.setDefaultDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("user_id", "test${user_id % 2 + 1}"));
//设置分表策略
//这里一般不用行表达式分片策略,因为涉及的逻辑表名有多个,一般自己实现一个标准分片策略
shardingRuleConfig.setDefaultTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("order_id", "t_order_${order_id % 2}"));
return ShardingDataSourceFactory.createDataSource(createDataSourceMap(), shardingRuleConfig, new Properties());
}
private static KeyGeneratorConfiguration getKeyGeneratorConfiguration() {
KeyGeneratorConfiguration result = new KeyGeneratorConfiguration("SNOWFLAKE", "id");
return result;
}
/**
* 获取订单表分片规则配置对象
*/
TableRuleConfiguration getOrderTableRuleConfiguration() {
//第一个参数是逻辑表名称(logicTable),第二个参数是actualDataNodes(真实数据节点),由数据源名 + 表名组成,以小数点分隔(inline表达式)缺省表示使用已知数据源与逻辑表名称生成数据节点
TableRuleConfiguration result = new TableRuleConfiguration("t_order", "test${1..2}.t_order${0..1}");
result.setKeyGeneratorConfig(getKeyGeneratorConfiguration());
return result;
}
/**
* 获取订单商品表分片规则配置对象
*/
TableRuleConfiguration getOrderItemTableRuleConfiguration() {
TableRuleConfiguration result = new TableRuleConfiguration("t_order_item", "test${1..2}.t_order_item${0..1}");
return result;
}
Map<String, DataSource> createDataSourceMap() {
Map<String, DataSource> result = new HashMap<>();
result.put("test1", DataSourceUtil.createDataSource("test1",dataSourceInfo));
result.put("test2", DataSourceUtil.createDataSource("test2",dataSourceInfo));
return result;
}
}
(五)将统一的sharding-jdbc数据源引入mybatis
@Configuration
@MapperScan(basePackages = "com.czc.study.mybatis.dao", sqlSessionFactoryRef = "sessionFactory")
public class SessionFactoryConfig {
@Bean
public SqlSessionFactory sessionFactory(DataSource shardingDataSource) throws Exception {
final SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();
sessionFactory.setDataSource(shardingDataSource);
return sessionFactory.getObject();
}
}
注意了,这里的@MapperScan是tkMybatis的MapperScan注解(不要踩坑了)。
三、sharding-jdbc概念介绍
(一)名词解释
- 数据节点 表示一张真实表。
- 逻辑表 表示逻辑意义上的一张表,对于写业务代码的人来说所有sql都是操作的逻辑表
- 绑定表 分片规则一致的主表和子表。配置时可以指定绑定表,sharding-jdbc将基于绑定表优化查询
(二)分片
分片有库分片和表分片,指的是我们数据在库和表间分布的策略。
sharding-jdbc提供多种分片策略,在配置时用了策略模式,需要传入特定算法来初始化,算法由我们自己实现,提供最大自由度。,包括:
- 标准分片策略
对应的Java类对象是StandardShardingStrategy,可传入的算法对象是PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法,前者是精确分片算法,用于处理分片键in或=的查询关系,后增是范围分片算法,用于处理between and 的查询关系。在配置时,我们需要自己实现。比如精确分片算法的方法是:
String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<T> shardingValue);
其中availableTargetNames代表的是可用的库或表,shardingValue封装的是分片键(携带逻辑表名,字段名、值),该方法实现需要返回库名或者表名,代表数据分布到哪个库或哪个表。后面介绍的算法对象都是类似这样的接口,就不多介绍了。
- 复合分片策略
对应策略类对象ComplexShardingStrategy,提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。对应算法对象ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂。这个也没有实际操作过,就不多介绍了。
- 行表达式分片策略
对应InlineShardingStrategy策略类对象,该策略类初始化有传入分片键和Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。 我们demo中用的就是这个。
- Hint分片策略
对应HintShardingStrategy。通过Hint而非SQL解析的方式分片的策略。对应算法对象HintShardingAlgorithm,主要用于分片字段非SQL决定,而由其他外置条件决定的场景。
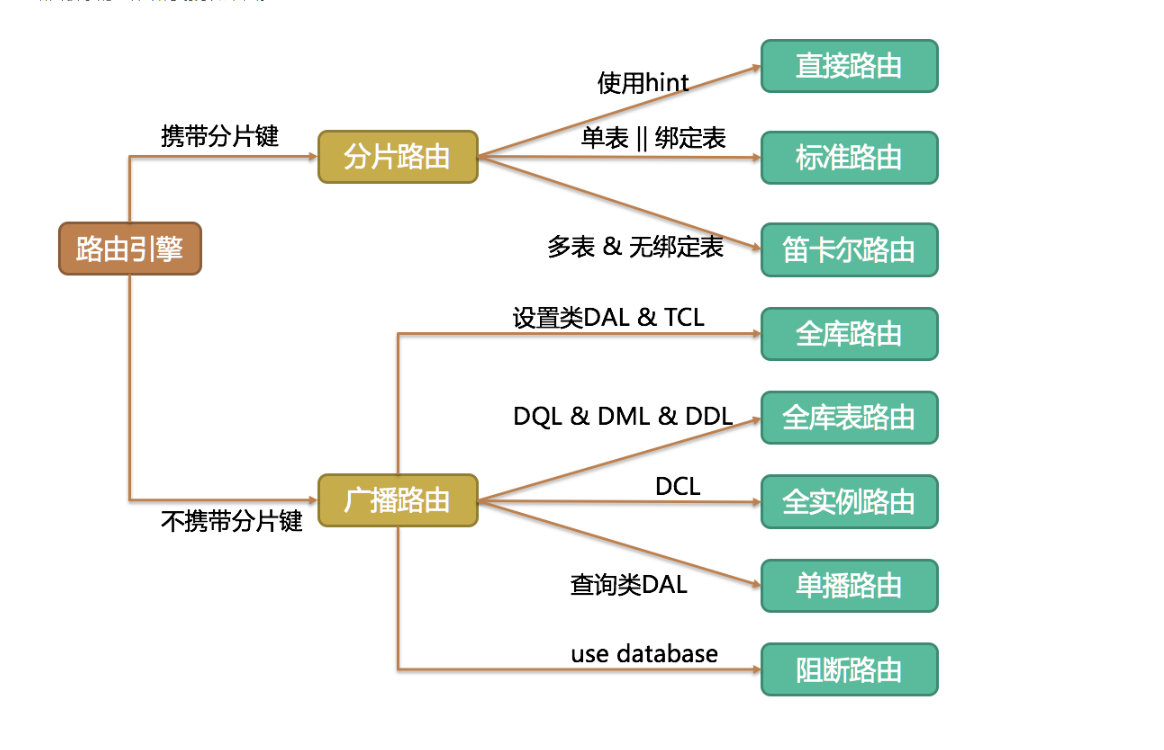
(三)再来看看路由策略
路由策略指的是根据分片策略shrad-jdbc将把原始sql路由到哪些库执行。具体方式有:
- 直接路由,通过Hint(使用HintAPI直接指定路由至库表)方式分片,并且是只分库不分表的前提下将进行直接路由
- 标准路由,不包含关联查询或仅包含绑定表之间关联查询的SQL将进行标准路由,业务需求不变的话,效率是最优的。
- 笛卡尔路由,没有绑定表关系,又有一些级联操作,会触发笛卡尔路由。
比如原始SQL是:
SELECT * FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
如果有绑定键
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2); SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
但没有绑定键的话,不能确定order_id相等表的序号也相等,于是:
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2); SELECT * FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2); SELECT * FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2); SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
-
广播路由,不携带分片键的SQL,将进行广播路由,广播路由分为全库表路由、全实例路由、单播路由、阻断路由,我们只需要了解全库表路由即可,其他的SQL都不属于crud,全库表路由值得是针对一个SQL,sharding-jdbc会在所有库都执行一次。
-
图示:
(四)SQL改写相关功能
针对,逻辑SQL(表示业务代码中写的sql),某些情况sharding-jdbc将会对其进行改写,主要情况有:
- 标识符改写,指的是将逻辑sql中的表名改为真实表名。
- 补列,主要是针对order by和GROUP BY,归并结果之前必须获取分组字段或排序字段,所以改写后的sql查询结果会有分组或排序字段
- 分页修正,对于排序分页,会改写为Limit总是从0开始,获取正确的排序结果,再归并筛选。
- 批量拆分,批量插入时拆不同的SQL到不同的库执行,或In查询时,根据分片策略针对每个库的分片键范围,缩小IN查询条件的范围。
需要注意的是,对于单节点路由,则不会进行改写。
(五)关于归并
对于排序、分组排序的归并不一定将查询结果搞到内存,然后在内存中进行归并,sharding-jdbc有流式分组归并的概念,即每一次从结果集中获取到的数据,都能够通过逐条获取的方式返回正确的单条数据。但对于分组排序的要求必须是SQL的排序项与分组项的字段以及排序类型(ASC或DESC)。
四、小结
关于sharding-jdbc的核心概念和配置demo就总结到这里,大概对其有了一定了解,再总结一下配置的方式首先是先获取到各个真实数据源的datasource对象,然后创建分片规则配置对象ShardingRuleConfiguration,通过分片规则配置对象添加各个逻辑表的分片规则配置对象TableRuleConfiguration(这里可以配置各个TableRuleConfiguration的主键生成策略,可以选择使用用雪花算法),然后添加各个绑定表组,通过传入自己实现的算法配置分片策略(这里需要注意,最好每个表都有相同的字段作为分片键,这样比较好处理-个人看法,可能有可能不对,因为也没有经历过生产实践),然后再通过ShardingDataSourceFactory结合真实数据源创建统一的ShardingDataSource,最后注入到我们自己的持久层框架使用的数据源中就行了。

- SpringBoot+mybatis搭建小程序学习笔记
- 数据库性能优化的五种方案(mycat,基于阿里coba开源的数据库中间件,很容易实现分库分表、主从切换功能。另一个当当网开源的一个库 sharding-jdbc)
- 基于Maven的Springboot项目搭建学习笔记
- 个人学习笔记----基于Spring4.3.1+mybatis+postgresql+maven搭建的个人用调度平台(二)
- 个人学习笔记----基于Spring4.3.1+mybatis+postgresql+maven搭建的个人用调度平台(四)
- sharding-jdbc集成spring+mybatis分表分库
- 个人学习笔记----基于Spring4.3.1+mybatis+postgresql+maven搭建的个人用调度平台(一)
- 个人学习笔记----基于Spring4.3.1+mybatis+postgresql+maven搭建的个人用调度平台(三)
- 解读分库分表中间件Sharding-JDBC
- 解读分库分表中间件Sharding-JDBC
- springMVC学习笔记---day02 springMVC+spring+mybatis整合开发框架搭建
- java 搭建基于springboot的ssm(spring + springmvc + mybatis)的maven项目
- 学习springboot笔记(四)数据访问之mybatis
- 解读分库分表中间件Sharding-JDBC
- 简单权限系统基于shiro-springmvc-spring-mybatis(学习笔记2)
- Springboot学习笔记(六)关于jdbc的增删改查
- JeeFast是一款基于SpringBoot+Mybatis-Plus+Bootstrap+Vue搭建的JAVA WEB快速开发平台
- 解读分库分表中间件Sharding-JDBC
- 学习springboot笔记(四)数据访问之JDBC
- 解读分库分表中间件Sharding-JDBC