mysql中InnoDB锁
mysql中使用比较多的两种引擎是MyISAM和InnoDB
MyISAM使用表级锁。
InnoDB使用行级锁。
表锁:开销小,加锁快;不会出现死锁;锁定力度大,发生锁冲突概率高,并发度最低
行锁:开销大,加锁慢;会出现死锁;锁定粒度小,发生锁冲突的概率低,并发度高
InnoDB
InnoDB与MyISAM的最大不同有两点:一是支持事务(TRANSACTION);二是采用了行级锁。
数据库实现事务隔离的方式,基本上可分为以下两种。
一种是在读取数据前,对其加锁,阻止其他事务对数据进行修改。
另一种是不用加任何锁,通过一定机制生成一个数据请求时间点的一致性数据快照(Snapshot),并用这个快照来提供一定级别(语句级 或事务级)的一致性读取。从用户的角度来看,好像是数据库可以提供同一数据的多个版本,因此,这种技术叫做数据多版本并发控制(MultiVersion Concurrency Control,简称MVCC或MCC),也经常称为多版本数据库。
获取InnoDB行锁争用情况
可以通过检查InnoDB_row_lock状态变量来分析系统上的行锁的争夺情况:
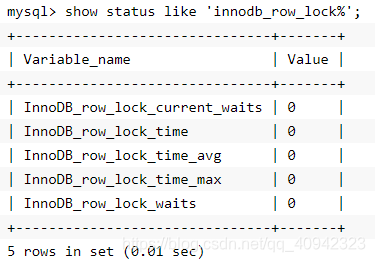
如果发现锁争用比较严重,如InnoDB_row_lock_waits和InnoDB_row_lock_time_avg的值比较高,还可以通过设置InnoDB Monitors来进一步观察发生锁冲突的表、数据行等,并分析锁争用的原因。

设置监视器后,在SHOW INNODB STATUS的显示内容中,会有详细的当前锁等待的信息,包括表名、锁类型、锁定记录的情况等,便于进行进一步的分析和问题的确定。打开监视器以后,默认情况下每15秒会向日志中记录监控的内容,如果长时间打开会导致.err文件变得非常的巨大,所以用户在确认问题原因之后,要记得删除监控表以关闭监视器,或者通过使用“–console”选项来启动服务器以关闭写日志文件。
InnoDB的行锁模式及加锁方法
InnoDB实现了以下两种类型的行锁。
共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。
排他锁(X):允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享读锁和排他写锁。另外,为了允许行锁和表锁共存,实现多粒度锁机制,InnoDB还有两种内部使用的意向锁(Intention Locks),这两种意向锁都是表锁。
意向共享锁(IS):事务打算给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的IS锁。
意向排他锁(IX):事务打算给数据行加行排他锁,事务在给一个数据行加排他锁前必须先取得该表的IX锁。
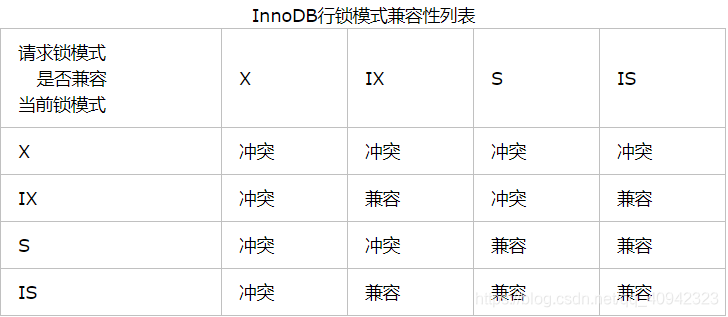
如果一个事务请求的锁模式与当前的锁兼容,InnoDB就将请求的锁授予该事务;反之,如果两者不兼容,该事务就要等待锁释放。
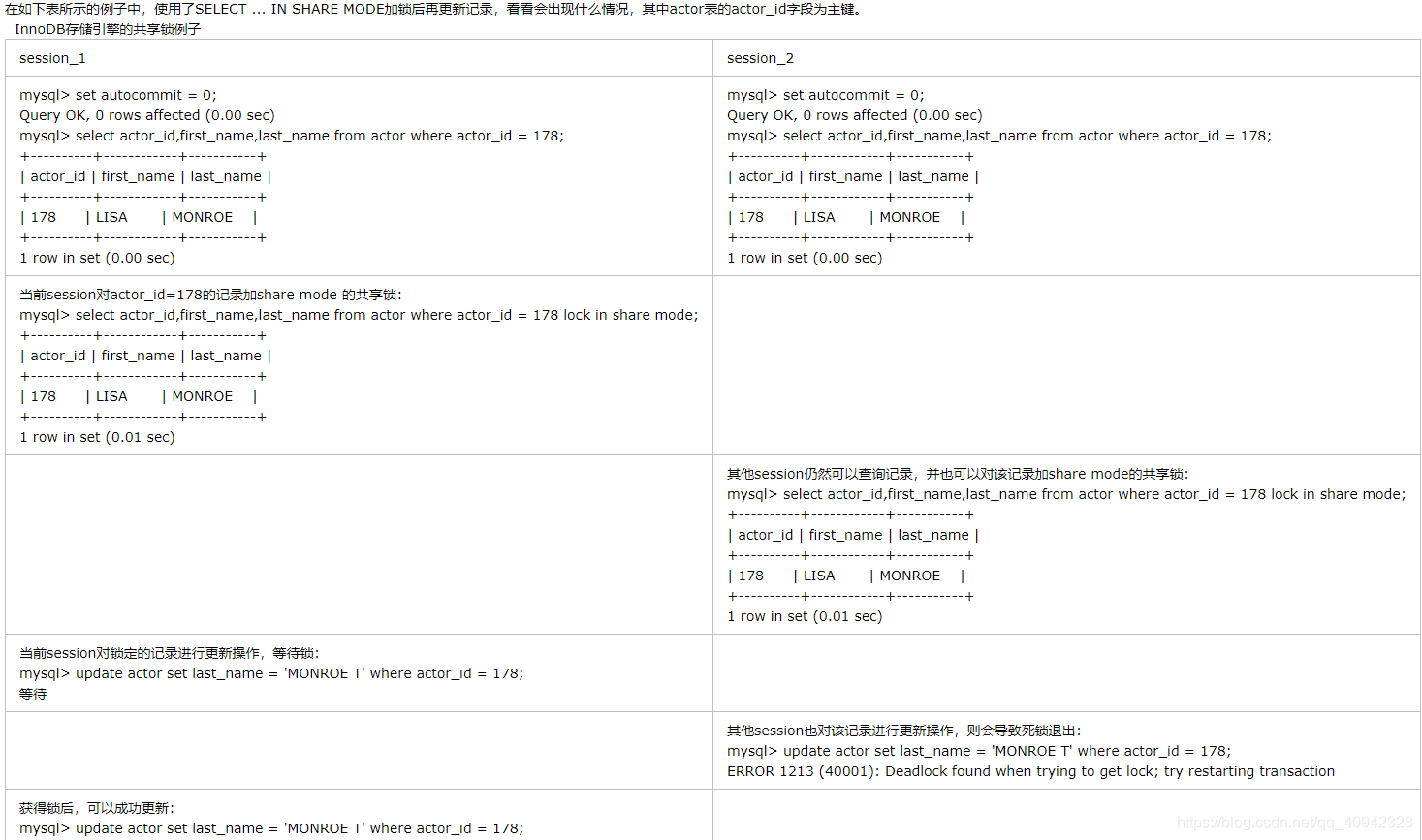
意向锁是InnoDB自动加的,不需用户干预。对于UPDATE、DELETE和INSERT语句,InnoDB会自动给涉及数据集加排他锁(X);对于普通SELECT语句,InnoDB不会加任何锁;事务可以通过以下语句显示给记录集加共享锁或排他锁。
共享锁(S):SELECT * FROM table_name WHERE … LOCK IN SHARE MODE。
排他锁(X):SELECT * FROM table_name WHERE … FOR UPDATE。

InnoDB行锁实现方式
InnoDB行锁是通过给索引上的索引项加锁来实现的,这一点MySQL与Oracle不同,后者是通过在数据块中对相应数据行加锁来实现的。InnoDB这种行锁实现特点意味着:只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁!
(1)在不通过索引条件查询的时候,InnoDB确实使用的是表锁,而不是行锁。
在如下所示的例子中,开始tab_no_index表没有索引:

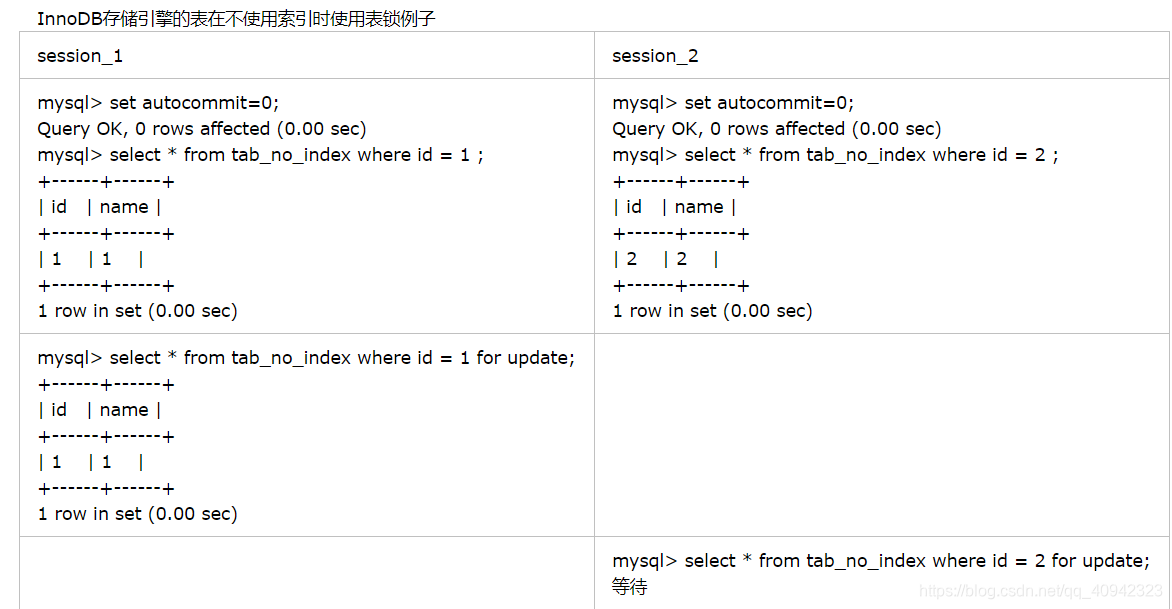
在如上表所示的例子中,看起来session_1只给一行加了排他锁,但session_2在请求其他行的排他锁时,却出现了锁等待!原因就是在没有索引的情况下,InnoDB只能使用表锁。当我们给其增加一个索引后,InnoDB就只锁定了符合条件的行,如下表所示。
创建tab_with_index表,id字段有普通索引:

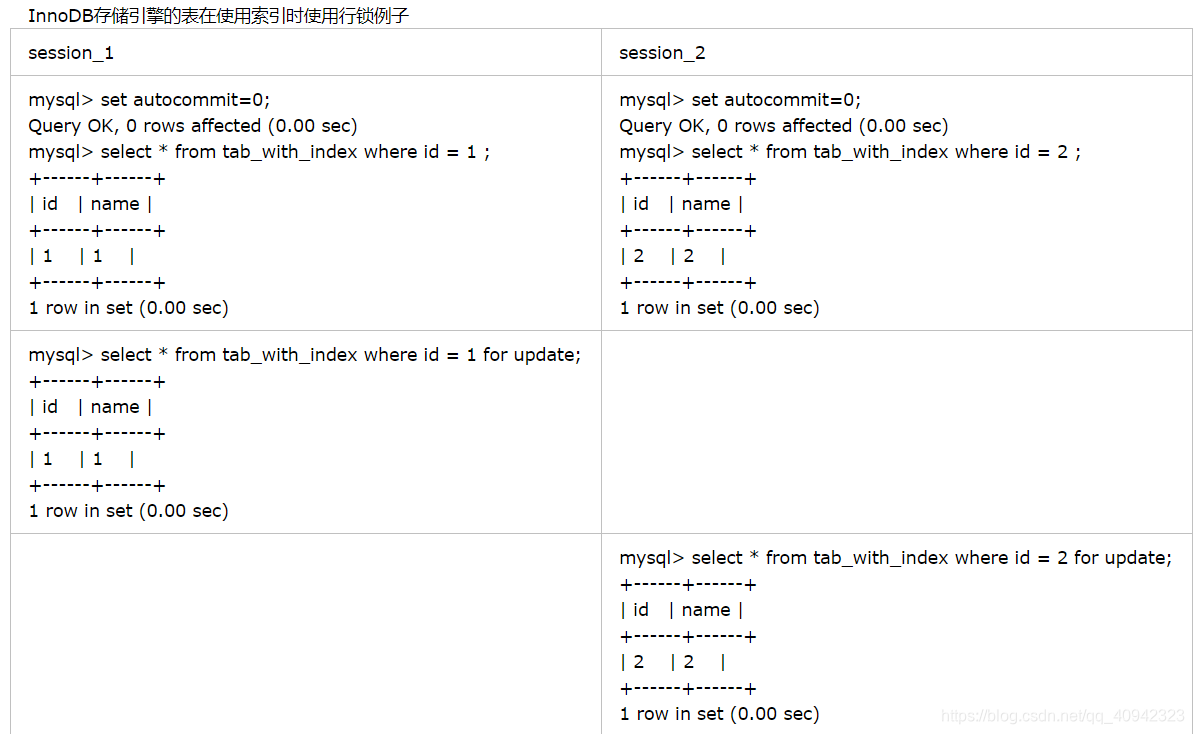
由于MySQL的行锁是针对索引加的锁,不是针对记录加的锁,所以虽然是访问不同行的记录,但是如果是使用相同的索引键,是会出现锁冲突的。应用设计的时候要注意这一点。
在如下表所示的例子中,表tab_with_index的id字段有索引,name字段没有索引:

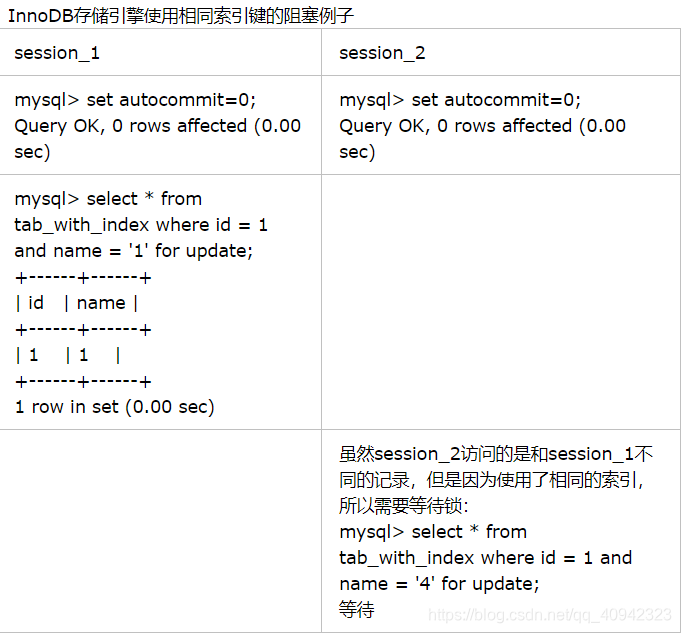
当表有多个索引的时候,不同的事务可以使用不同的索引锁定不同的行,另外,不论是使用主键索引、唯一索引或普通索引,InnoDB都会使用行锁来对数据加锁。
在如下表所示的例子中,表tab_with_index的id字段有主键索引,name字段有普通索引:


即便在条件中使用了索引字段,但是否使用索引来检索数据是由MySQL通过判断不同执行计划的代价来决定的,如果MySQL认为全表扫描效率更高,比如对一些很小的表,它就不会使用索引,这种情况下InnoDB将使用表锁,而不是行锁。因此,在分析锁冲突时,别忘了检查SQL的执行计划,以确认是否真正使用了索引。
在下面的例子中,检索值的数据类型与索引字段不同,虽然MySQL能够进行数据类型转换,但却不会使用索引,从而导致InnoDB使用表锁。通过用explain检查两条SQL的执行计划,我们可以清楚地看到了这一点。
例子中tab_with_index表的name字段有索引,但是name字段是varchar类型的,如果where条件中不是和varchar类型进行比较,则会对name进行类型转换,而执行的全表扫描。

间隙锁(Next-Key锁)
当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”,InnoDB也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁(Next-Key锁)。

恢复和复制的需要,对InnoDB锁机制的影响
MySQL通过BINLOG录执行成功的INSERT、UPDATE、DELETE等更新数据的SQL语句,并由此实现MySQL数据库的恢复和主从复制(可以参见本书“管理篇”的介绍)。MySQL的恢复机制(复制其实就是在Slave Mysql不断做基于BINLOG的恢复)有以下特点。
l 一是MySQL的恢复是SQL语句级的,也就是重新执行BINLOG中的SQL语句。这与Oracle数据库不同,Oracle是基于数据库文件块的。
l 二是MySQL的Binlog是按照事务提交的先后顺序记录的,恢复也是按这个顺序进行的。这点也与Oralce不同,Oracle是按照系统更新号(System Change Number,SCN)来恢复数据的,每个事务开始时,Oracle都会分配一个全局唯一的SCN,SCN的顺序与事务开始的时间顺序是一致的。
从上面两点可知,MySQL的恢复机制要求:在一个事务未提交前,其他并发事务不能插入满足其锁定条件的任何记录,也就是不允许出现幻读,这已经超过了ISO/ANSI SQL92“可重复读”隔离级别的要求,实际上是要求事务要串行化。这也是许多情况下,InnoDB要用到间隙锁的原因,比如在用范围条件更新记录时,无论在Read Commited或是Repeatable Read隔离级别下,InnoDB都要使用间隙锁,但这并不是隔离级别要求的,有关InnoDB在不同隔离级别下加锁的差异在下一小节还会介绍。
另外,对于“insert into target_tab select * from source_tab where …”和“create table new_tab …select … From source_tab where …(CTAS)”这种SQL语句,用户并没有对source_tab做任何更新操作,但MySQL对这种SQL语句做了特别处理。先来看如下表的例子。
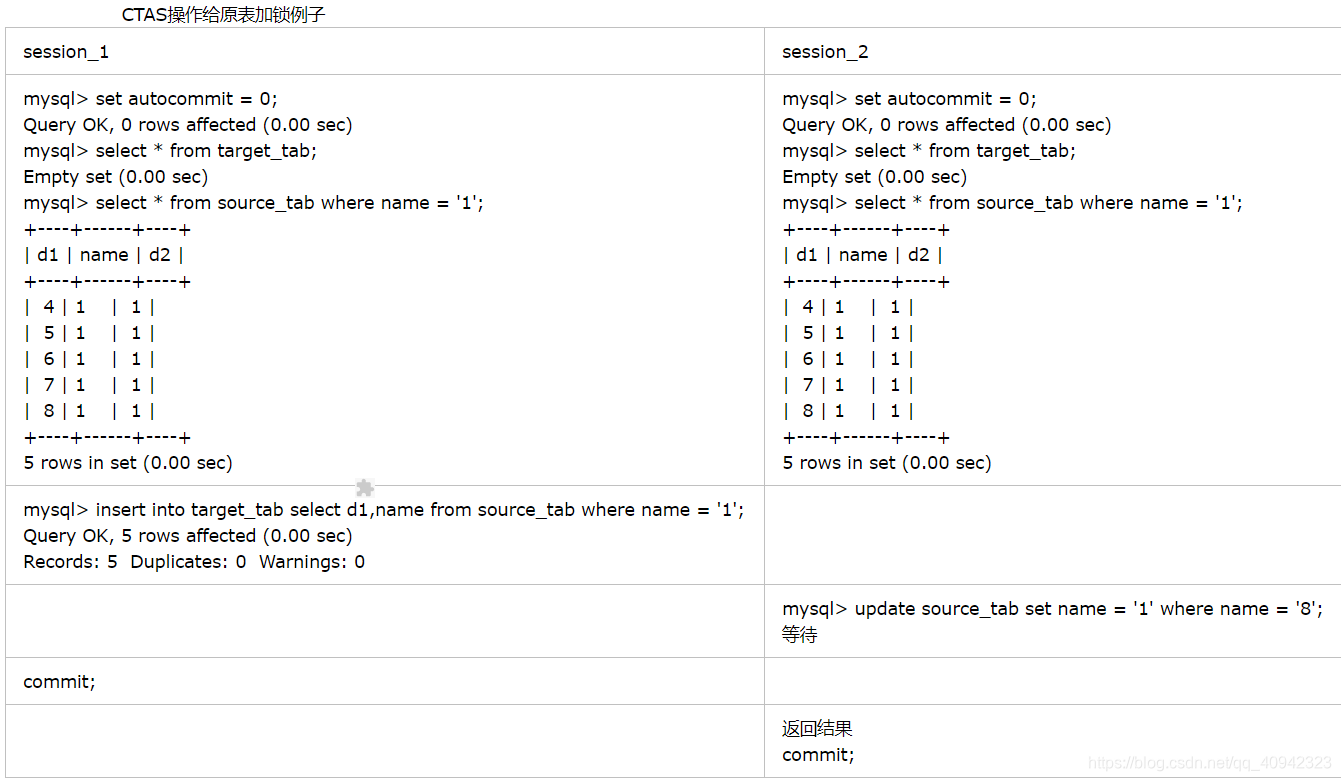
在上面的例子中,只是简单地读 source_tab表的数据,相当于执行一个普通的SELECT语句,用一致性读就可以了。ORACLE正是这么做的,它通过MVCC技术实现的多版本数据来实现一致性读,不需要给source_tab加任何锁。我们知道InnoDB也实现了多版本数据,对普通的SELECT一致性读,也不需要加任何锁;但这里InnoDB却给source_tab加了共享锁,并没有使用多版本数据一致性读技术!
MySQL为什么要这么做呢?其原因还是为了保证恢复和复制的正确性。因为不加锁的话,如果在上述语句执行过程中,其他事务对source_tab做了更新操作,就可能导致数据恢复的结果错误。为了演示这一点,我们再重复一下前面的例子,不同的是在session_1执行事务前,先将系统变量 innodb_locks_unsafe_for_binlog的值设置为“on”(其默认值为off),具体结果如下表所示。

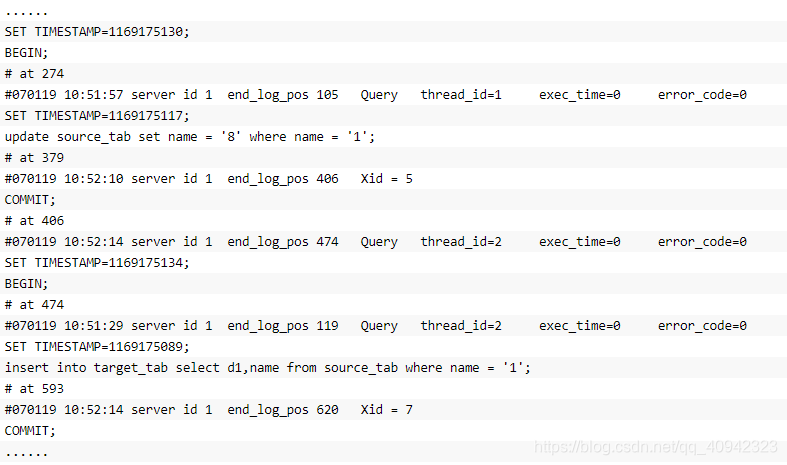
可以发现,在BINLOG中,更新操作的位置在INSERT…SELECT之前,如果使用这个BINLOG进行数据库恢复,恢复的结果与实际的应用逻辑不符;如果进行复制,就会导致主从数据库不一致!
通过上面的例子,我们就不难理解为什么MySQL在处理“Insert into target_tab select * from source_tab where …”和“create table new_tab …select … From source_tab where …”时要给source_tab加锁,而不是使用对并发影响最小的多版本数据来实现一致性读。还要特别说明的是,如果上述语句的SELECT是范围条件,InnoDB还会给源表加间隙锁(Next-Lock)。
因此,INSERT…SELECT…和 CREATE TABLE…SELECT…语句,可能会阻止对源表的并发更新,造成对源表锁的等待。如果查询比较复杂的话,会造成严重的性能问题,我们在应用中应尽量避免使用。实际上,MySQL将这种SQL叫作不确定(non-deterministic)的SQL,不推荐使用。
如果应用中一定要用这种SQL来实现业务逻辑,又不希望对源表的并发更新产生影响,可以采取以下两种措施:
一是采取上面示例中的做法,将innodb_locks_unsafe_for_binlog的值设置为“on”,强制MySQL使用多版本数据一致性读。但付出的代价是可能无法用binlog正确地恢复或复制数据,因此,不推荐使用这种方式。
二是通过使用“select * from source_tab … Into outfile”和“load data infile …”语句组合来间接实现,采用这种方式MySQL不会给source_tab加锁。
什么时候使用表锁
对于InnoDB表,在绝大部分情况下都应该使用行级锁,因为事务和行锁往往是我们之所以选择InnoDB表的理由。但在个别特殊事务中,也可以考虑使用表级锁。
第一种情况是:事务需要更新大部分或全部数据,表又比较大,如果使用默认的行锁,不仅这个事务执行效率低,而且可能造成其他事务长时间锁等待和锁冲突,这种情况下可以考虑使用表锁来提高该事务的执行速度。
第二种情况是:事务涉及多个表,比较复杂,很可能引起死锁,造成大量事务回滚。这种情况也可以考虑一次性锁定事务涉及的表,从而避免死锁、减少数据库因事务回滚带来的开销。
当然,应用中这两种事务不能太多,否则,就应该考虑使用MyISAM表了。
在InnoDB下,使用表锁要注意以下两点。
(1)使用LOCK TABLES虽然可以给InnoDB加表级锁,但必须说明的是,表锁不是由InnoDB存储引擎层管理的,而是由其上一层──MySQL Server负责的,仅当autocommit=0、innodb_table_locks=1(默认设置)时,InnoDB层才能知道MySQL加的表锁,MySQL Server也才能感知InnoDB加的行锁,这种情况下,InnoDB才能自动识别涉及表级锁的死锁;否则,InnoDB将无法自动检测并处理这种死锁。有关死锁,下一小节还会继续讨论。
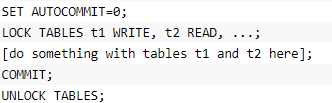
(2)在用 LOCK TABLES对InnoDB表加锁时要注意,要将AUTOCOMMIT设为0,否则MySQL不会给表加锁;事务结束前,不要用UNLOCK TABLES释放表锁,因为UNLOCK TABLES会隐含地提交事务;COMMIT或ROLLBACK并不能释放用LOCK TABLES加的表级锁,必须用UNLOCK TABLES释放表锁。正确的方式见如下语句:
例如,如果需要写表t1并从表t读,可以按如下做:

- 浅谈Mysql之InnoDB引擎
- mysql 索引长度tips innodb和myisam引擎
- 关于mysql innodb 如何保存大对象(BLOB等),最强解析
- mysql innodb 性能优化
- mysql 的innodb和myisam数据库引擎的认识
- mysql中engine=innodb和engine=myisam的区别
- MySQL提示The InnoDB feature is disabled需要开启InnoDB的解决方法
- 剖析Mysql的InnoDB索引
- [MySQL生产环境] Innodb存储引擎内存报警问题处理过程
- MySql中启用InnoDB数据引擎的方法
- MySQL的InnoDB索引原理详解
- 【mysql+xampps】Operation not allowed when innodb_forced_recovery > 0
- MySQL InnoDB四个事务级别 与 脏读、不重复读、幻读
- Mysql中MyISAM引擎和InnoDB引擎的比较
- MySQL中MyISAM与InnoDB区别及选择
- mysql Innodb simple optimization
- Mysql InnoDB锁
- MySQL innodb_fast_shutdown参数讲解
- [MySQL] InnoDB三大特性之 - 插入缓冲
- MySQL innodb_lock_wait 锁等待