SpringBoot整合Spring Data Jpa(快速入门,自定义查询)
- 1.Spring Data Jpa是什么?
- 答:我也不知道。
- 2.Spring Data Jpa可以做什么?
- 答:我还是不知道。
- 3.为什么使用Spring Data Jpa?
- 答:不是很清楚
- 4.那你能干嘛?
- 答:我只想说一下怎么快速上手Jpa
那么请开始你的表演
- 1.快速搭建环境,和简单查询
- 1-1.加入Jpa依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency>
- 1-2.加入相关配置(数据库自己改)
server.port=80 spring.datasource.url=jdbc:mysql://127.0.0.1:3306/m5?useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai&useSSL=false&allowPublicKeyRetrieval=true spring.datasource.username=root spring.datasource.password=root #Jpa的配置 有兴趣可以百度一个ddl-auto 这是对数据库操作的,有创建,更新等等,,, #spring.jpa.hibernate.ddl-auto=create-drop #更新数据库 spring.jpa.hibernate.ddl-auto=update
- 1-3.创建一个实体类
@Data
@Entity
public class MyOrder {
@Id //数据库id
Long id; //数据库主键
Boolean isDispose; //是否处理
String selectFrom; //库存组织
String departmaent; //部门
@Column(name = "warehouse",unique = true,nullable=false) //数据库指定名称,不能重复,且不能为空
String warehouse; //仓库
Date outTime; //出库时间
...
}
@Data:lombok插件,建华代码
@Entity:标注此类为实体类,根据我们的配置文件配置会进行对数据库的更新或者创建等
@Column:标注在实体类属性上,还有其他属性等待老铁们自行发觉
另外更多的属性的注解老铁们可以百度,比如主键自增啥的。
- 1-4.创建一个接口,继承已经定义好的JpaRepository,MongoRepository,CrudRepository,Repository等(接口可以多继承,当然继承JpaRepository基本上就差不多了)
//我们创建一个接口继承JpaRepository<T, ID>
//其中T指的是我们刚那个实体类,ID指的是我们实体类的主键的类型
//当然我们可以多继承,比如上面那几个,Repository是根
public interface MyOrderRepo extends JpaRepository<MyOrder,Long> {
}
好了这样我们就可以使用MyOrderRepo 进行简单的CRUD(增删改查)操作了,但是有人说,我这个接口不是什么都没写吗?怎么进行增删改查?
我没写,但是并不代表我继承的接口没写哦!老铁们可以点进JpaRepository进行查看,里面为我们写好了常见的增删改查操作,比如save,saveAll,findAll,findAllById,自己点进去看一下就明白了,到时候我们只需要调用父类的接口就可以完成简单的增删改查。
- 1-5.开始使用接口完成增删改
@Service
public class MyOrderServiceImpl implements MyOrderService {
//注入我们刚刚写好的接口 这里的service 可以自己创一个 这个跟主题无关,我就不累述
@Autowired
private MyOrderRepo myOrderRepo;
//新增一个MyOrder
public void saveOrder(MyOrder myOrder){
//调用save方法 可以拿到刚新增的数据
MyOrder save = myOrderRepo.save(myOrder);
}
//新增一个MyOrder
public void saveOrders(List<MyOrder > myOrders){
//调用saveAll方法 可以拿到刚新增的数据
List<MyOrder > saves = myOrderRepo.saveAll(myOrders);
}
//根据id查询
public void findById(Long id){
//因为返回值是Optional<T> 所以要调用get()
MyOrder myOrder = myOrderRepo.findById(id).get();
}
//根据id删除
public void deleteById(Long id){
//因为返回值是Optional<T> 所以要调用get()
myOrderRepo.deleteById(id);
}
}
因为没有提供关于update的接口,所以我们还需要自己一会来自己写语句进行执行update语句,以上就是简单的使用增加,查询,和删除,其中还有很多的方法需要老铁们自己发掘。
因为上面简单的一些CRUD语句显然是不满足我们的业务需求的,那这个时候怎么办呢?那当然是自定义接口使用啦
- 2.自定义接口,实现更复杂的查询
- 2-1.请参考1-4的,创建一个接口,并继承一些借口
//这里我们就不多说了哈 之所以前面要使用这种方式,是因为后面会用到
//因为一个项目不可能是他提供的那些接口就能解决的,所以接口迟早要创建
public interface MyOrderRepo extends JpaRepository<MyOrder,Long> {
//好了我们可以在这里自定义接口啦
//根据isDispose(MyOrder中的字段) 来查询出相关的MyOrder
//这样我们就可以在我们的serviceImpl层调用findByIsDispose这个接口了
MyOrder findByIsDispose(@Param("isDispose")Boolean isDispose);
//这是分页查询 调用这个方法就会进行分页查询,默认页数是0,一页显示数是20
Page<MyOrder> findAll(Pageable pageable);
//一下代码是写在service中的 这里为了偷懒
//这就是分页需要的参数,第一个参数page是第几页,默认为0,size是一页显示的数据,默认为20
//sort,是排序方式,ASC|DESC 两种排序方式
Pageable pageable = PageRequest.of(0,20, Sort.Direction.ASC);
//这里就调用了我们刚到分页
myOrderRepo.findAll(pageable);
}
这里有疑问的小伙伴们又有问题了,那就是我还是没写sql啊,他怎么知道我需要的是根据isDispose进行查询?
其实我这里命名是有规范的,之所以能查询出来,那是因为我在按照他们的规则进行命名,他们当然能识别啦,具体的关键字可以参考下面这个图,可以以百度:Jpa关键字
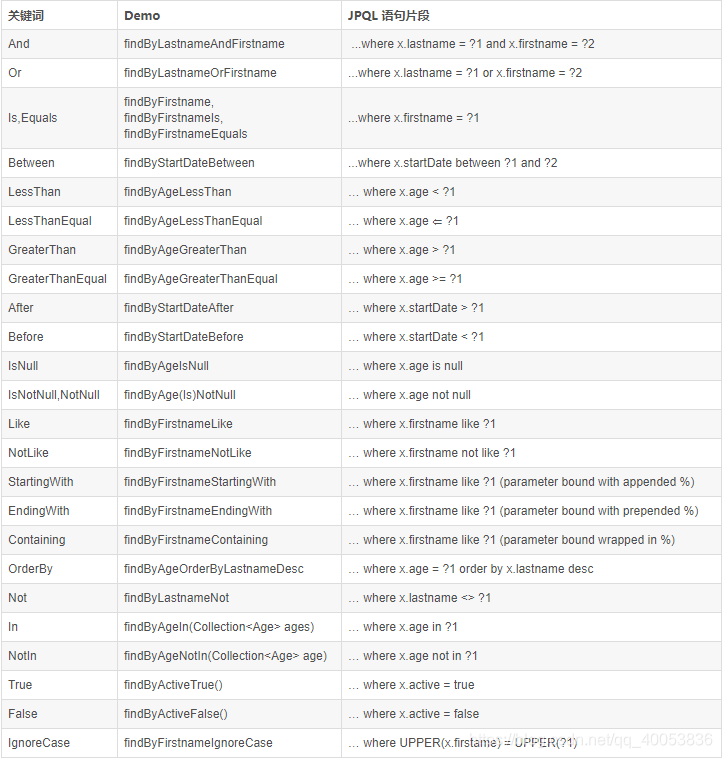
到了这里我们就基本上把自定义接口,和使用接口和分页说完了,自定义可以根据上面的图片的关键字进行自定义
但是有小伙伴问了,我想自己写sql语句咋办。
答案是可以的,接下来我们就进入自己写sql环节
- 3.自己定义sql语句
- 3-1.使用 @Query注解进行自定义sql
//同样的 我们还需要定义一个接口参考1-4
public interface MyOrderRepo extends JpaRepository<MyOrder,Long>{
//1.没有参数直接查询
@Query(value = "select * from my_order",nativeQuery = true)
List<MyOrder> getAll();
//2.sql语句获取参数方式 ?1 表示第一个参数 ?2 表示第二个参数,这里只写一个
//使用 ? 的方式进行获取参数就可以不使用 @Param 注解指定名称
@Query(value = "select * from my_order where id = ?1",nativeQuery = true)
MyOrder getMyOrderById(@Param("id")Long id);
//3.sql语句入参方式 使用 @Param 指定名称直接按照名获取 这里演示是departmaent 所以使用 :departmaent即可
//如果多个参数还是使用 :+@Param里面的值即可 如:@Param("xxx") 那么sql取值的时候就应该是::xxx
@Query(value = "select * from my_order where departmaent = :departmaent",nativeQuery = true)
MyOrder getMyOrderBydepartmaent(@Param("departmaent")String departmaent);
//4.1.如果参数是实体类(也不一定是,这里是用的接口指定的实体类,不是指定的实体类也是这样使用,但是接口指定实体类还有一种,看4.2)
//第一种::#{#xxx1.xxx2} 其中xxx1是@Param("myOrder")中指定的名称 xxx2就是该实体类的字段名称
@Query(value = "select * from my_order where departmaent = :#{#myOrder.test}",nativeQuery = true)
MyOrder newMyOrderBydepartmaent(@Param("myOrder")MyOrder myOrder);
//4.2.如果参数实体类是本接口指定的实体类,如MyOrder
//第二种:?#{[0]} 这里面的 [0]指的是实体类中的第0个属性,
//或者可以写成?#{myOrder.emailAddress,但是这里的myOrder是在创建MyOrder实体类的时候使用@Entity(name="myOrder")指定的
//这里4.2完全是一种拓展,其实使用4.1的方式不管是不是本接口指定的实体类参数都可以完成sql语句参数的绑定
@Query(value = "select * from my_order where departmaent = :#{#test}",nativeQuery = true)
MyOrder newMyOrderBydepartmaent();
//实战 原始分页 并且格式化时间进行判断 查询
//根据时间查询 并且分页
@Query(value = "SELECT * FROM my_order WHERE is_dispose = 0 AND DATE_FORMAT( out_time, '%Y-%m-%d' ) " +
"= :#{#myOrderParam.outTime} LIMIT :#{#myOrderParam.curPage} , :#{#myOrderParam.pageNum}",nativeQuery = true)
List<MyOrder> getAllMyOrderByDepartmaentAndOutTime(@Param("myOrderParam")MyOrderParam myOrderParam);
}
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
这一部分 推荐一定要好好看一下代码中的注释
这一部分完成了我想就基本上满足很大一部分需求了把,在自定义接口自己写sql语句的时候的名称就可以随便自己定义了,因为我们已经绑定了自己执行的sql语句了,在绑定sql语句的时候nativeQuery = true标识在本地执行sql语句,推荐还是所有的都加上
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
另外一定要记得在自己写update语句和delete的sql语句的时候一定要加上 @Modifying 注解
好了到了这里我想好好研究一下就基本上能对Jpa上手使用了,另外推荐大家也可以去官方文档看看
~~谢谢大家的观看
Spring Data Jpa官网:https://docs.spring.io/spring-data/jpa/docs/2.1.10.RELEASE/reference/html/#jpa.query.spel-expressions

- spring-data-jpa快速入门(二)——简单查询
- SpringBoot整合SpringData JPA入门到入坟
- springboot 入门教程(6)--- 整合Spring data JPA实现CRUD(附源码)
- spring-data-jpa快速入门(一)——整合阿里Druid
- Spring boot data JPA 自定义JPQL语句,以及PagingAndSortingRepository接口实现分页查询
- 【系统学习SpringBoot】再遇Spring Data JPA之JPA应用详解(自定义查询及复杂查询)
- springboot整合spring data jpa 动态查询
- springBoot入门总结(三)整合SpringDataJPA
- Spring Boot Spring Data Jpa全解之分页特殊查询
- SpringBoot入门-6(利用jpa连接hibernate,并进行生成表,对表的增加,删除,查询操作)
- SpringBoot入门-快速整合Mybatis
- Spring Data Jpa 自定义属性查询规则
- SpringDataJPA快速入门
- springboot+maven+springdata jpa +querydsl快速实现增删改查分页
- SpringBoot简单整合SpringDataJpa
- Spring Boot1.52 Spring Security Spring Data Jpa 整合
- Spring Data JPA 快速入门
- 入门整合案例(SpringBoot+Spring-data-elasticsearch) ---- (指定分词器)
- springboot整合spring data jpa
- Spring Data JPA 自定义查询