【Redis笔记】一起学习Redis | 聊聊Redis的内存淘汰LRU算法?
 版权声明:署名,允许他人基于本文进行创作,且必须基于与原先许可协议相同的许可协议分发本文 (Creative Commons)
版权声明:署名,允许他人基于本文进行创作,且必须基于与原先许可协议相同的许可协议分发本文 (Creative Commons)
一起学习Redis | 聊聊Redis的LRU内存淘汰算法?
如果觉得对你有帮助,能否点个赞或关个注,以示鼓励笔者呢?!博客目录 | 先点这里
学习Redis的内存淘汰算法之前,我们可以先了解Redis的数据过期删除策略
- 前提概要 常见问题
- 为什么需要内存淘汰算法?
-
Redis提供的六种内存淘汰策略
-
Java版本
-
Redis的LFU内存淘汰算法
前提概要
常见问题
- Redis的过期策略有哪些?
- 聊一聊Redis的内存淘汰算法?
- 手写一个LRU代码实现?
- 我插入到Redis中的数据怎么没啦?
- 我明明给Redis的数据设置了过期时间,时间到了,为什么那些数据还占用着内存?
为什么需要内存淘汰算法?
讲一个小场景
一名开发人员经常吐槽Redis有Bug,说他们的生产环境中的Redis经常会丢掉一些数据。大概就是插进Redis没多久,再查就不见了,很不靠谱。这样的问题不是Redis不靠谱,而是这名开发人员没有意识到内存存储是有上限的,他们生产环境的Redis所存储的数据过多,已经超过了配置的内存大小,所以正在执行内存淘汰算法呢。
为什么要内存淘汰算法
我们知道,内存读写速度快,非常好用,但是就是贵,所以内存空间是宝贵的。而我们的Redis是基于内存的的存储系统,所以也会有一个内存存储空间的上限。并不是说你想用多少就多少的,比如你的Redis中的数据最多存储16G,此时你要是往里写入了20G的数据,会发生什么?那自然是有选择的从这20G数据从挑选出16G进行存储,多的就没办法了,这是物理限制。那么怎么去挑选呢?该淘汰那些数据呢?这就涉及到内存淘汰算法啦
Redis的内存淘汰算法
Redis提供的六种内存淘汰策略
当我们的数据实际内存大小超出了Redis所允许的最大内存大小时,Redis提供了几种可选的内存淘汰策略(
maxmemory-policy)。
noeviction
对外停止提供写服务,只允许读,删除等操作进行。保证已有数据不丢失,但影响了写服务的可用性。这是默认的淘汰策略volatile-lru
从有过期时间的key中淘汰最少使用的key。既认为有过期时间的数据,不如没有过期时间的数据重要volatile-ttl
从有过期时间的key中淘汰ttl时间还剩最少的key, 既越快过期的优先淘汰volatile-random
从有过期时间的key中随机淘汰数据allkeys-lru
从所有key中,执行lru策略,淘汰最少使用的keyallkeys-random
从所有key中,执行random策略,随机淘汰数据
说白了就是分为三大类,停止服务,从有过期时间的数据中淘汰,从所有数据中淘汰, 具体又分为三种策略
lru
淘汰最少使用的数据ttl
淘汰寿命还剩最少的数据random
随机淘汰数据
说说LRU算法
(一) 普通的LRU淘汰算法
我们知道LRU算法是淘汰最少使用的数据,怎么我们怎么知道哪些数据是最少使用的呢?
- LRU算法的实现,需要一个
字典
和一个有序链表
进行组合,有点类似Redis的zset - 字典是用来存储数据的,链表是根据最近访问来对数据进行排序的,一端是最近访问的,另一端是最久访问的,比如链尾是最近访问,链头是最久访问
- 链表中的元素按照一定的顺序进行排序。当空间满的时候,会踢掉链头的元素。当字典的某个元素被访问,则它会从链表的原来位置移动到链表尾部。

所以我们知道了,位于链表头部的元素就是没这么重要的元素,毕竟都这么久没被访问了,优先淘汰它。位于链尾的元素属于最近才刚被访问的元素,算是热点数据,所以暂时不会淘汰它
(二) 近似LRU淘汰算法
虽然LRU淘汰算法很棒,但是Redis所使用的LRU算法并非我们通常所说的LRU算法,而是一种近似LRU算法。这种近视LRU算法的实现原理跟LRU算法不同,是以别的实现原理实现的一个结果接近LRU算法的算法,所以叫
近似LRU算法。
- 为什么Redis不直接使用通常意义的LRU算法呢? 因为通常LRU算法需要消耗大量的额外内存,需要对现有的数据结构进行较大的改造。而近似LRU算法相对简单,允许基于Redis现有的数据结构,使用
随机采样法
来淘汰元素。 - Redis为了实现近似LRU算法,给每个key增加了一个额外的24bit小字段,用来记录该key最后一次被访问的时间戳、
- 近似LRU算法会根据具体的Redis淘汰策略,从有过期时间的数据或全部数据中,随机采用n个数据,采用淘汰掉最旧的数据。依次循环,直到Redis内存使用情况处于正常范围。
所以我们知道了,Redis实际的LRU算法是一种在结果上模拟出LRU算法样子的近似LRU算法。其淘汰数据所删除的删除策略是
惰性删除。不同于过期时间的删除策略(
集中删除 + 惰性删除)
什么是异步删除?
我们都知道Redis是单线程模型,但实际上Redis内部并非真的只有一个Redis线程,而是一个主线程执行通常的业务操作,但它还会有好几个异步线程专门做一些耗时的操作
删除指令
del会直接释放对象的内存,大部分情况下,这个指令非常快,没有明显延迟。不过如果被删除的key是一个大对象,比如一个包含了百万元素的hash或set。那么这样的删除就会导致单线程卡顿了。所以Redis为了解决类似的问题,在4.0版本引入了unlink指令,它能对删除操作进行异步处理,丢给后台线程来异步回收内存。
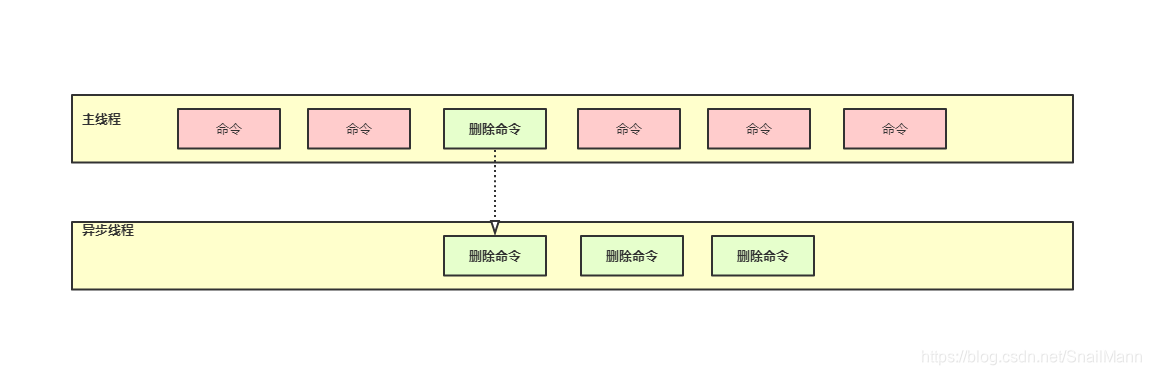
类似的单线程卡顿操作还有很多,比如flushdb,flushall等清空数据库的操作,都可以使用
flush ansy等方式,将要删除的数据丢到一个消息队列中,让后台异步线程从消息队列中慢慢拿要删除的数据,异步删除处理。不阻塞主线程的其他业务操作。
手撸LRU算法
Java版本
我们这里不写原生的LRU实现,所以通过继承LinkedHashMap来简单的实现LRU内存淘汰算法。
package com.snailmann.learn.lru;
import java.util.LinkedHashMap;
import java.util.Map;
/**
* 通过linkedHashMap来模拟LRU内存淘汰算法
*
* @param <K>
* @param <V>
*/
public class LRUCache2<K, V> extends LinkedHashMap<K, V> {
/**
* LRU容器最大的元素个数
*/
private final int cacheSize;
/**
* LinkedHashMap本身就支持根据访问顺序排列数据
* 最先访问在队头,最久访问在队尾
* accessOrder = true就是顺序访问排序,false就是插入顺序排序,默认是false
*
* @param cacheSize
*/
public LRUCache2(int cacheSize) {
/**
* 为了让LRUCache的size是我们设置的size,就需要知道好内部的hashmap的size, 既size / hashmap加载因子就是hashmap的size
* 再 + 1 是为了不让hashmap扩容
*/
super((int) (Math.ceil(cacheSize / 0.75) + 1), 0.75f, true);
this.cacheSize = cacheSize;
}
/**
* 这是LinkedHashMap本身的判断,是否删除队尾元素,true删除,false不删除
* 我们要重写它,只有size超了,才删除队尾元素
*
* @param eldest
* @return
*/
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > cacheSize;
}
public static void main(String[] args) throws InterruptedException {
LRUCache2<Integer, Long> map = new LRUCache2<>(10);
for (int i = 0; i < 10; i++) {
long time = System.currentTimeMillis();
map.put(i, time);
Thread.sleep(100);
}
System.out.println(map);
for (int i = 10; i < 16; i++) {
long time = System.currentTimeMillis();
Integer key = i;
map.put(key, time);
}
System.out.println(map);
}
}
Python版本
from collections import OrderedDict class LRUDict(OrderedDict): """ 通过OrderedDict实现LRU OrderedDict本质就是dict + 双向链表 """ def __init__(self, capacity, **kwargs): """ :param capacity: LRUDict的最大容量 :param kwargs: """ super().__init__(**kwargs) self.capacity = capacity self.items = OrderedDict() def __setitem__(self, key, value): old_value = self.items.get(key) # 如果key键已存在,则先弹出该键值对,重新插入新值,同时存储位置也换了 if old_value is not None: self.items.pop(key) self.items[key] = value # 如果LRUDict的容量够,且key不存在容器中,则直接插入 elif len(self.items) < self.capacity: self.items[key] = value # 如果LRUDict容量不够,且key不在容器中,则执行LRU淘汰算法,弹出队头元素,新元素插入队尾 else: self.items.popitem(last=False) self.items[key] = value def __getitem__(self, key): value = self.items.get(key) if value is not None: self.items.pop(key) self.items[key] = value return value def __repr__(self): return repr(self.items) lru = LRUDict(10) for i in range(1, 15): lru[i] = i print(lru)
相关问题
Redis的LFU内存淘汰算法
因为本章节重点讲的是LRU淘汰算法,所以就没有提及LFU算法。但是实际上LFU算法可以说是比LRU算法更优秀的淘汰算法。
什么是LFU算法?
- LFU淘汰算法,既
Least Frequently Used
, 表示按最近访问频率对数据进行内存淘汰,它比LRU更加准确的表示了一个key被访问的热度 - 如果一个Key长时间不被访问,只是刚刚偶然被用户访问了一下,那么LRU算法也会认为它是一个热点数据,所以不会淘汰它。而LFU算法则需要追踪最近一段时间的访问频率,如果某个key只是偶然被访问一次是不足以让LFU认为这是一个热点数据的。它需要在近一段时间被访问很多次,才有机会成为LFU认可的热点数据
怎么开启LFU模式?
Redis 4.0在淘汰策略配置参数maxmemory-policy中又添加了两个选项:
volaitle-lfu
allkeys-lfu
这两种再加上以前的6种,相当于已经有了8中淘汰策略选项了!! Redis还是提供了很多种策略给我们选择的。
我刚插入到Redis中不久的数据怎么没啦?
-
Redis是内存存储系统,通常我们是把Redis当做缓存使用的,什么是缓存?意思就是这些数据很可能会随时不见的,它并不能简单的当做是一个持久化的数据库存储系统!
-
如果你出现了数据消失的情况,一就是检查,是否设置了过期时间。而就是检查Redis内存使用情况,是否因为满了导致执行内存淘汰算法。
我明明给Redis的数据设置了过期时间,时间到了,为什么那些数据还占用着内存?
因为Redis采用的是
定时删除和
惰性删除两种删除策略。既如果我们的Redis数据过期时间到了,Redis是并不会立马从内存中删除这些数据的。而是采用两种策略是删除:
定时删除
默认每100ms对有过期时间的数据进行一次扫描,每次扫描只扫描一部分数据。只要发现过期数据,此时立即删除。但是由于定时删除每次删除的是部分数据,所以并不代表定时的每次删除都能把所有过期数据删除完,这需要一定的时间去清理惰性删除
虽然定时删除每隔100ms一次,1s就至少执行了10次。但当设置了过期时间的数据量比较庞大的时候,定时删除也总会漏掉一下过期的数据,导致这些过期数据没有删除,依然遗留在内存中。此时就需要依靠惰性删除机制。既当这些过期数据被再次访问时,Redis会检查这些数据是否过期,如果已经过期,就立即删除
总之我们可以知道,Redis的过期数据并非都能得到立即的删除,所以我们就会发现即使数据的过期时间到了,但这些数据依然会占用内存空间一段时间。
参考资料
- 《Redis深度历险》
- LRU算法的Python实现 - @作者:奋斗终生
- 如果觉得对你有帮助,能否点个赞或关个注,以示鼓励笔者呢?!

- 【Redis笔记】一起学习Redis | 聊聊缓存,数据库的双写数据不一致问题
- 【Redis笔记】一起学习Redis | 聊聊Redis的持久化策略,AOF和RDB
- 韩顺平_PHP程序员玩转算法公开课(第一季)11_双向链表在内存中存在形式剖析_学习笔记_源代码图解_PPT文档整理
- GuavaCache学习笔记一:自定义LRU算法的缓存实现
- 缓存学习-【转】缓存淘汰算法--LRU算法
- Redis内存回收:LRU算法
- 韩顺平_PHP程序员玩转算法公开课(第一季)02_单链表在内存中存在形式剖析_学习笔记_源代码图解_PPT文档整理
- 【算法学习笔记】78. STL二分的练习 下标映射的处理技巧 SJTU OJ 1053 二哥的内存
- 链表实现LRU淘汰算法-笔记
- 【python学习笔记】3:LRU(最近最少使用页面置换)算法
- 韩顺平_PHP程序员玩转算法公开课(第一季)06_堆栈在内存中存在形式剖析_学习笔记_源代码图解_PPT文档整理
- Redis内存回收:LRU算法
- 黑马程序员--Java基础学习笔记之抽象类和接口、内存结构分析、Java APIs
- 【算法导论】学习笔记第一章:算法在计算中的作用
- 【算法学习笔记】76.DFS 回溯检测 SJTU OJ 1229 mine
- Redis学习笔记-List数据类型
- 数据结构与算法学习笔记——算法的时间和空间复杂度
- 数据结构与算法:python语言描述学习笔记Part3_1
- Linux学习笔记27——共享内存
- HMM的学习笔记1:前向算法