Python获取 东方财富 7x24小时全球快讯
2019-07-27 16:42
267 查看
原文链接:http://www.cnblogs.com/betterwgo/p/11255581.html
本文使用的IDE为PyCharm。
1.第三方库
(1)selenium
selenium用来做浏览器自动化,因为这部分信息是动态加载的,不用这种方法读取不到相关数据。
安装:
pip3 install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple
然后下载与自己浏览器对应的驱动
-
火狐浏览器驱动,其下载地址是:https://github.com/mozilla/geckodriver/releases
-
谷歌浏览器驱动,其下载地址是:http://chromedriver.storage.googleapis.com/index.html?path=2.33/
-
opera浏览器驱动,其下载地址是:https://github.com/operasoftware/operachromiumdriver/releases
以上是网上有大佬贴出来的下载地址,实际使用需要根据自己电脑上的浏览器版本下载对应的驱动,比如我用的谷歌浏览器,驱动版本不对应会报如下错误:
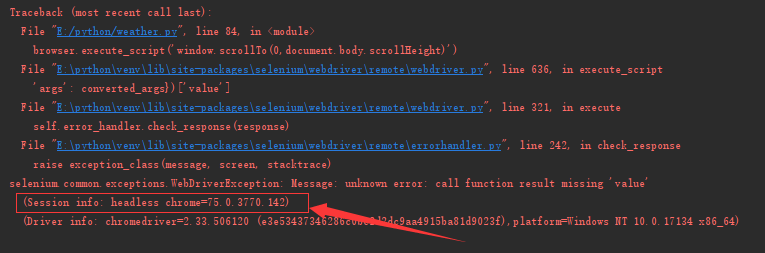
这个时候,我们根据这里报的 chrome=75.0.3770.142去查找对应的驱动版本。驱动版本可到 http://npm.taobao.org/mirrors/chromedriver/ 下载。
我的驱动直接放在文件同目录了:
(2)BeautifulSoup
pip3 install bs4 -i https://pypi.tuna.tsinghua.edu.cn/simple
2.网页分析
东方财富 7x24小时全球快讯 的网址是 http://m.eastmoney.com/kuaixun ,这里我想获取三项内容,新闻时间,新闻简介和新闻的链接。
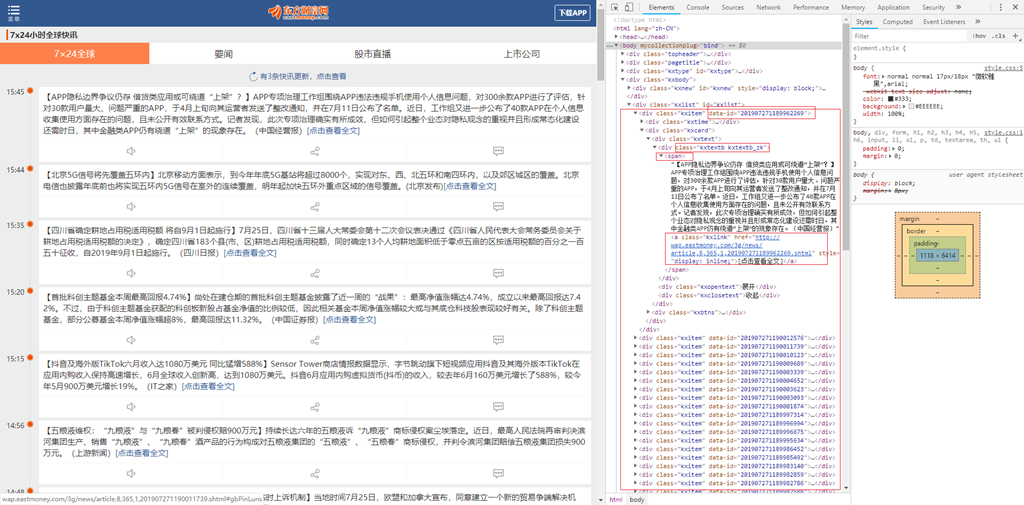
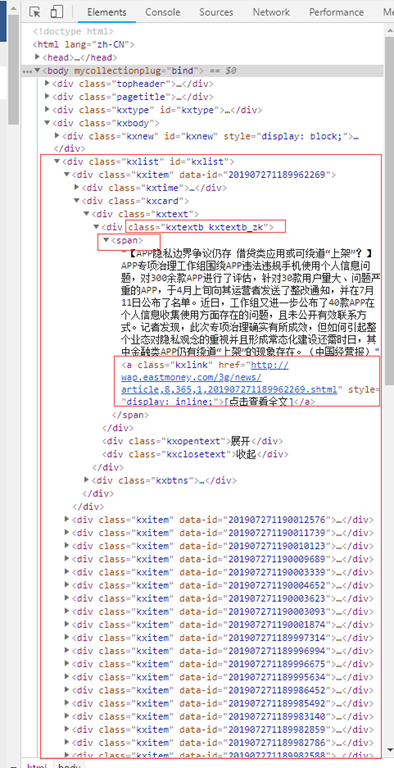
3.代码实现及效果
代码中关键的地方都已经写在注释里面了。
from bs4 import BeautifulSoup
import time;
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
# 设置chrome浏览器无界面模式,不然每运行一次都会弹出来谷歌浏览器界面
# 不过弹出谷歌界面有助于理解为什么下面会有个页面滚动
chrome_options.add_argument('--headless')
# executable_path为驱动地址
browser = webdriver.Chrome(executable_path='./chromedriver.exe', chrome_options=chrome_options)
url = "http://m.eastmoney.com/kuaixun"
browser.get(url)
# 模仿浏览器往下滚动的页面,获取更多的数据
for i in range(1, 5):
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(1)
html = BeautifulSoup(browser.page_source, "lxml")
# 退出浏览器
browser.quit()
# print(html)
news_list = html.find_all('div', class_='kxitem')
# print(news_list)
for news in news_list:
print(news['data-id'])
news_text = news.find('span')
news_href = news.find('a')
for s in news_text("a"):
# 去掉span标签中的链接标签
s.extract()
print(news_text.get_text())
print(news_href['href'])
效果:
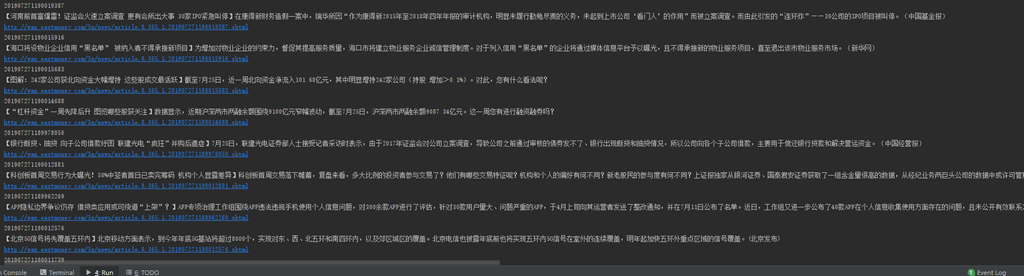
转载于:https://www.cnblogs.com/betterwgo/p/11255581.html

相关文章推荐
- Python3获取股票行情数据(中国个股/中国指数/全球指数)
- Python3获取股票行情数据(中国个股/中国指数/全球指数)
- Python使用免费天气API,获取全球任意地区的天气情况
- Python3获取股票行情数据(中国个股/中国指数/全球指数)
- Python3获取股票行情数据(中国个股/中国指数/全球指数)
- Python中CSV文件获取—全球各国国内生产总值
- python定时获取汇率存入数据库
- python的subprocess:子程序调用(调用执行其他命令);获取子程序脚本当前路径问题
- Python 脚本获取ES 存储容量的实例
- python爬虫(二)获取京东python书籍信息
- Streaming中获取conf参数(python版)
- 获取帮助python
- Python获取本机所有网卡ip,掩码和广播地址
- 获取当前 Python 版本
- python 获取当天凌晨零点的时间戳
- Python元素的添加· 获取以及删除
- 使用python 获取进程pid号的方法
- python3爬虫获取html内容及各属性值的方法
- python从零写一个采集器:获取网页源码
- Python3 HTMLParser 获取 Python Events