Kubernetes(K8s)
 版权声明:署名,允许他人基于本文进行创作,且必须基于与原先许可协议相同的许可协议分发本文 (Creative Commons)
版权声明:署名,允许他人基于本文进行创作,且必须基于与原先许可协议相同的许可协议分发本文 (Creative Commons)
接上一篇:Docker权威指南(点击链接跳转)
十五、Kubernetes (K8s)
官网:
( 若报404错误,可分步进入! )
https://kubernetes.io/docs/tutorials/kubernetes-basics/
基础命令:
https://www.geek-share.com/detail/2672593388.html
Kubernates相关对象及架构图:

(一)Pod
在Kubernetes系统中,调度的最小颗粒不是单纯的容器,而是抽象成一个Pod,Pod是一个可以被创建、销毁、调度、管理的最小的部署单元。把相关的一个或多个容器(Container)构成一个Pod,通常Pod里的容器运行相同的应用。
Pod包含的容器运行在同一个Minion(Host)上,看作一个统一管理单元,共享相同的 volumes 和 network namespace/IP 和 Port 空间。
解释二:
Pod实际上是容器的集合,在k8s中对运行容器的要求为:容器的主程序需要一直在前台运行,而不是在后台运行。应用可以改造成前台运行的方式,例如Go语言的程序,直接运行二进制文件;例如Java语言则运行主类;tomcat程序可以写个运行脚本。或者通过supervisor的进程管理工具,及supervisor在前台运行,应用程序由supervisor管理在后台运行。
当多个应用之间是紧耦合的关系时,可以将多个应用一起放在一个Pod中,通过Pod中的多个容器之间互相访问可以通过localhost来通信(可以把Pod理解后才能一个虚拟机,共享网络和存储卷)。
(二)Services
Services也是Kubernetes的基本操作单元,是真实应用服务的抽象,每一个服务后面都有很多对应的容器来支持,通过Proxy的port和服务selector决定服务请求传递给后端提供服务的容器,对外表现为一个单一访问地址,外部不需要了解后端如何运行,这给扩展或维护后端带来很大的好处。
(三)Replication Controller
Replication Controller,理解成更复杂形式的pods,它确保任何时候Kubernetes集群中有指定数量的pod副本(replicas)在运行,如果少于指定数量的pod副本(replicas),Replication Controller会启动新的Container,反之会杀死多余的以保证数量不变。Replication Controller使用预先定义的pod模板创建pods,一旦创建成功,pod 模板和创建的pods没有任何关联,可以修改 pod 模板而不会对已创建pods有任何影响,也可以直接更新通过Replication Controller创建的pods。对于利用 pod 模板创建的pods,Replication Controller根据 label selector 来关联,通过修改pods的 label 可以删除对应的pods。
(四)Services VS Pod
service 和 replicationController 只是建立在pod之上的抽象,最终是要作用于pod的,那么它们如何跟pod联系起来呢?这就引入了label的概念:label其实很好理解,就是为pod加上可用于搜索或关联的一组 key/value 标签,而service和replicationController正是通过label来与pod关联的。
为了将访问Service的请求转发给后端提供服务的多个容器,正是通过标识容器的labels来选择正确的容器;Replication Controller也使用labels来管理通过 pod 模板创建的一组容器,这样Replication Controller可以更加容易,方便地管理多个容器。
如下图所示,有三个pod都有label为"app=backend",创建service和replicationController时可以指定同样的label:"app=backend",再通过label selector机制,就将它们与这三个pod关联起来了。例如,当有其他frontend pod访问该service时,自动会转发到其中的一个backend pod。

Kubernates集群安装规划如下:
|
角色 |
IP |
组件 |
|
master |
192.168.121.200 |
docker、 kubeadm、 kubelet、kubectl |
|
node |
192.168.121.201 |
docker、 kubeadm、 kubelet、kubectl |


15.1 Master&Node
15.1.1 准备文件及配置Yum源
Docker:1.13.1
Kubernates:1.11.1
CentOS:7及以上
15.1.2 关闭交换分区/网络配置
[code]# vim /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 vm.swappiness=0
[code]vim /etc/fstab
注销掉swap分区的加载
查看修改是否成功:
[code]sysctl -w net.bridge.bridge-nf-call-iptables=1 sysctl -w net.bridge.bridge-nf-call-ip6tables=1
15.1.3 Docker
参考第1章
文件驱动默认由systemd改成cgroupfs, 而我们安装的docker使用的文件驱动是systemd, 造成不一致, 导致镜像无法启动。

改变后:

Docker进程资源管理(cpu、io、内存)驱动默认是systemd。Kubernates支持cgroupfs,否则镜像启动不了。
[code]# vim /usr/lib/systemd/system/docker.service --exec-opt native.cgroupdriver=systemd \ //修改前 --exec-opt native.cgroupdriver=cgroupfs \ //修改后




刷新服务/重启Docker:
[code]# systemctl daemon-reload # systemctl restart docker
15.1.4 启用IPVS
LVS的IP负载平衡技术就是通过IPVS模块来实现的,IPVS是LVS集群系统的核心软件,它的主要作用是:安装在Director Server上,同时在Director Server上虚拟出一个IP地址,用户必须通过这个虚拟的IP地址访问服务。
这个虚拟IP一般称为LVS的VIP,即Virtual IP。访问的请求首先经过VIP到达负载调度器,然后由负载调度器从Real Server列表中选取一个真实服务节点响应用户的请求。
常用的工作模式有:LVS/NAT、LVS/DR、LVS/Tun。

1. 当用户向负载均衡调度器(Director Server)发起请求,调度器将请求发往至内核空间。
2. PREROUTING(prerouting)链首先会接收到用户请求,判断目标IP确定是本机IP,将数据包发往INPUT链。
3. IPVS是工作在INPUT链上的,当用户请求到达INPUT时,IPVS会将用户请求和自己已定义好的集群服务进行比对,如果用户请求的就是定义的集群服务,那么此时IPVS会强行修改数据包里的目标IP地址及端口,并将新的数据包发往POSTROUTING链。
4. POSTROUTING(postrouting)链接收数据包后发现目标IP地址刚好是自己的后端服务器,那么此时通过选路,将数据包最终发送给后端的服务器。
备注:需要了解Iptables规则 http://www.zsythink.net/archives/1199/
安装ipvs
[code]yum install -y ipvsadm
检查是否安装成功
[code]lsmod | grep ip_vs 或 ps -ef | grep ip_vs

开启:ip_vs_rr、ip_vs_sh、ip_vs_wrr、nf_conntrack_ipv4
创建文件ipvs.modules:
[code]$>vim /etc/sysconfig/modules/ipvs.modules
拷贝以下内容:
[code]#!/bin/bash /sbin/modinfo -F filename ip_vs > /dev/null 2>&1 if [ $? -eq 0 ]; then /sbin/modprobe -- ip_vs /sbin/modprobe -- ip_vs_rr /sbin/modprobe -- ip_vs_wrr /sbin/modprobe -- ip_vs_sh /sbin/modprobe -- nf_conntrack_ipv4 fi
增加文件执行权限
[code]$>chmod +x /etc/sysconfig/modules/ipvs.modules
重启操作系统
[code]$>reboot
15.1.5 Kubernetes
配置YUM 源
[code]# vim /etc/yum.repos.d/kubernetes.repo
拷贝以下内容:
[code][kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ gpgcheck=0
测试地址是否可用:
[code][root@bigdata ~]# curl https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
每个节点都要安装,执行以下命令
[code]yum install kubectl kubelet kubeadm

输出:
[code]...... 已安装: kubeadm.x86_64 0:1.14.2-0 kubectl.x86_64 0:1.14.2-0 kubelet.x86_64 0:1.14.2-0 作为依赖被安装: kubernetes-cni.x86_64 0:0.7.5-0 完毕!

先卸载:
[code]yum remove kubectl kubelet kubeadm
更新最新系统
或者批定版本:
格式:yum install -y kubelet-<version> kubectl-<version> kubeadm-<version>,
如:
[code]yum install -y kubelet-1.11.2 kubectl-1.11.2 kubeadm-1.11.2


设置开机启动kubelet
[code]systemctl enable kubelet
15.2 Master
参考:
https://blog.csdn.net/san_gh/article/details/80912897
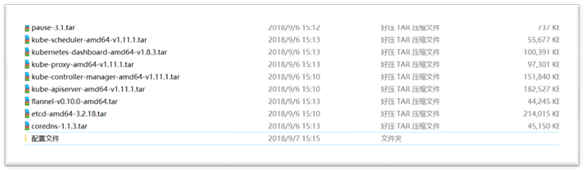
Master安装文件清单

15.2.1 初始化Master
使用kubeadm初始化master,执行初始化服务器成为master节点(类似docker swarm)。初始化的时候指定一下kubernetes版本,并设置一下pod-network-cidr(后面的flannel会用到)

执行初始化时,kubeadm执行了一系列的操作,包括一些pre-check,生成ca证书,安装etcd和其它控制组件等(远程接取google镜像),目前国内连接不上,执行报错,kubeadm执行初始化依赖第三方镜像:
[code]kube-apiserver-amd64 kube-controller-manager-amd64 kube-scheduler-amd64 kube-proxy-amd64 pause etcd-amd64 coredns kubernetes-dashboard-amd64:v1.8.3
执行初始化报错

解决办法一、(及Git时遇到的问题)
https://blog.csdn.net/hu_jinghui/article/details/82148540
https://www.geek-share.com/detail/2731998131.html
https://www.jianshu.com/p/e25c763b9816
https://www.geek-share.com/detail/2584119560.html
1)注册Github用户,创建repositry、仓库目录及Dockerfile。

每个文件夹下创建Dockerfile文件,根据镜像内容编写,如kubernetes-dashboard,定义如下:
[code]FROM gcr.io/google_containers/kubernetes-dashboard-amd64:v1.8.3
2)注册Docker hub 账号,创建自动编译Repositry(从github拉取Dockerfile下载镜像),关联1)
创建的github及repositry

备注:第一次使用,需要在docker hub中关联github账号

配置docker hub repositry需要关联github中的哪个Repositry

配置docker hub repositry名称,如下图4所示:

已配置自动编译Repositry,如下所示:

配置镜像构建:
一、先进入docker hub repository(图-5),然后选择build settings;
二、配置github版本、github 中的docker目录位置及在docker hub 中的tag name,保存然后点击trigger(图-6)


点击trigger后,切换build details可以看到正在构建的进度,如下图-7是已经构建完成:

3)从docker hub下载镜像,批量下载脚本如下:
解决完加速器的问题之后,开始下载k8s相关镜像,下载后将镜像名改为k8s.gcr.io/开头的名字,以便kubeadm识别使用
[code]#!/bin/bash
images=(kube-apiserver-amd64:v1.11.2 kube-controller-manager-amd64:v1.11.2 kube-scheduler-amd64:v1.11.2 kube-proxy-amd64:v1.11.2 pause:3.1 etcd-amd64:3.2.18 coredns:1.1.3 kubernetes-dashboard-amd64:v1.8.3)
for imageName in ${images[@]} ; do
docker pull yangdockerrepos/$imageName
docker tag yangdockerrepos /$imageName k8s.gcr.io/$imageName
docker image rm yangdockerrepos /$imageName
done
docker images查看
如何执行脚本:
chmod u+x command.sh
./command.sh
解决办法二、
通过阿里云解决
https://blog.csdn.net/zzq900503/article/details/81710319
解决办法三、
通过下载离线包,然后导入docker本地镜像库。通过执行下述脚本,脚本与离线包放置同一目录:

[code]#!/bin/bash
images=(kube-apiserver-amd64-v1.11.2 kube-controller-manager-amd64-v1.11.2 kube-scheduler-amd64-v1.11.2 kube-proxy-amd64-v1.11.2 pause-v3.1 etcd-amd64-v3.2.18 coredns-v1.1.3 kubernetes-dashboard-amd64-v1.8.3)
for imageName in ${images[@]} ; do
docker load -i $imageName".tar"
done
效果:

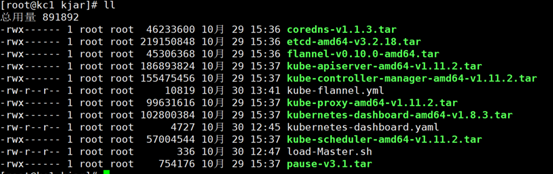
【注】上述的8个包导入成功后保证repository前缀为k8s.gcr.io,如果不是则执行docker tag 重新标记(参考2.1.4及2.1.5小节),不然执行下述master节点初始化时找到包。
执行初始化命令(--token-ttl 默认token的有效期为24小时,当过期之后,该token就不可用了,需要重新生成token,会比较麻烦,这里–token-ttl设置为0表示永不过期)
[code]kubeadm init --kubernetes-version=v1.11.2 --pod-network-cidr=10.244.0.0/16 --token-ttl 0


重新初始化执行:kubeadm reset
安装的内容:
https://blog.csdn.net/bbwangj/article/details/82024485
【若出现版本问题,则执行前面 yum 卸载kubeadm、kubectl、kubelet,离线下载安装包,用脚本进行下载安装】
【记录下最后一句的指令,其中包含了的 token,后续添加机器都应通过该token,eg:
[init] using Kubernetes version: v1.11.2】
[code][root@bigdata opt]# kubeadm init --kubernetes-version=v1.11.2 --pod-network-cidr=10.244.0.0/16
[code]报错:1.如果不关闭swap,就会在kubeadm初始化Kubernetes的时候报错,如下: [root@bigdata ~]# kubeadm init --kubernetes-version=v1.11.2 --pod-network-cidr=10.244.0.0/16 this version of kubeadm only supports deploying clusters with the control plane version >= 1.13.0. Current version: v1.11.2 [root@bigdata ~]# kubeadm init --kubernetes-version=v1.14.0 --pod-network-cidr=10.244.0.0/16 [init] Using Kubernetes version: v1.14.0 [preflight] Running pre-flight checks error execution phase preflight: [preflight] Some fatal errors occurred: [preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
[code][preflight] running pre-flight checks I0909 23:56:52.845840 28340 kernel_validator.go:81] Validating kernel version I0909 23:56:52.845959 28340 kernel_validator.go:96] Validating kernel config [preflight/images] Pulling images required for setting up a Kubernetes cluster [preflight/images] This might take a minute or two, depending on the speed of your internet connection [preflight/images] You can also perform this action in beforehand using 'kubeadm config images pull' [kubelet] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [preflight] Activating the kubelet service [certificates] Generated ca certificate and key. [certificates] Generated apiserver certificate and key. [certificates] apiserver serving cert is signed for DNS names [bigdata kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.121.200] [certificates] Generated apiserver-kubelet-client certificate and key. [certificates] Generated sa key and public key. [certificates] Generated front-proxy-ca certificate and key. [certificates] Generated front-proxy-client certificate and key. [certificates] Generated etcd/ca certificate and key. [certificates] Generated etcd/server certificate and key. [certificates] etcd/server serving cert is signed for DNS names [bigdata localhost] and IPs [127.0.0.1 ::1] [certificates] Generated etcd/peer certificate and key. [certificates] etcd/peer serving cert is signed for DNS names [bigdata localhost] and IPs [192.168.121.200 127.0.0.1 ::1] [certificates] Generated etcd/healthcheck-client certificate and key. [certificates] Generated apiserver-etcd-client certificate and key. [certificates] valid certificates and keys now exist in "/etc/kubernetes/pki" [kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/admin.conf" [kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/kubelet.conf" [kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/controller-manager.conf" [kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/scheduler.conf" [controlplane] wrote Static Pod manifest for component kube-apiserver to "/etc/kubernetes/manifests/kube-apiserver.yaml" [controlplane] wrote Static Pod manifest for component kube-controller-manager to "/etc/kubernetes/manifests/kube-controller-manager.yaml" [controlplane] wrote Static Pod manifest for component kube-scheduler to "/etc/kubernetes/manifests/kube-scheduler.yaml" [etcd] Wrote Static Pod manifest for a local etcd instance to "/etc/kubernetes/manifests/etcd.yaml" [init] waiting for the kubelet to boot up the control plane as Static Pods from directory "/etc/kubernetes/manifests" [init] this might take a minute or longer if the control plane images have to be pulled [apiclient] All control plane components are healthy after 43.502925 seconds [uploadconfig] storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace [kubelet] Creating a ConfigMap "kubelet-config-1.11" in namespace kube-system with the configuration for the kubelets in the cluster [markmaster] Marking the node bigdata as master by adding the label "node-role.kubernetes.io/master=''" [markmaster] Marking the node bigdata as master by adding the taints [node-role.kubernetes.io/master:NoSchedule] [patchnode] Uploading the CRI Socket information "/var/run/dockershim.sock" to the Node API object "bigdata" as an annotation [bootstraptoken] using token: 4imjwi.431fe9y9pybvc9sc [bootstraptoken] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials [bootstraptoken] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token [bootstraptoken] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster [bootstraptoken] creating the "cluster-info" ConfigMap in the "kube-public" namespace [addons] Applied essential addon: CoreDNS [addons] Applied essential addon: kube-proxy Your Kubernetes master has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
【注意】如果要使用集群,执行以下脚本!!
【若执行出错,即为前面下载安装有问题,请检查核对!!!】
[code]mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
或执行如下:
[code]export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run " kubectl apply -f [podnetwork].yaml " with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of machines by running the following on each node
as root:
[code] kubeadm join 192.168.121.200:6443 --token 4imjwi.431fe9y9pybvc9sc --discovery-token-ca-cert-hash sha256:84c3957c54c0ffe9e7b9861df46d65332485c8c3adbdf6720e4163a286f45735
15.2.2 安装flannel
导入flannel镜像
[code]docker load -i flannel-v0.10.0-amd64.tar

【需进入所下载的Kubernetes 路径 下,例如/opt/v1.11.2】
Pod网络—第三方网络组件
1)Master执行初始化(kubeadm init)时必须指定 --pod-network-cidr=10.244.0.0/16
2)net.bridge.bridge-nf-call-iptables=1(/proc/sys/net/bridge/bridge-nf-call-iptables to 1
执行kubectl apply创建资源
[code]kubectl apply -f kube-flannel.yml
或者
[code]kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/v0.10.0/Documentation/kube-flannel.yml

15 . 2 . 3 DaemonSet
Deployment部署的副本Pod会分布在各个Node上,每个Node都可能运行好几个副本。DaemonSet的不同之处在于:每个Node上最多只能运行一个副本。
DaemonSet的典型应用场景有:
(1)在集群的每个节点上运行存储Daemon,比如 glusterd 或 ceph
(2)在每个节点上运行日志收集Daemon,比如 flunentd 或 logstash
(3)在每个节点上运行监控Daemon,比如 Promentheus Node Exporter 或 collectd
[code][root@bigdata k8sjar]# kubectl get daemonset --namespace=kube-system

DaemonSet kube-flannel-ds 和 kube-proxy 分别负责每个节点上运行 flannel 和 kube-proxy组件
[root@bigdata k8sjar]# kubectl get pod --namespace=kube-system -o wide

因为flannel 和 kube-proxy属于系统组件,需要在命令行中通过--namespace=kube-system制定namespace kube-system。若不指定,,则只返回默认 namespace default 中的资源
15.2.4 部署Kubernates Dashboard
因网络原因,15.2.1节初始化Master时,已经将kubernetes-dashboard-amd64镜像下载至本地,否则需要网络正常再执行安装。如果kubelet服务运行状态是停止,则需要执行以下命令启动:
systemctl start kubelet
下载kubernetes-dashboard.yaml文件,执行以下命令:
kubectl create -f
或者
[code]kubectl create -f kubernetes-dashboard.yaml

【注意】互联网上kubernetes-dashboard.yaml引用镜像版本,建议先下载到本地,修改本地版本。

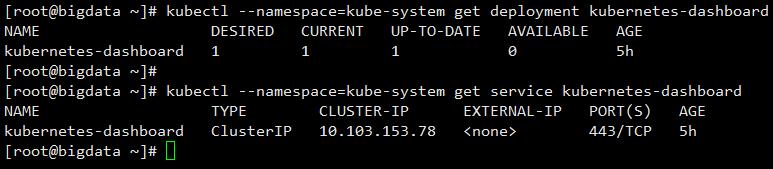
Dashboard会在kube-system namespace 中创建自己的 Deployment 和 Service ,如下图所示:
[code][root@bigdata ~]# kubectl --namespace=kube-system get deployment kubernetes-dashboard [root@bigdata ~]# kubectl --namespace=kube-system get service kubernetes-dashboard
【注意】为了在集群内部,通过浏览器访问已经安装kubernetes管理面板,建议在安装一台GUI(Master or Node)
yum groupinstall "GNOME Desktop"
然后修改启动方式:
[code]systemctl get-default //查看前启动模式 systemctl set-default graphical.target // 配置GUI启动为默认【默认开机启动为图形界面】
访问方式
一、Kubectl proxy(推荐):
仅限集群内部访问
由于无法拿到kube-proxy的yaml文件,只能运行如下命令查看配置
[root@bigdata k8sjar]# kubectl edit daemonset kube-proxy --namespace=kube-system



命令行启动:
使用kubectl proxy命令就可以使API server监听在本地的8001端口上:
kubectl proxy
或者
kubectl proxy --address=192.168.121.200 --port=8001 --disable-filter=true
Kubernetes-dashboard所在服务器,Web方式打开(本机访问):
无法访问!!!?????
http://localhost:8001/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy
效果如下:

获取Kubernetes-dashboard登录token(namespace-controller-token的密钥):
kubectl -n kube-system describe $(kubectl -n kube-system get secret -o name | grep namespace) | grep token

登录成功效果图:

扩展:
kubectl proxy(1.3.x 以前版本)
通过将认证 token 直接传递给 apiserver 的方式,可以避免使用 kubectl proxy,如下所示:
$ APISERVER=$(kubectl config view | grep server | cut -f 2- -d ":" | tr -d " ")
$ TOKEN=$(kubectl config view | grep token | cut -f 2 -d ":" | tr -d " ")
kubectl proxy(1.3.x 以后版本)
在 Kubernetes 1.3 或更高版本中,kubectl config view 不再显示 token。 使用 kubectl describe secret … 获取 default service account 的 token,如下所示:
[code]$ APISERVER=$(kubectl config view | grep server | cut -f 2- -d ":" | tr -d " ") $ TOKEN=$(kubectl describe secret $(kubectl -n kube-system get secret -o name | grep namespace) | grep token
二、Apiserver(通过Apiserver端口访问,新版本停用insecure-port端口,默认为0;安全端口默认6443)----存在问题
https://192.168.121.200:6443/api/v1/namespaces/kube-system/services/kubernetes-dashboard
三、Nodeport
修改官网kubernetes-dashboard.yaml,增加nodePort=30505、type=NodePort
【备注】通过此种方式只能在集群内部服务器访问。以下代码是kubernetes-dashboard.yaml中service片段:
[code]apiVersion: v1
kind: Service
metadata:
creationTimestamp: 2018-09-11T05:43:37Z
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kube-system
resourceVersion: "70067"
selfLink: /api/v1/namespaces/kube-system/services/kubernetes-dashboard
uid: a1432ec2-b585-11e8-9708-000c29a02ac2
spec:
clusterIP: 10.110.216.244
externalTrafficPolicy: Cluster
ports:
- nodePort: 30505
port: 443
protocol: TCP
targetPort: 8443
selector: k8s-app: kubernetes-dashboard
sessionAffinity: None
type: NodePort
status:
loadBalancer: {}
执行修改
Kubectl apply -f kubernetes-dashboard.yaml
或者直接执行以下命令,在线修改
kubectl -n kube-system edit service kubernetes-dashboard
查看端口是否成功映射:
kubectl get services -n kube-system

Web 打开:https://localhost:30505
获取Token,拷贝至登录
kubectl -n kube-system describe $(kubectl -n kube-system get secret -n kube-system -o name | grep namespace) | grep token
登录后效果:

kubernetes-dashboard.yaml的介绍,现在就理解了为什么其角色的名称为kubernetes-dashboard-minimal。一句话,这个Role的权限不够!
因此,我们可以更改RoleBinding修改为ClusterRoleBinding,并且修改roleRef中的kind和name,使用cluster-admin这个非常牛逼的ClusterRole(超级用户权限,其拥有访问kube-apiserver的所有权限)。需要修改kubernetes-dashboard.yaml,如下:
[code]apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: kubernetes-dashboard-minimal namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: kubernetes-dashboard-minimal subjects: - kind: ServiceAccount name: kubernetes-dashboard namespace: kube-system
登录效果:

15.2.5 常用命令
[code]docker ps | grep kube-apiserver // 查看集群信息 kubectl cluster-info // 查看pods、service、config列表 kubectl get pods --all-namespaces kubectl get services -n kube-system kubectl config view // 查看secret列表 kubectl -n kube-system get secret // 查看指定secret描述 kubectl -n kube-system describe secret kubernetes-dashboard-token-lbpfp

token:
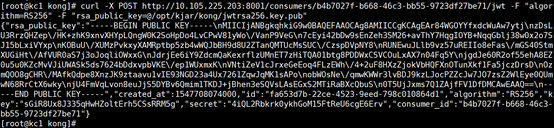
[code]eyJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJrdWJlcm5ldGVzLWRhc2hib2FyZC10b2tlbi1sYnBmcCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6IjA4MzUwYmUyLTJiNTktMTFlOS05OTcyLTAwMGMyOTU4YWYwNCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlLXN5c3RlbTprdWJlcm5ldGVzLWRhc2hib2FyZCJ9.lRScWpUn1bbZNEEkK06UzWihSO71Mh6SU9IwWLKpNgBni987S6LAwFlBMoLZ2yNixQ5HgmP3AI2ALDVcSIEHIrmBUjI4t7EG4aidX99I-XW0RBOU-5O_y1oB0sRA3WbD77MEWwIrXpry0S7-2Dzu3dmguF-_vSrRN5xFJv2yw7zpskMsFg8vt3K0Oenjg-0U306n1X3ajDS1eDvbmG1ZPEk3hy9uGoulVZNKEeYCC0DMZcBtMc72fFlxxsoUPPyYieRfpZ8geO6I2FiGFl5foDQgTwW7Wr-na8TF3dDudkHphgQndXPd51QW8qHiaiCGtSoz59DLt_zkqkIeOpNcsQ
[code]// 查看kubernetes-dashboard service配置 kubectl -n kube-system edit service kubernetes-dashboard
[code]// 查看错误事件
kubectl get events --namespace=kube-system
// 查看token(获取kubernetes-dashboard的token登录时权限不足)
kubectl get secret -n kube-system | grep kubernetes-dashboard
kubectl -n kube-system get secret <NAME> -o jsonpath={.data.token}| base64 -d
[code]// 获取Pod 详细信息 kubectl describe pod kubernetes-dashboard -n kube-system
[code]// 获取Pod列表 kubectl get pods -l app=mics-app kubectl get pods -o wide // 获取Service信息 Kubectl describe service kubernetes-dashboard -n kube-system

// svc、ep网络信息
[code]Kubectl get svc -n <NAMESPACES> Kubectl get ep -n <NAMESPACES>
[code]// apiVersion kubectl api-versions

[code]// Cluster info kubectl describe svc springboot-app // 查看Pod logs kubectl logs -f <pod_name>
15.3 Node
Node安装文件清单【模拟Master,jar包分别移入对应文件夹中,编写脚本执行,下载】
15.3.1 镜像准备
保障Node节点可以获取到以下镜像
Coredns、flannel、kube-proxy-amd64、pause、kubernetes-dashboard(如果Master点部署kubernetes-dashboard,则Node节点需要保证可以访问到此镜像)
执行下述脚本导入Coredns、kube-proxy-amd64、pause:
【脚本名称为:load.sh======》也可以自己新建,执行脚本使用:
bash load.sh】
[code]#!/bin/bash
images=(kube-proxy-amd64-v1.11.2 pause-v3.1 coredns-v1.1.3 kubernetes-dashboard-amd64-v1.8.3)
for imageName in ${images[@]} ; do
docker load -i $imageName".tar"
done
docker load -i flannel-v0.10.0-amd64.tar


15.3.2 集群节点加入
查看token:
[root@bigdata k8sjar]# kubeadm token list


token为:otzlnn.g676abrpvefcilrc
[root@bigdata1 kjar]# kubeadm token create
txzm9g.l4hv1mn3d844pk8m
==============================
join出错!!!!!!!!!!!!!~~~~~~~~~~~~~~~~~~~~~~~~~~~~··
==============================
执行内容如下:
[code][root@bigdata1 ~]# kubeadm join 192.168.121.200:6443 --token otzlnn.g676abrpvefcilrc --discovery-token-ca-cert-hash
[code]sha256:84c3957c54c0ffe9e7b9861df46d65332485c8c3adbdf6720e4163a286f45735
[preflight] running pre-flight checks
[WARNING RequiredIPVSKernelModulesAvailable]: the IPVS proxier will not be used, because the following required kernel modules are not loaded: [ip_vs ip_vs_rr ip_vs_wrr ip_vs_sh] or no builtin kernel ipvs support: map[nf_conntrack_ipv4:{} ip_vs:{} ip_vs_rr:{} ip_vs_wrr:{} ip_vs_sh:{}]
you can solve this problem with following methods:
1. Run 'modprobe -- ' to load missing kernel modules;
2. Provide the missing builtin kernel ipvs support
I0910 00:03:09.594082 1613 kernel_validator.go:81] Validating kernel version
I0910 00:03:09.594150 1613 kernel_validator.go:96] Validating kernel config
[discovery] Trying to connect to API Server "192.168.121.200:6443"
[discovery] Created cluster-info discovery client, requesting info from "https://192.168.121.200:6443"
[discovery] Requesting info from "https://192.168.121.200:6443" again to validate TLS against the pinned public key
[discovery] Cluster info signature and contents are valid and TLS certificate validates against pinned roots, will use API Server "192.168.121.200:6443"
[discovery] Successfully established connection with API Server "192.168.121.200:6443"
[kubelet] Downloading configuration for the kubelet from the "kubelet-config-1.11" ConfigMap in the kube-system namespace
[kubelet] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[preflight] Activating the kubelet service
[tlsbootstrap] Waiting for the kubelet to perform the TLS Bootstrap...
[patchnode] Uploading the CRI Socket information "/var/run/dockershim.sock" to the Node API object "bigdata1" as an annotation
This node has joined the cluster:
* Certificate signing request was sent to master and a response
was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the master to see this node join the cluster.
15.3.3 Master Apiserver访问配置
如果不执行以下脚本,则kubelet按默认8080端口连接API Server;新版本kubenetes api server再使用http 8080(默认为0),而是采用https 6443。
[code]mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/kubelet.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
15.4 Deployment & Service & Proxy
15.4.1 Deployment
Deploment继承Pod与Replicaset的所有特性的同时, 它可以实现对template模板进行实时滚动更新。主要职责同样是为了保证pod的数量和健康,90%的功能与Replication Controller完全一样,可以看做新一代的Replication Controller。
Metadata:主要定义labels(k8s-app与spec定的labels不一样)、部署名称、命名空空;
Spec:主要定义labels(服务对象定义的选择器需要引用)、containers(镜像、容器端口)、复本(replicas)
更多对像属性说明,请参考《https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.10/#deployment-v1beta2-apps》
apiVersion:
1) apps/v1 apps/v1beta1 apps/v1beta2(v1已经过时)
2) extensions/v1beta1
containers.args: array(待补充)
[code]kube-springboot-deploment.yaml内容定义如下: kind: Deployment //无状态 apiVersion: apps/v1beta1 metadata: labels: k8s-app: springboot-app name: springboot-app namespace: default spec: replicas: 2 template: metadata: labels: app: mics-app spec: containers: - name: mics-app image: yangdockerrepos/testrepos:dkapptest_1.0 ports: - containerPort: 8888 ---
[code]部署 kubectl create -f kube-springboot-deploment.yaml 更新 kubectl apply-f kube-springboot-deploment.yaml 删除部署(根据部署名称删除) kubectl delete deployment springboot-app 或者 kubectl delete -f kube-springboot-deploment.yaml 查看部署情况: kubectl describe deployment springboot-app -n default kubectl describe deployment/springboot-app -n default
【注】通过deployment发布的应用为无状态应用,部署后只创建EndPoint对象(即为Pod创建EndPoint),并分配IP,如下图所示:

查看运行分布情况:
kubectl get pods -o wide -n default
查看运行日志
kubectl logs -f <pod>
15.4.2 Service
15.4.2.1 服务定义
Servcie 抽象了该如何访问 Kubernetes Pod。
Service 通常会和 Deployment 结合在一起使用,首先通过 Deployment 部署应用程序,然后再使用 Service 为应用程序提供服务发现、负载均衡和外部路由的功能。
配置将创建一个名称为 “springboot-app” 的 Service 对象,它会将请求代理到使用 TCP 端口 8888,并且具有标签 "app= mics-app" 的 Pod 上。 这个 Service 将被指派一个 IP 地址(通常称为 “Cluster IP”),它会被服务的代理使用。 该 Service 的 selector 将会持续评估,处理结果将被 POST 到一个名称为 “springboot-app” 的 Endpoints 对象上。
Kubernetes Service 能够支持 TCP 和 UDP 协议,默认 TCP 协议。
【注意】targetPort:设置Pod容器的端口,否则Service(ClusterIp)在集群内部请无法连接。
[code]#------------------------springboot service---------------------------- kind: Service apiVersion: v1 metadata: labels: k8s-app: springboot-app name: springboot-app namespace: default spec: selector: app: mics-app ports: - protocol: TCP port: 8889 targetPort: 8888
一、无selector服务定义
增加service定义(红色字体):
Metadata:定义内容可以与Deployment一致;
spec :Service 没有 selector,就不会创建相关的 Endpoints 对象;
kube-springboottestapp.yaml内容定义如下:
[code]kind: Deployment apiVersion: apps/v1beta1 metadata: labels: k8s-app: springboot-app name: springboot-app namespace: default spec: replicas: 2 template: metadata: labels: app: mics-app spec: containers: - name: mics-app image: yangdockerrepos/testrepos:dkapptest_1.0 ports: - containerPort: 8888 --- #------------------------springboot service---------------------------- kind: Service apiVersion: v1 metadata: labels: k8s-app: springboot-app name: springboot-app namespace: default spec: type: ClusterIP ports: - protocol: TCP port: 8889 targetPort: 8888
部署后的结果,Service只分配了集群IP,无对应EndPoint对象(无关联Pod对象),如下图所示:

二、有selector定义服务
kube-springboottestapp.yaml内容定义如下:
[code]kind: Deployment apiVersion: apps/v1beta1 metadata: labels: k8s-app: springboot-app name: springboot-app namespace: default spec: replicas: 2 template: metadata: labels: app: mics-app spec: containers: - name: mics-app image: yangdockerrepos/testrepos:dkapptest_1.0 ports: - containerPort: 8888 --- #------------------------springboot service---------------------------- kind: Service apiVersion: v1 metadata: labels: k8s-app: springboot-app name: springboot-app namespace: default spec: selector: app: mics-app ports: - protocol: TCP port: 8889 targetPort: 8888
集群IP(service ip):10.103.82.137
Pod(endpoint):10.244.1.11、10.244.1.12

15.4.2.2 服务类型
对一些应用(如 Frontend)的某些部分,可能希望通过外部(Kubernetes 集群外部)IP 地址暴露 Service。
Kubernetes ServiceTypes 允许指定一个需要的类型的 Service,默认是 ClusterIP 类型。
Type 的取值以及行为如下:
1)ClusterIP:通过集群的内部IP暴露服务,选择该值,服务只能够在集群内部可以访问,这也是默认的ServiceType。
2)NodePort:通过每个Node 上的 IP 和静态端口(NodePort)暴露服务。NodePort 服务会路由到ClusterIP服务,这个ClusterIP服务会自动创建。通过请求 <NodeIP>:<NodePort>,可以从集群的外部访问一个NodePort 服务。
3)LoadBalancer:使用云提供商的负载均衡器,可以向外部暴露服务。外部的负载均衡器可以路由到NodePort服务和ClusterIP服务。
4)ExternalName:通过返回CNAME和它的值,可以将服务映射到 externalName字段的内容(例如foo.bar.example.com)。没有任何类型代理被创建,这只有Kubernetes 1.7或更高版本的 kube-dns才支持。
15.4.2.3 Proxy
在 Kubernetes 集群中,每个 Node 运行一个kube-proxy进程。kube-proxy负责为Service 实现了一种VIP(虚拟 IP)的形式,而不是ExternalName 的形式。
在Kubernetes v1.0 版本,Service 是 “4层”(TCP/UDP over IP)概念代理完全在userspace。
在Kubernetes v1.1 版本,新增了Ingress API(beta 版),用来表示 “7层”(HTTP)服务,添加了Iptables代理,
从Kubernetes v1.2 起,默认就是iptables代理。Kubernetes v1.8.0-beta.0, 添加ipvs代理。
(一)Proxy-mode: userspace
略
(二)Proxy-mode: iptables
这种模式,kube-proxy 会监视 Kubernetes master 对 Service 对象和 Endpoints 对象的添加和移除。对每个Service,它会安装iptables 规则,从而捕获到达该Service的clusterIP(虚拟 IP)和端口的请求,进而将请求重定向到Service的一组backend中的某个上面。对于每个Endpoints对象,它也会安装iptables 规则,这个规则会选择一个backend Pod。
默认的策略是,随机选择一个backend。 实现基于客户端 IP 的会话亲和性,可以将 service.spec.sessionAffinity 的值设置为 "ClientIP" (默认值为 "None")。
和 userspace 代理类似,网络返回的结果是,任何到达 Service 的 IP:Port 的请求,都会被代理到一个合适的 backend,不需要客户端知道关于 Kubernetes、Service、或 Pod 的任何信息。这应该比 userspace 代理更快、更可靠。
然而,不像 userspace 代理,如果初始选择的Pod没有响应,iptables 代理能够自动地重试另一个Pod,所以它需要依赖readiness probes。
(三)Proxy-mode: ipvs
15.4.3 运行与参数
(一)Docker 与 K8s运行参数

总结:
- Docker通过Cmd传递给ENTRYPOINT或者传递运行参数,如docker run
- K8s通过args传递
(二)Docker vs K8s 环境变量
1. Docker 通过-e name=value传递
2. K8s中通过EVN传递,Deployment API版本不同,注意值的类型。

3.实验中,如果docker entrypoint为java命令,K8s中可以通过arg传递环境变量,格式如下(待验证):
args: [“--server.port=8088”,”--spring.application.name=mics-app-1”]
15.5 Application deployment
15.5.1 无状态应用
kubectl apply -f https://k8s.io/examples/application/deployment-update.yaml
kubectl describe deployment nginx-deployment
kubectl get pods -l app=nginx
kubectl describe pod <pod-name>
kubectl delete deployment nginx-deployment
15.5.2 有状态应用
1)Deploy the PV and PVC of the YAML file:
kubectl create -f https://k8s.io/examples/application/mysql/mysql-pv.yaml
2)Deploy the contents of the YAML file:
kubectl create -f https://k8s.io/examples/application/mysql/mysql-deployment.yaml
3)Another
kubectl describe deployment mysql
kubectl describe pvc mysql-pv-claim
kubectl get pods -l app=mysql
4)Connection mysql
kubectl run -it --rm --image=mysql:5.6 --restart=Never mysql-client -- mysql -h mysql -ppassword
5)Delete deploment
kubectl delete deployment,svc mysql
kubectl delete pvc mysql-pv-claim
kubectl delete pv mysql-pv-volume
15.6 部署实战分析
15.6.1 无状态部署
1)准备Docker镜像
2)编写kube-springboottestapp.yaml,内容如下:
[code]kind: Deployment apiVersion: apps/v1beta1 metadata: labels: k8s-app: springboot-app name: springboot-app namespace: default spec: replicas: 2 template: metadata: labels: app: mics-app spec: containers: - name: mics-app image: yangdockerrepos/testrepos:dkapptest_1.0 ports: - containerPort: 8888
3)通过K8s控制台部署菜单

或通过命令行
kubectl create -f kube-springboottestapp.yaml
效果:

查看Pod列表信息:
kubectl get pods -l app=mics-app

查看部署信息(Deploment):
kubectl describe deployment springboot-app
查看Pod信息,执行如下:
-n default :指定命名空间为default
kubectl describe pod springboot-app -n default
部署情况:部署在节点bigdata1,2个实例,ip分别是10.244.1.6、10.244.1.5
[code][root@bigdata k8sjar]# kubectl describe pod springboot-app -n default Name: springboot-app-758d78957c-m4r5p Namespace: default Priority: 0 PriorityClassName: <none> Node: bigdata1/192.168.121.201 Start Time: Wed, 12 Sep 2018 13:39:38 +0800 Labels: app=mics-app pod-template-hash=3148345137 Annotations: <none> Status: Running IP: 10.244.1.6 Controlled By: ReplicaSet/springboot-app-758d78957c Containers: mics-app: Container ID: docker://091251960c2db8687762c35aec69c81213de051c2f70be6afbd72327ec32a358 Image: yangdockerrepos/testrepos:dkapptest_1.0 Image ID: docker://sha256:e42e18fd2aac5267dba5a1a1237ffbfe9076aa96466b3be5cfab478c26a4cf66 Port: 8888/TCP Host Port: 0/TCP State: Running Started: Wed, 12 Sep 2018 13:39:49 +0800 Ready: True Restart Count: 0 Environment: <none> Mounts: /var/run/secrets/kubernetes.io/serviceaccount from default-token-vp89m (ro) Conditions: Type Status Initialized True Ready True ContainersReady True PodScheduled True Volumes: default-token-vp89m: Type: Secret (a volume populated by a Secret) SecretName: default-token-vp89m Optional: false QoS Class: BestEffort Node-Selectors: <none> Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s node.kubernetes.io/unreachable:NoExecute for 300s Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Pulled 24m kubelet, bigdata1 Container image "yangdockerrepos/testrepos:dkapptest_1.0" already present on machine Normal Created 24m kubelet, bigdata1 Created container Normal Started 24m kubelet, bigdata1 Started container Normal Scheduled 24m default-scheduler Successfully assigned default/springboot-app-758d78957c-m4r5p to bigdata1 Name: springboot-app-758d78957c-mtxqt Namespace: default Priority: 0 PriorityClassName: <none> Node: bigdata1/192.168.121.201 Start Time: Wed, 12 Sep 2018 13:39:38 +0800 Labels: app=mics-app pod-template-hash=3148345137 Annotations: <none> Status: Running IP: 10.244.1.5 Controlled By: ReplicaSet/springboot-app-758d78957c Containers: mics-app: Container ID: docker://f65ab151650eb44186af1c70bcc1f92227046fc4f6a1c90b2f02d28a19afe656 Image: yangdockerrepos/testrepos:dkapptest_1.0 Image ID: docker://sha256:e42e18fd2aac5267dba5a1a1237ffbfe9076aa96466b3be5cfab478c26a4cf66 Port: 8888/TCP Host Port: 0/TCP State: Running Started: Wed, 12 Sep 2018 13:39:49 +0800 Ready: True Restart Count: 0 Environment: <none> Mounts: /var/run/secrets/kubernetes.io/serviceaccount from default-token-vp89m (ro) Conditions: Type Status Initialized True Ready True ContainersReady True PodScheduled True Volumes: default-token-vp89m: Type: Secret (a volume populated by a Secret) SecretName: default-token-vp89m Optional: false QoS Class: BestEffort Node-Selectors: <none> Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s node.kubernetes.io/unreachable:NoExecute for 300s Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Pulled 24m kubelet, bigdata1 Container image "yangdockerrepos/testrepos:dkapptest_1.0" already present on machine Normal Created 24m kubelet, bigdata1 Created container Normal Started 24m kubelet, bigdata1 Started container Normal Scheduled 24m default-scheduler Successfully assigned default/springboot-app-758d78957c-mtxqt to bigdata1
访问地址(只限集群内部访问,部署yaml未做端口映射):
http://10.244.1.5:8888/dockerApp/test/log

网络分析:
15.6.2 服务部署
15.6.2.1 集群内部访问
一、通过service访问集群内部服务(Pod-to-Pod)
按以下文件,部署启动服务springboot-app、springboot-app2,用于验证集群内部Pod通过service name访问集群内部另一个Pod。
【备注】本实例还通NodePort开放集群外部访问,此节不做说明。
服务1:springboot-app
[code]kind: Deployment apiVersion: apps/v1beta1 metadata: labels: k8s-app: springboot-app name: springboot-app namespace: default spec: replicas: 2 template: metadata: labels: app: mics-app spec: containers: - name: mics-app image: yangdockerrepos/testrepos:dkapptest_1.0 ports: - containerPort: 8888 --- #------------------------springboot service------------------------------ kind: Service apiVersion: v1 metadata: labels: k8s-app: springboot-app name: springboot-app namespace: default spec: type: NodePort selector: app: mics-app ports: - protocol: TCP port: 8889 targetPort: 8888 nodePort: 30000
服务2:springboot-app2
[code]kind: Deployment apiVersion: apps/v1beta1 metadata: labels: k8s-app: springboot-app2 name: springboot-app2 namespace: default spec: replicas: 2 template: metadata: labels: app: mics-app2 spec: containers: - name: mics-app2 image: yangdockerrepos/testrepos:dkapptest_1.0 ports: - containerPort: 8888 --- #------------------------springboot service------------------------------ kind: Service apiVersion: v1 metadata: labels: k8s-app: springboot-app2 name: springboot-app2 namespace: default spec: type: NodePort selector: app: mics-app2 ports: - protocol: TCP port: 8899 targetPort: 8888 nodePort: 30001
部署启动后2个服务运行正常,效果如下图所示:

查询Pod列表
kubectl get pods -o wide -n default

进入服务1的Pod,用以访问服务2的Pod
kubectl exec -it springboot-app-758d78957c-lkrfr -- /bin/sh # apk --update upgrade && apk add curl
访问请求:
curl http://springboot-app2:8889/dockerApp/test/log

结论:集群内部Pod-to-Pod,可以通过Service Name相互访问。
15.6.2.2 集群外部访问
一、NodePort
将服务按如下要求修改:
- spec.type: NodePort
- spec.ports.nodePort: 9999定义访问端口(30000-32767)
kube-proxy会自动将流量以round-robin的方式转发给该service的每一个pod
[code]#------------------------springboot service------------------------------ kind: Service apiVersion: v1 metadata: labels: k8s-app: springboot-app name: springboot-app namespace: default spec: type: NodePort selector: app: mics-app ports: - protocol: TCP port: 8889 targetPort: 8888 nodePort: 9999
配置type=NodePort会自动创建集群ClusterIp(serviceip),用于集群内部访问,使用<CluserIp>:<port>。
同时还创建了30000端口,用于外部访问要求,使用<NodeIP>:<nodePort>访问。
如下图示,service name=springboot-app关联。

二、Ingress
参考15.8节
Ngnix-Ingress/Nginx-gce:
https://kubernetes.io/docs/concepts/services-networking/ingress/
https://www.mkubaczyk.com/2017/12/13/kubernetes-ingress-controllers-nginx-gce-google-kubernetes-engine/
https://kubernetes.github.io/ingress-nginx/
Ngnix-Ingress install:
https://github.com/nginxinc/kubernetes-ingress/blob/release-1.4/docs/installation.md(install)
https://github.com/nginxinc/kubernetes-ingress/blob/release-1.4/build/README.md(build)
1.NGINX Image
docker pull nginx/nginx-ingress:latest
We provide such an image though DockerHub for NGINX. If you are using NGINX Plus, you need to build the image.(如果需要NGINX PLUS镜像需要自己编译,NGINX PLUS 功能比NGINX多,可以自动更新配置等)
2.
Make sure to run the docker login command first to login to the registry. If you’re using Google Container Registry, you don’t need to use the docker command to login -- make sure you’re logged into the gcloud tool (using the gcloud auth login command) and set the variable PUSH_TO_GCR=1 when running the make command
3. Clone the Ingress controller repo
$ git clone https://github.com/nginxinc/kubernetes-ingress/
4. Build the image
For NGINX:
$ make clean
$ make PREFIX=myregistry.example.com/nginx-ingress
myregistry.example.com/nginx-ingress defines the repo in your private registry where the image will be pushed. Substitute that value with the repo in your private registry.
As the result, the image myregistry.example.com/nginx-ingress:1.4.0 is built and pushed to the registry. Note that the tag 1.4.0 comes from the VERSION variable, defined in the Makefile.
For NGINX PLUS:
first, make sure that the certificate (nginx-repo.crt) and the key (nginx-repo.key) of your license are located in the root of the project:
$ ls nginx-repo.*
nginx-repo.crt nginx-repo.key
Then run:
$ make clean
$ make DOCKERFILE=DockerfileForPlus PREFIX=192.168.2.32/nginx-plus-ingress

myregistry.example.com/nginx-plus-ingress defines the repo in your private registry where the image will be pushed. Substitute that value with the repo in your private registry.
As the result, the image myregistry.example.com/nginx-plus-ingress:1.4.0 is built and pushed to the registry. Note that the tag 1.4.0 comes from the VERSION variable, defined in the Makefile.
Kong-Ingress:

三、LoadBalance
15.7 网络分析(Linux route/bridge/iptables/nat)
flannel 是一个中心化的 overlay 容器网络,设计简单,容易理解,对于 k8s 来说,有一个假设:所有容器都可以和集群里任意其他容器或者节点通信,并且通信双方看到的对方的 IP 地址就是实际的地址,主要的好处就是不需要任何的端口映射和地址转换,拥有一张扁平的网络更容易管理,而且由于是基于 Etcd 的中心化的管理,所以对于一些 IP 变化异常频繁的场景来说,比一些去中心化的方案能够较及时同步网络拓扑关系。(参考http://www.qingpingshan.com/m/view.php?aid=382091)
1)Linux可以工作在网桥模式,必须安装网桥工具
yum install bridge-utils
2)查看本机网络桥情况,资源参考:https://www.tldp.org/HOWTO/BRIDGE-STP-HOWTO/set-up-the-bridge.html
brctl show
3)查看路由表
ip route
或
route -n
4)查看Nat表
Iptables -t nat -nL
查看规则配置信息(详细)
iptables-save | grep 10.104.9.111


5)查看flannel分本给本机网络段
cat /run/flannel/subnet.env
//=================================================
导出镜像脚本
[code]docker save -o kube-proxy-amd64-v1.11.2.tar k8s.gcr.io/kube-proxy-amd64:v1.11.2 docker save -o kube-controller-manager-amd64-v1.11.2.tar k8s.gcr.io/kube-controller-manager-amd64:v1.11.2 docker save -o kube-apiserver-amd64-v1.11.2.tar k8s.gcr.io/kube-apiserver-amd64:v1.11.2 docker save -o kube-scheduler-amd64-v1.11.2.tar k8s.gcr.io/kube-scheduler-amd64:v1.11.2 docker save -o coredns-v1.1.3.tar k8s.gcr.io/coredns:1.1.3 docker save -o etcd-amd64-v3.2.18.tar k8s.gcr.io/etcd-amd64:3.2.18 docker save -o kubernetes-dashboard-amd64-v1.8.3.tar k8s.gcr.io/kubernetes-dashboard-amd64:v1.8.3 docker save -o flannel-v0.10.0-amd64.tar quay.io/coreos/flannel:v0.10.0-amd64 docker save -o pause-v3.1.tar k8s.gcr.io/pause:3.1
标记并上传私有镜像库
[code]#!/bin/bash
images=(kube-apiserver-amd64:v1.11.2 kube-controller-manager-amd64:v1.11.2 kube-scheduler-amd64:v1.11.2 kube-proxy-amd64:v1.11.2 pause:3.1 etcd-amd64:3.2.18 coredns:1.1.3 kubernetes-dashboard-amd64:v1.8.3)
for imageName in ${images[@]} ; do
docker tag k8s.gcr.io/$imageName 192.168.2.32:5000/$imageName
docker push 192.168.2.32:5000/$imageName
docker image rm k8s.gcr.io/$imageName
done
导入离线包至docker镜像库
[code]#!/bin/bash
images=(kube-apiserver-amd64-v1.11.2 kube-controller-manager-amd64-v1.11.2 kube-scheduler-amd64-v1.11.2 kube-proxy-amd64-v1.11.2 pause-v3.1 etcd-amd64-v3.2.18 coredns-v1.1.3 kubernetes-dashboard-amd64-v1.8.3)
for imageName in ${images[@]} ; do
docker load -i $imageName".tar"
done
15.8 Kong Ingress Controller

https://github.com/Kong/kubernetes-ingress-controller/tree/master/docs/deployment
【注意】上述安装此文档集成kong到
kubernetes存在问题,ingress-controller.yaml的服务自动清除通过kong-dashboard添加的服务以及路由信息。
(一)Kong Ingress Controller 安装方式选择
Kong ingress controller can be installed on a local or managed Kubernetes cluster. Here are some guides to get you started:
1、Using minikube: (本地微K8s,可以本地windows安装)
If you have a local Minikube instance running, this guide will help you deploy the Ingress Controller.
Notes: This setup does not provide HA for PostgreSQL
2.Using openshift/minishift: (红帽容器应用平台,平台集成docker+k8s)
Openshift is a Kubernetes distribution by Redhat and has few minor differences in how a user logs in using oc CLI.
Notes:
This setup does not provide HA for PostgreSQL
Because of CPU/RAM requirements, this does not work in OpenShift Online (free account)
3. Goolge Kubernetes Engine(GKE): (基于google k8s)
GKE is a managed Kubernetes cluster service. This guide is a walk through to setup Kong Ingress Controller on GKE alongwith TLS certs from Let's Encrypt.
4. Azure Kubernetes Service(AKS)): (基于微软Azure 容器应用平台)
AKS is another managed Kubernetes cluster service. This guide is a walk through to setup Kong Ingress Controller on AKS.
上述4种环境(本地或集群)下安装Kong Ingress Controller,本文档重点描述基于GKE方式Kong Ingress Controller
(二)Kong Ingress Controller原理及集成说明:

15.8.1 Kubernetes集成Kong
联网获取部署文件:
namespace.yaml
postgres.yaml
kong_postgres.yaml
pv.yaml(参考小节15.8.2)
kong_migration_postgres.yaml(参考小节15.8.2)
共5个文件
拉取下述镜像到私有仓库:
postgres:9.6
kong:0.14.1-centos
共2个镜像
15.8.1.1 镜像及部署文件准
1.将镜像上传至统一私有镜像仓库:
docker push 192.168.2.32:5000/postgres:9.6
docker push 192.168.2.32:5000/ kong:0.14.1-centos
2.增加或修改描述文件namespace.yaml、postgres.yaml、kong_ postgres.yaml
增加namespaces.yaml
[code]apiVersion: v1 kind: Namespace metadata: name: kong --- Postgres.yaml修改前: spec: containers: - name: postgres image: postgres:9.6 postgres.yaml修改后: spec: containers: - name: postgres image: 192.168.2.32:5000/postgres:9.6
3.Kong_postgres修改后
主要修改:
1)type=NodePort
2)引用镜像
3)增加命名空间namespaces=kong
[code]apiVersion: v1 kind: Service metadata: name: kong-proxy namespace: kong spec: type: NodePort ports: - name: kong-proxy port: 8000 targetPort: 8000 protocol: TCP selector: app: kong --- apiVersion: v1 kind: Service metadata: name: kong-proxy-ssl namespace: kong spec: type: NodePort ports: - name: kong-proxy-ssl port: 8443 targetPort: 8443 protocol: TCP selector: app: kong --- apiVersion: v1 kind: Service metadata: name: kong-admin namespace: kong spec: type: NodePort ports: - name: kong-admin port: 8001 targetPort: 8001 protocol: TCP selector: app: kong --- apiVersion: v1 kind: Service metadata: name: kong-admin-ssl namespace: kong spec: type: NodePort ports: - name: kong-admin-ssl port: 8444 targetPort: 8444 protocol: TCP selector: app: kong --- apiVersion: extensions/v1beta1 kind: Deployment metadata: name: kong namespace: kong spec: replicas: 2 template: metadata: labels: name: kong app: kong spec: containers: - name: kong image: 192.168.2.32:5000/kong:0.14.1-centos env: - name: KONG_ADMIN_LISTEN value: "0.0.0.0:8001, 0.0.0.0:8444 ssl" - name: KONG_PG_PASSWORD value: kong - name: KONG_PG_HOST value: postgres - name: KONG_PROXY_ACCESS_LOG value: "/dev/stdout" - name: KONG_ADMIN_ACCESS_LOG value: "/dev/stdout" - name: KONG_PROXY_ERROR_LOG value: "/dev/stderr" - name: KONG_ADMIN_ERROR_LOG value: "/dev/stderr" ports: - name: admin containerPort: 8001 protocol: TCP - name: proxy containerPort: 8000 protocol: TCP - name: proxy-ssl containerPort: 8443 protocol: TCP - name: admin-ssl containerPort: 8444 protocol: TCP
3. 增加pv.yaml
增加PV,用于存储数据库数据(数据库前执行)
[code]apiVersion: v1 kind: PersistentVolume metadata: name: pv0001 spec: capacity: storage: 1Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Recycle storageClassName: "" hostPath: path: /opt/pgdata
如果缺少此部,数据无法持久化,出现下述问题:
执行kubectl apply -f postgres.yaml 挂起,导致kong、kong-ingress-controller任务处于等待状态。获取事件信息进行分析,执行:
kubectl get events -n kong
错误信息:
1)no persistent volumes available for this claim and no storage class is set
2)pod has unbound PersistentVolumeClaims (repeated 2 times)

4.数据库前准备
如果忽略此步,通过获取日志获取如下错误信息:
[code]waiting for db 2019/01/15 01:42:13 [warn] postgres database 'kong' is missing migration: (response-transformer) 2016-05-04-160000_resp_trans_schema_changes Error: /usr/local/share/lua/5.1/kong/cmd/start.lua:37: [postgres error] the current database schema does not match this version of Kong. Please run `kong migrations up` to update/initialize the database schema. Be aware that Kong migrations should only run from a single node, and that nodes running migrations concurrently will conflict with each other and might corrupt your database schema! Run with --v (verbose) or --vv (debug) for more details
增加:kong_migration_postgres.yaml
【注意】红色标注:1)namespace值与要连接的数据,如postgresql相同,跨命名空间是无法直接使用kubernetes service服务发现。2)KONG_PG_HOST修改为postgresql部署服务名称。3)
[code]apiVersion: batch/v1 kind: Job metadata: name: kong-migration namespace: kong //必须与数据同一命令 spec: template: metadata: name: kong-migration spec: containers: - name: kong-migration image: 192.168.2.32:5000/kong:0.14.1-centos env: - name: KONG_NGINX_DAEMON value: 'off' - name: KONG_PG_PASSWORD value: kong - name: KONG_PG_HOST value: postgres command: [ "/bin/sh", "-c", "kong migrations up" ] restartPolicy: Never
15.8.1.2 部署步聚
严格按下列顺序执行:
kubectl apply -f namespace.yaml &&
kubectl apply -f pv.yaml &&
kubectl apply -f postgres.yaml &&
kubectl apply -f kong_migration_postgres.yaml &&
kubectl delete -f kong_migration_postgres.yaml &&
kubectl apply -f kong_postgres.yaml &&
部署效果
Pod列表:
kubectl get pods -n kong -o wide

Service列表:
kubectl get svc -n kong -o wide

更多资源请参考:https://docs.konghq.com/install/kubernetes/
验证成功(集群内方访问):
http://10.105.225.203:8001 //管理地址
http://10.96.232.138:8000 //代理地址
https://10.105.251.0:8443 //代理地址(安全)
15.8.2 Kong dashboard

1)下载镜像:
docker pull pgbi/kong-dashboard:v3.5.0
2)在Docker启动kong-dashboard
docker run --rm -p 8080:8080 pgbi/kong-dashboard:v3.5.0 start --kong-url http://192.168.2.32:30363
http://192.168.2.32:8080

3)基于Kubernetes运行合符应用部署方式,所以讨论在kubernetes部署kong dashboard面板。
[code]Kong-dashboard.yaml: apiVersion: v1 kind: Service metadata: name: kong-dashboard-web namespace: kong spec: type: NodePort ports: - name: kong-board-m port: 8080 targetPort: 8080 protocol: TCP selector: app: kong-dashboard-c --- apiVersion: extensions/v1beta1 kind: Deployment metadata: name: kong-dashboard-c namespace: kong spec: template: metadata: labels: name: kong-dashboard-c app: kong-dashboard-c spec: containers: - name: kong-dashboard-c image: 192.168.2.32:5000/kong-dashboard:v3.5.0 command: ["bin/kong-dashboard.js", "start" ] args: ["--kong-url=http://kong-admin:8001"] ports: - name: kong-board-p containerPort: 8080 protocol: TCP ---
15.8.3 Kong service/route
15.8.3.1 Service
服务根据upstream名称指定访问后端
服务与路由是一对多关系
15.8.3.2 Routes
路由规则:
1)头部增加关键字主机
2)根据路径匹配
15.8.3.3 安全认证(JWT)
一、安全认证架构图
二、创建Consumer
curl -X POST http://10.105.225.203:8001/consumers -d "username=test"
响应返回,获取consumer id,用于后续配置关联插件。
{"custom_id":null,"created_at":1547772896,"username":"test","id":"34d4b695-74e0-45eb-bcce-1f631247b6f8"}
三、启用JWT插件
登录kong-dashboard,点击左边Plugins,添加添加插件

选择jwt,配置应用个api或者service或者routes

配置验证字段(exp)及token提交参数方式等

以上通过管理控制页面启用,也通过命令行启用,本节不再详述。
三、准备密钥对
通过Linux平台中openssl工具生成密钥对,免密码
ssh-keygen -t rsa -b 4096 -f jwtrsa256.key

执行后,在当前目录下生成2个文件,jwtrsa256.key(私钥),jwtrsa256.key.pub(公钥)

因jwtrsa256.key.pub格式不符合PEM格式要求,所以执行下命令转换:
openssl rsa -in jwtrsa256.key -pubout -outform PEM -out jwtrsa256.key.pub
四、Consumer与插件关联
关联通过consumer id与jwt关系构建,通地提交的URL地址可以看出。
通kong-dashboard提交创建rsa jwt,一直提示invalid rsa_public_key,所以采用下述可行方式提交(表单POST):
curl -X POST http://10.105.225.203:8001/consumers/{consumer}/jwt -F "algorithm=RS256" -F "rsa_public_key=@/opt/kjar/kong/jwtrsa256.key.pub"
执行后返回如下,获取返回结果中的key值,用于后续构建访问token
启动jwt插件时默认配置key_claim_name=iss,则提交的JWT的头部或载体中需要设置iss=key值。可以通过https://jwt.io/ debugger 构建测试JWT值。
填写头或载体信息,注意iss值:

根据提示填写密钥对信息,点击share jwt按钮,则可生成左边的jwt值

JWT值

五、请求接口
在启用JWT插件时,配置了uri_param_names=jwt,则通过uri jwt参数名传递访问token,其它方式请参考官网文档。
[code]curl http://10.96.232.138:8000/conf/sc-dev.yml?jwt=eyJhbGciOiJSUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJNWU1STW9GWkRqMmJLbWVGU2gwSjR4Z0Fkb2lQcGVsOCIsImV4cCI6MTU0Nzc3NTI2MCwidXNlcl9uYW1lIjoib3l5bCIsImp0aSI6ImMxZjYxOGFmLTczMGItNGEzNS1hMzkxLWZkMDkzMjRjYzYwYSIsImNsaWVudF9pZCI6InFxIiwic2NvcGUiOlsicmVhZCIsIndyaXRlIl19.zKSJrSP92S6M-4exHmtymB8kOi9-fh7NGhUwVr2cZg3qPo30iK_PJ5QqJ5EdFw70YAy-ke6IkXj26AQev2wRsZJubrFVmjI0-k0tQoC3vt3advXkiv22xAOzub-i5nm08N4WU6_s3EcxGhlZt80xkSIxfTWD79Iz3JAJvEbiSKr4rL6nHFO5zZaakXg26GVN9ESg_AKewDKeew8NhKeCJ6DPxROCkxHVxD9DAMyTUPsMrzVGsWzAfhxmlvK5sPJZJkAbvcQjXSyBlzMNN5_xQXI8m38Fg072Fk_sVZ2KCNMY2zjHGUpG4mg4zPKA6NXVqVzGhQ4xNi5hB7-91AQ_ObYvFbri9VxF5p4XnI1cpQoNBHg9CagE0PW95wz0cOj8be64ueeWwcwow0rpzZOMfLurBjCJQYbpvdQZkmVEy5IWH2CL58HGcy84d8WQqzAknouMGeMiQu_ctB9ZradbXMO_h0UZkgmFegDhOmQ2t83B5rvgaC17-uFpfa3GAN8_6g2tEr-Lk6BbqYmv_XYXPkYSqv07D1xQ90mQ1jZDru2JdzLcYTxJVYZa2mqf1vliswFHOIjw9zMoLTh9PvxLZK-NZyk7uQ7RG6blF5EUgYWiQ-p3pBex0LcvSoWi3XA6xLBYm9M8OYAyAxZzskidizdJToPkRSMaCMAw848V3P8
jwt过期后效果如下:
[code]{
"exp":"token expired"
}
同时jwt值会传递给后端服务,后端服务获取playload解码获取用户名。
15.8.3.4 流量控制
可以针对服务service、路由route、消费者consumer,进行流量控制。具体添加插件方法可以通过命令行模式请求kong admin(8001),也可以通过kong-dashboard添加,不再详述添加说明。
[注意]下述参数:
policy:cluster、local、redis
性能:redis > cluster > local,推荐用redis
策略切换时,不要同步数据,所在对于小维度(分钟、秒)问题不在,但是对按月则需要小心。

(二)时间维度:按分钟、秒、小时、天、月、年。如100次/秒
(三)Limit by:限制的实体是IP、cosumer、credential(凭证)
15.8.3.5 调用链(Zipkin)
调用链主要4个组件:
- Collector:收集数据如brave,sleuth等,采集到的数据主要通过3种传输方式传递到存储:HTTP, Kafka and Scribe
- storage
- search
- ui

部署主要3包:zipkin-server(search、UI)、存储(mysql、elasticsearch等)、collector
一、安装Elasticsearch集群
10.2.20.11:9200/9300
10.2.20.12:9200/9300
10.2.20.13:9200/9300
二、启动zipkin-server
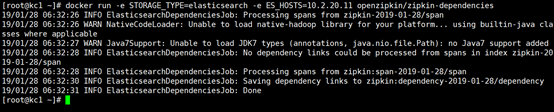
配置环境变量STORAGE_TYPE=ealsticsearch,跟踪链数据存储在elasticsearch,其它可配置类型mysql、cassandra等。依赖镜像openzipkin/zipkin
docker run -d -p 9411:9411 -e STORAGE_TYPE=elasticsearch -e ES_HOSTS=10.2.20.11 openzipkin/zipkin
【备注】采集的数据存储elasticsearch按天创建索引库,index格式如下:zipkin:span-2019-01-28
三、服务依赖镜像
【注意】基于Elasticsearch、cassandra存储需要额外安装openzipkin/zipkin-dependencies,详细配置说明请参考Github
docker run -e STORAGE_TYPE=elasticsearch -e ES_HOSTS=10.2.20.11 openzipkin/zipkin-dependencies
zipkin-dependencies任务只分析今天所有调用链数据,意味着你需要周期性在24点前运行。待分析数据如: elasticsearch index zipkin:span-2019-01-28),基于ES分析结果存储格式为:zipkin:dependency-2019-01-28
四、调用链实例
实例背景说明:
实例采用技术kong、springboot、docker、kubernetes、sleuth、zipkin、elasticsearch。Kong启用zipkin,后续实现调用链跟踪,有2种方法可选:
(1)各微服务之间调用都经过kong,微服务之间不直接调用,调用链信息由kong采集传输至zipkin,在kong中配置待跟踪的服务,架构如下图所示:
(2)kong只负责对外请求的路由,仅初始化调用链信息,微服务之前调用链信息,由各微服务采集并传输至zipkin,架构如下图示:
本实例采用第二种方法,各微务通过sleuth采集span跟踪信息。
POM引用zipkin span采用工具sleuth
[code]<!-- sleuth start --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency> <!-- sleuth end -->
application.yml
配置清单:
spring.zipkin.baseUrl:zipkin地址。
server.port: 直接在K8s配置,也可以本文件配置key,值用${变量名}代替。
server.contextPath:直接在K8s配置,也可以本文件配置key,值用${变量名}代替。
app.service.url:自定环境变量Key,用于指定调用服务接口地址。
[code]spring:
zipkin:
discoveryClientEnabled: false
baseUrl: ${ZIPKIN_BASE_URL}
sleuth:
sampler:
percentage: 1
server:
contextPath: ${APP_CONTEXT}
app:
service:
url: ${APP_INVOKE_URL}
【注意】上述变量值采用${变量名}代替,变量名采用大写字母,由docker或K8s通过环境变量传值。
调用接口逻辑
对外开放接口path: .../api/zipkin/test,对应方法invokeAnotherService
[code]package com.sunshine.recog.controller;
import java.util.HashMap;
import java.util.Map;
import javax.servlet.http.HttpServletRequest;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
import com.sunshine.recog.utils.Codecs;
/**
* This user interface is not verify token is valid
* just only decode playload
* @author oyyl
* @since 2019/1/18
*
*/
@RestController
@RequestMapping("/api")
public class DockerAppController {
@Autowired
private RestTemplate restTemplate;
@Value("${app.service.url}")
public String url;
/**
* Parse JWT value
* JWT include three segement:
* The first is : header
* The second is : playload
* The last is: singer
* @param jwt
* @return
*/
private Map decodeToken(String jwt){
String[] _jwt = jwt.split("\\.");
String jwt_playload = Codecs.utf8Decode(Codecs.b64UrlDecode(_jwt[1].toString()));
String jwt_header = Codecs.utf8Decode(Codecs.b64UrlDecode(_jwt[0].toString()));
Map map = new HashMap<>();
map.put("jwt_playload", jwt_playload);
map.put("jwt_header", jwt_header);
return map;
}
@RequestMapping(value = "/token/info", produces = "application/json")
public Object test(HttpServletRequest request){
String header_auth = request.getHeader("Authorization");
String jwt = null;
try {
if(header_auth != null){
// format: Bearer + 空格 + token
String[] val = header_auth.split(" ");
if(val.length==2 && "Bearer".equals(val[0])){
return decodeToken(val[1]);
}
}
jwt = request.getParameter("jwt");
if(jwt == null || "".equals(jwt))
return "{\"msg\":\"Not provide jwt parameter\"}";
} catch (Exception e) {
String emsg = "Unkown Excepton," + e.getMessage();
return "{\"msg\":\""+emsg+"\"}";
}
return decodeToken(jwt);
}
/**
* zipkin invoke trace test
* @return
*/
@RequestMapping(value = "/zipkin/test", produces = "application/json")
public Object invokeAnotherService(){
return restTemplate.getForEntity(url, String.class);
}
}
打包清单
所有文件清单:
dockerApp:项目文件
startService-linux.sh:启动脚本
DockerFile:docker描述文件
Kube-*:K8s描述文件,模拟2个服务,所以存在2份文件

dockerApp目录:

源码存放路径:https://github.com/yangyangmyself/dockerapp/tree/master/SpringDockerApplication-zipkin
15.8.3.6 健康检查与断路器
一、健康检查分类
健康检查与断路器通过配置upstream,upstream包括一个或多个target,每个target指向不同IP地址(或主机)和端口。检查各个target,根据是否响应判断健康与不健康,环形负载器路由到健康target上。
支持2种健康检查:
1)active check:定期(以一定的频率)请求到指定的Http端点(即接口),根据响应决定端点是否健康。
2)passive check(即断路器)Kong分析正在代理的流量,并根据目标的行为响应(状态码)请求来确定目标的健康状况。
健康检查与断路器:
相同点:根据主动探针与被动检查产生的数据(响应头、错误、超时等)的累加器次数与设置的阀值对比,以此确认健康与否。
计算方式:
Either an active probe (on active health checks) or a proxied request (on passive health checks) produces data which is used to determine whether a target is healthy or unhealthy. A request may produce a TCP error, timeout, or produce an HTTP status code. Based on this information, the health checker updates a series of internal counters:
1)If the returned status code is one configured as “healthy”, it will increment the “Successes” counter for the target and clear all its other counters;
2)If it fails to connect, it will increment the “TCP failures” counter for the target and clear the “Successes” counter;
3)If it times out, it will increment the “timeouts” counter for the target and clear the “Successes” counter;
4)If the returned status code is one configured as “unhealthy”, it will increment the “HTTP failures” counter for the target and clear the “Successes” counter.
If any of the “TCP failures”, “HTTP failures” or “timeouts” counters reaches their configured threshold, the target will be marked as unhealthy.
If the “Successes” counter reaches its configured threshold, the target will be marked as healthy.
区别:
Active健康检查:检查target下指定的http端点,所以需要配置http端点
Passive健康检查:断路器,检查全局target
二、启用健康检查
启用Active健康检查:
1、配置http端点(探针)
转存失败重新上传取消
2)配置检查执行频率
转存失败重新上传取消
3)配置健康与非健康阀值
实现原理:监控各个指标累计器数量与预设的阀值对比。
(1)Http健康阀值相关配置:
healthchecks.active.healthy.successes、healthchecks.active.healthy.http_statues
转存失败重新上传取消
(2)TCP失败阀值(非健康):
healthchecks.active.unhealthy.tcp_failures
(3)http 端点超时阀值(非健康)
healthchecks.active.unhealthy.timeouts对比参考healthchecks.active.timeout配置值
(4)http 失败阀值(非健康)
healthchecks.active.unhealthy.http_failures对比根据healthchecks.active.unhealthy.http_statuses累计值
启用Passive健康检查:
1)断路阀值 :healthchecks.passive.healthy.successes
累加器:healthchecks.passive.healthy.http_statuses
2)healthchecks.passive.unhealthy.tcp_failures
3)healthchecks.passive.unhealthy.timeouts
4)断路阀值 :healthchecks.passive.unhealthy.http_failures
累加器:healthchecks.passive.unhealthy.http_statuses
三、禁用健康检查
禁用健康检查:
禁用Active healthy,将下述值设置为0
healthchecks.active.healthy.interval=0
healthchecks.active.unhealthy.interval=0
禁用Passive healthy
healthchecks.passive 下各个阀值配置为0
四、服务架构(待实践)
场景一
基于docker容器及K8s编排工具,服务负载在K8s实现。Api网关基于kong,在kong启用断路器,而kong断路器针对target实现。Kong与微服务同部署在K8s集群,且同一命名空间下。target配置K8s服务名称及端口,访问微服务,由K8s这端完成服务发现与负载,而kong只配置1个target。架构图如下图所示:
转存失败重新上传取消
场景二:
target配置具体IP地址及端口,因K8s pod 重启后变化或者服务实例增加,需要动态发现,因此需加入服务注中心并进行同步。负载此时使用kong实现,架构图如下图所示:
转存失败重新上传取消
15.8.3.7 负载均衡
同nginx一致,不详述。
15.9 Kubernetes CRD

Kube - Controller的内部大致实现逻辑:
主要使用到 Informer和workqueue两个核心组件。Controller可以有一个或多个informer来跟踪某一个resource。Informter跟API server保持通讯获取资源的最新状态并更新到本地的cache中,一旦跟踪的资源有变化,informer就会调用callback。
把关心的变更的Object放到workqueue里面。然后woker执行真正的业务逻辑,计算和比较workerqueue里items的当前状态和期望状态的差别,然后通过client-go向API server发送请求,直到驱动这个集群向用户要求的状态演化。
具体对client-go的使用,可参考《client-go的使用和源码分析》,在编写自定义的Controller的时候,需要大量使用client-go组件。上图中的蓝色部分全部是client-go已经包含的部分,不需要重新开发可以直接使用。红色的部分是自己的业务逻辑,需要自己开发。
可见基于CRD开发一个自定义的资源管理API 来扩展kubernetes的底层能力还是非常简洁的。比如在kubernetes中目前还是没有办法可以做到通过pod直接查询到对应的service是谁。
为了实现这个定制化的能力,为上层操作提供接口,就可以来扩展这个能力,写一个pod-service-controller。这个controller中提供两个informer,一个informer关注pod资源,一个informer关注service资源。
把各自的变化情况通过回调的方式放到workerqueue中。然后在worker中并发的去处理queue中的item。整理出pod和service的映射关系。这样上层就可以直接通过该controller的RESTful API 查询到他们之间的映射关系。而不需要在上层哐哐的写一堆业务处理。
https://www.geek-share.com/detail/2729147520.html
根据CRD的模板定义出自己的资源管理对象。比如crd.yaml文件
[code]apiVersion:apiextensions.k8s.io/v1beta1 kind:CustomResourceDefinition metadata: #名称必须符合下面的格式:<plural>.<group> name: foos.samplecontroller.k8s.io spec: # REST API使用的组名称:/apis/<group>/<version> group: samplecontroller.k8s.io # REST API使用的版本号:/apis/<group>/<version> version: v1alpha1 names: # CamelCased格式的单数类型。在清单文件中使用 kind: Foo # URL中使用的复数名称:/apis/<group>/<version>/<plural> plural: foos
[code] # Namespaced或Cluster scope: Namespaced validation: openAPIV3Schema: properties: spec: properties: replicas: type: integer minimum: 1 maximum:10
15.10 Kubernetes PV/PVC
https://kubernetes.io/docs/concepts/storage/persistent-volumes/
1.PV: 静态与动态区别
静态:普通为静态,需要手工为Pod创建
动态:使用storageclass配置,能动态根据用户需求调整
2.PVC:什么情况下使用静态或动态
集群管理员未创建任何静态PV,则会请求使用特殊storageclass(DefaultStorageClass)
3.如何启用默认storageclass
4. PVC vs PV and Pod vs node
PersistentVolume(PV)是对管理员用来管理集群中的存储资源的一种抽象,跟集群的节点资源类似。 PV是诸如卷之类的卷插件,具有生命周期管理,独立于使用PV的Pod. 该API对象包含了实现该存储的细节,存储的实现包含NFS, iSCSI和云提供商指定的存储系统。
PersistentVolumeClaim(PVC)是用户对于存储的请求。 它类似于pod。 Pod消耗节点资源,PVC消耗存储资源。 Pods可以所需特定级别的资源(CPU和内存)。PVC可以请求存储的容量大小和访问模式(例如RWO/ROX/RWX)
5.动态创建PC(storageclass)过程

1)集群管理员预先创建存储类(StorageClass);
2)用户创建使用存储类的持久化存储声明(PVC:PersistentVolumeClaim);
3)存储持久化声明通知系统,它需要一个持久化存储(PV: PersistentVolume);
4)系统读取存储类的信息;
5)系统基于存储类的信息,在后台自动创建PVC需要的PV;
6)用户创建一个使用PVC的Pod;
7)Pod中的应用通过PVC进行数据的持久化;
8)而PVC使用PV进行数据的最终持久化处理。
6.静态创建PV
7.查询集群中默认存储类
kubectl get storageclass
15.20 Kubernetes问题汇总
15.20.1 证书问题
The following error indicates a possible certificate mismatch.
[code]# kubectl get pods Unable to connect to the server: x509: certificate signed by unknown authority (possibly because of "crypto/rsa: verification error" while trying to verify candidate authority certificate "kubernetes") Verify that the $HOME/.kube/config file contains a valid certificate, and regenerate a certificate if necessary. The certificates in a kubeconfig file are base64 encoded. The base64 -d command can be used to decode the certificate and openssl x509 -text -noout can be used for viewing the certificate information. Another workaround is to overwrite the existing kubeconfig for the “admin” user:
[code] mv $HOME/.kube $HOME/.kube.bak sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
15.20.2 命名空间权限问题
问题:kubernetes无法进入pod
直接执行:
Kubectl exec -it <pod> /bin/bash(提示找不到相应pod)
在相应节点上执行:
Docker exec -it <container> /bin/bash(正常)
在kubernetes dashboard进入pod,提示的错误信息如下:

解决办法:
经上述分析,估计kubernetes权限存在问题,目前在命令行可以进入pod,但是需要指定命名空间:
[code]kubectl exec -i -t postgres-0 -n kong /bin/sh
rbac.yaml
Role及ClusterRole需要增加可以执行pods/exec权限
[code]- apiGroups: - "" //默认核心组 resources: - pods/exec verbs: - create - list - get
备注:通过Kubernetes-dashboard进入pods/exec出错,估计是通过kube-system命名空间在kong命令空间执行创建,所以应访是kube-sytem下的namespace-controller无权限问题。(暂未去解决)
15.20.2 命名空间访问
定义2个命名空间A、B
A无法直过Service服务发现访问B空间下的服务,反之同样。只在同一命名空间,集群内部才能过Service发现访问。

- kubernetes实战(二十):k8s一键部署高可用Prometheus并实现邮件告警
- Kubernetes用户指南(一)--快速开始、使用k8s配置文件
- 从零开始搭建Kubernetes集群(三、搭建K8S集群)
- Kubernetes(K8S)集群管理Docker容器(概念篇)
- China Azure中部署Kubernetes(K8S)集群
- kubernetes实战(十):k8s使用Helm安装harbor
- Linux下安装docker与kubernetes(k8s)
- 唯品会基于Kubernetes(k8s)网络方案演进
- Kubernetes(K8S)集群管理Docker容器(部署篇)
- Kubernetes1.91(K8s)安装部署过程(八)-- kubernetes-dashboard安装
- Docker入门之 - Kubernetes(k8s)
- 详解k8s组件Ingress边缘路由器并落地到微服务 - kubernetes
- kubernetes实战(十五):k8s使用helm持久化部署jenkins集成openLDAP登录
- kubernetes集群的学习——单节点k8s安装
- Kubernetes 实战教学,手把手教您用 Helm 在 K8s 平台上部署 Prometheus
- kubernetes学习第一篇-k8s安装以及HelloWorld
- k8s端口被占用:[ERROR FileAvailable--etc-kubernetes-manifests-kub、[ERROR Port-10250]: Port 10250 is in use
- 使用Kubernetes需要注意的一些问题(FAQ of k8s)