哈希表知识点小结
Set集合底层是基于HashMap的,再准备看Map源码集合前得有哈希表和红黑树相关的数据结构的知识。
对哈希表进行了温习,对知识点做出以下小结
1.为什么需要哈希表?Hash函数是干什么用的?
2. 哈希碰撞是什么?哈希碰撞的解决方法有哪些?
3.哈希表的优缺点是什么?
1.为什么需要哈希表?哈希表是什么?Hash函数是干什么用的?
无论是数组还是链表都对查询显得有些无力,要想知道某个元素是否在其中只有从头到尾进行对比查询,效率较低。出现这个问题的根源就是我们没办法直接根据一个元素找到它的存储位置。哈希表便应运而生了。
哈希表(散列表):是通过关键码值(Key)进行访问的一种数据结构。Key通过特定的哈希函数进行计算映射成一个int数值得到。
哈希函数就是用来计算得到特定的int型数值的规则,如数据结构所学到的除留余数法,直接定址法等

2.解决hash碰撞的方法有哪些?
我们知道int的值是有限的,它只有2^32^个,通过哈希函数计算后的所得到的int数值会有重复,此时会产生冲突,即哈希碰撞。解决方法有许多,如二维数组法,开放定址法,数组+链表法等
开放地址法:哈希表基本不会像数组一样每个位置都有元素,这样就可以将碰撞的元素插入到这些空闲的位置中区,这种方案称为定址法。有一次线性探测,二次线性探测,这都是数据结构考过的内容,但其可扩展性不佳,且JDK源代码中也不是使用这种方法解决
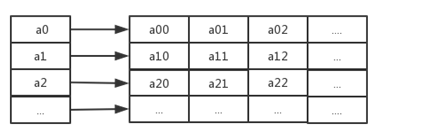
二维数组法:即将碰撞的元素按照顺序依次存储起来,但最大的缺点是数组的大小是固定的,所以第二维的数组长度都是一样的,但是哈希碰撞一定是比较少发生的情况,也就是我们声明了一个很大的数组,但是其中大部分都是闲置的,这就浪费了大量的内存。如下图所示
拉链法:目前比较通用的一种方式,数组+链表组合的方式。这是当前比较理想的方法,既继承了数组的优点,又在碰撞时继承了链表的优点,这也是哈希表强大的地方之一。当出现哈希碰撞时,在该位置的数据就通过链表的方式链接起来,如下图所示:
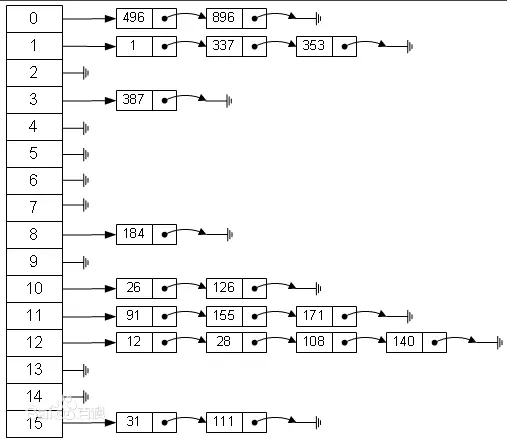
在JDK1.7及之前的版本中,HashMap的存储结构和上图是一致的,在JDK1.8之后还加入了红黑树以进一步优化,之后将对树,二叉树,红黑树进行整理。
2.哈希碰撞的优缺点
哈希表是一种优化存储的思想,具体存储元素的依然是其他的数据结构。设计良好的哈希表,能同时兼备数组和链表的优点,它能在插入和查找时都具备良好的性能。然而设计不好的哈希表,有可能会出现较多的哈希碰撞,导致链表过长,从而哈希表会更像一个链表。还有当数据量很大时,为防止链表过长,就需要对数组进行扩容,这时就涉及到了数组的拷贝,其对性能的影响也很严重,所以需要提前对可能的情况有良好的预测,才能真正发挥哈希表的优势。
PS:以上皆为纯理论的知识点,具体的实现代码需要结合搜索引擎加以练习。后面两天会去做这方面练习。

- (萌O(∩_∩)O)哈希知识点小结
- Swift语言知识点小结类和对象
- IOS开发,知识点小结,ios开发中常用的宏定义总结
- JavaScript知识点之“面向对象小结”
- Java基础知识点之函数和流程控制语句小结
- C++枚举体知识点小结
- SpringMVC知识点小结
- C++ 继承与接口 知识点 小结(二)
- 2013-05-10 小结 Android的一些知识点
- 程序员常见面试之 数据库 知识点小结(三)
- shell知识点小结
- 防火墙知识点小结
- 【技术小结1】实习40多天所接触的.NET知识点与心得
- java 知识点 小结
- selenium知识点小结
- Android Notification 知识点自我小结
- spring boot之session知识点小结
- 关于const的一些知识点小结
- [Stanford 2011] 知识点小结
- oracle知识点小结1