Shell编程——基础正则表达式
2019-07-11 11:50
936 查看
Shell编程:
- 基础正则表达式
- 字符截取命令
- 字符处理命令
- 条件判断
- 流程控制
基础正则表达式
1、正则表达式与通配符:
- 正则表达式用来在文件中匹配符合条件的字符串,正则是包含匹配。grep、awk、sed等命令可以支持正则表达式。
- 通配符用来匹配匹配符合条件的文件名,通配符是完全匹配。ls、find、cp这些匹配文件名的命令不支持正则表达式,所以只能使用shell自己的通配符来进行匹配了。通配符就这几个符号:*、?和[ ]
- 正则表达式是用来在文件中搜索符合条件的字符串;而通配符是用来在系统当中搜索符合条件的文件名。这个区别仅限如Linux和Shell脚本中,其他语言中可能不区分。
- **包含匹配:**用正则表达式时,也就是说用grep、awk、sed命令时,你搜索的内容只要包含在这个文件行当中,它就会提取出这一行,因此称为包含匹配。**完全匹配:**通配符必须和它一模一样才可以匹配。
包含匹配和完全匹配,示例说明:
- 完全匹配
[root@root ~]# touch aa [root@root ~]# touch aabb [root@root ~]# ls aa #完全匹配 aa [root@root ~]# ls aa* aa aabb
- 包含匹配
[root@root ~]# vi ./anaconda-ks.cfg [root@root ~]# grep "size" anaconda-ks.cfg #part /boot --fstype=ext4 --size=1000 #part / --fstype=ext4 --size=20000 #part /home --fstype=ext4 --size=10000 #part /opt --fstype=ext4 --size=5000 #part swap --size=4096
2、基础正则表达式
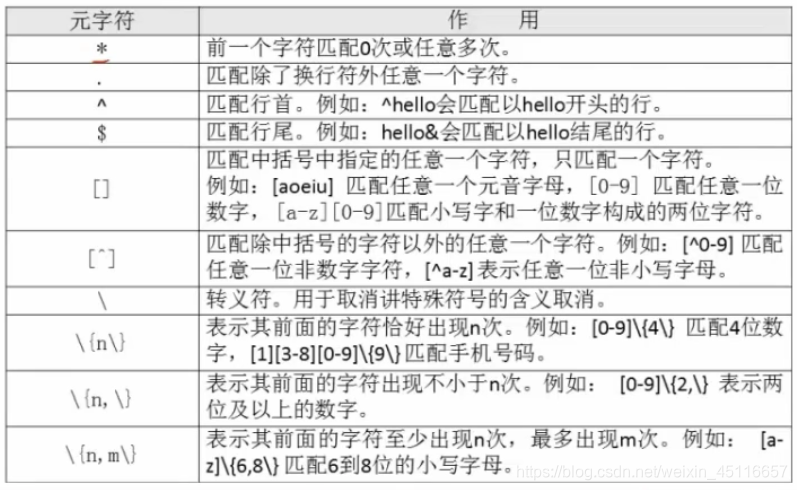 练习测试文件如下:
练习测试文件如下:
[root@root ~]# vim test_rule.txt Mr.Li Ming said: he was the honest man in LampBrother. 123despise him. But since Mr.Shen Chao came, he never saaaid those words. because,actuaaaally, Mr.Shen Chao is the most honest man! Later,Mr.Li ming soid his hot body.
在这里插入代码片(1) “ * ” 前一个字符匹配0次,或任意多次;
- grep “a*” test_rule.txt
#匹配所有内容,包括空白行。即表示前面这个a相当于没有。匹配零次相当于任意行都可以的,所以相当于列出整个文档。因此,这种写法在正则中是没有任何意义的 - grep “aa*” test_rule.txt
#匹配至少包含有一个a的行 - grep “aaa*” test_rule.txt
#匹配至少包含两个连续a的字符串 - grep “aaaaa*” test_rule.txt
#匹配至少包含四个连续a的字符串
示例如下:
[root@root ~]# grep "a*" test_rule.txt Mr.Li Ming said: he was the honest man in LampBrother. 123despise him. But since Mr.Shen Chao came, he never saaaid those words. because,actuaaaally, Mr.Shen Chao is the most honest man Later,Mr.Li ming soid his hot body. [root@root ~]# grep "aaaaa*" test_rule.txt because,actuaaaally, You have mail in /var/spool/mail/root(2)“ . ” 匹配出来换行符外任意一个字符(相当于通配符当中的问号)
- grep “s..d” test_rule.txt
#s..d" 会匹配在 s 和 d 这两个字母之间一定有两个字符的单词 - grep “s.*d” test_rule.txt
#匹配在s和d字母之间有任意字符 - grep " . " test_rule.txt
#匹配所有内容
正则表达式是包含匹配,如果这个规则写的越仔细,它所匹配的范围就越小;
示例如下:
[root@root ~]# grep "s..d" test_rule.txt Mr.Li Ming said: Later,Mr.Li ming soid his hot body. [root@root ~]# grep "s.*d" test_rule.txt Mr.Li Ming said: he never saaaid those words. Later,Mr.Li ming soid his hot body.(3)“ ^ ” 匹配行首,“ $ ” 匹配行尾
- grep “^M” test_rule.txt
#匹配以大写 “M” 开头的行 - grep “n$” test_rule.txt
#匹配以小写 “n” 结尾的行 - grep -n “^$” test_rule.txt
#会匹配空白行
示例如下:
[root@root ~]# grep "^M" test_rule.txt Mr.Li Ming said: Mr.Shen Chao is the most honest man! [root@root ~]# grep "^$" test_rule.txt 4: 7: 10: [root@root ~]#(4)“ [] ” 匹配中括号中指定的任意一个字符,只匹配一个字符
- grep “s[ao]id” test_rule.txt
#匹配 s 和 i 子母中,要么a,要么b - grep “[0-9]” test_rule.txt
#匹配任意一个数字 - grep “^[0-9]” test_rule.txt
#匹配用小写字母开头的行 - grep “^[^0-9]” test_rule.txt
#匹配以非数字开头的行。[ ]中括号里面加“ ^ ”是取反的意思。
示例如下:
[root@root ~]# grep -n "s[ao]id" test_rule.txt 1:Mr.Li Ming said: 11:Later,Mr.Li ming soid his hot body. [root@root ~]# grep -n "^[0-9]" test_rule.txt 3:123despise him. [root@root ~]# grep -n "^[^0-9]" test_rule.txt 1:Mr.Li Ming said: 2:he was the honest man in LampBrother. 5:But since Mr.Shen Chao came, 6:he never saaaid those words. 8:because,actuaaaally, 9:Mr.Shen Chao is the most honest man! 11:Later,Mr.Li ming soid his hot body.(5)“ [^] ” 匹配出中括号内字符以外的任意一个字符
- grep “^[^a-z]” test_rule.txt
#匹配不用小写字母开头的行 - grep “^[^a-zA-Z]” test_rule.txt
#匹配不用字母开头的行
- grep “.$” test_rule.txt
#*匹配使用 “ . ” 结尾的行。空白行没有字符,所以没有列出来的。 *
示例如下:
[root@root ~]# grep "\.$" test_rule.txt he was the honest man in LampBrother. 123despise him. he never saaaid those words. Later,Mr.Li ming soid his hot body.(7)“ \{n\} ” 表示前面的字符恰好出现n次
- grep “a\{3\}” test_rule.txt
#匹配 a 字母连续出现三次的字符串 - grep “[0-9]\{3\}” test_rule.txt
#匹配包含连续的三个数字的字符串
示例如下:
[root@root ~]# grep "a\{3\}" test_rule.txt
he never saaaid those words.
because,actuaaaally,
[root@root ~]# grep "[0-9]\{3\}" test_rule.txt
123despise him.
(8)“ \{n,\} ” 表示其前面的字符出现不小于n次
- grep “^[0-9]\{3,\}[a-z]” test_rule.txt
#匹配最少用于连续三个数字开头的行。其实这个正则和前面grep “[0-9]\{3\}” test_rule.txt用法是一样的。
示例如下:
[root@root ~]# grep "[0-9]\{3,\}" test_rule.txt
123despise him.
(9)"\{n,m\}" 匹配器前面的字符至少出现n次。最多出现m次
- grep “sa\{1,3\}i” test_rule.txt
#匹配在字母 s 和字母 i 之间有最少一个a,最多三个a
示例如下:
[root@root ~]# grep "sa\{1,3\}" test_rule.txt
Mr.Li Ming said:
he never saaaid those words.

相关文章推荐
- 编程语言和shell编程的基础内容以及grep、egrep命令及相应的正则表达式和用法
- Linux下Shell编程——正则表达式基础与扩展
- 编程语言和shell编程的基础内容以及grep、egrep命令及相应的正则表达式和用法
- Linux下Shell编程——正则表达式基础与扩展
- *Shell编程基础教程5--文本过滤、正则表达式、相关命令
- shell编程基础【六】---正则表达式
- shell编程之正则表达式基础
- shell编程之正则表达式基础
- Shell编程——正则表达式基础与扩展
- [ SHELL编程 ] 通配符与基础正则表达式、扩展正则表达式
- shell编程——正则表达式的基础
- C#正则表达式基础 {3,5} 检测字符串是否存在 3到5个连续的数字
- 正则表达式基础知识
- java基础--正则表达式
- 正则表达式基础知识
- 正则表达式基础
- 正则表达式基础
- 正则表达式的基础知识点
- Java基础---正则表达式
- 正则表达式基础知识