车道线检测Spatial As Deep: Spatial CNN for Traffic Scene Understanding(论文解读)
2019-07-07 14:49
661 查看
版权声明:本文为博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/sinat_24674017/article/details/94988436
论文链接
https://arxiv.org/pdf/1712.06080.pdf
动机
- 当前基于CNN的语义分割对于图片中处于同一行或同一列的像素关系仍然有待进一步深入探索。这种像素关系的挖掘对于分割多个具有先验性的固定形状但是各个形状之间没有太大耦合性的目标是非常重要的。而车道线就是这一类目标。而目前的语义分割算法对于长条状区域和遮挡区域的分割效果不佳。
- 在传统的基于马尔可夫随机场或者条件随机场的算法中,每个像素从其周围的像素中获得特征信息,流程如Figure 3(a)所示。这类传统方法计算开销大,难以在部署时实现实时检测。
- 当前的车道线检测数据集数据量过小过于简单,场景种类少。

贡献
- 为了使分割算法对于长条状区域和遮挡区域的分割有更好的效果,本文提出了一个Spatial CNN,使用切片卷积的方式提高对结构化的目标的分割效果,同时也减少计算开销,提高检测速度。
- 论文作者自己制作了一个北京交通场景的数据集cuLane,该数据集包含了乡村,城市,高速公路等场景,数据量是TuSimple数据集的20倍。考虑到当车道线被遮挡时,仍然希望检测算法能够根据上下文把遮挡部分也检测出来,所以在标注车道线标签时,被遮挡的部分也被标注出来。
算法

- 输入:RGB图片
- 检测过程:
1)使用普通卷积层和分片卷积层混合的结构。如Figure 3(b)所示,使用CNN提取图片特征后,使用一种切片卷积方式进行进一步特征提取。把feature map的高度H方向的切片或者宽度W方向的切片视作卷积层的输入进行逐片的卷积,并将上一片的卷积结果以element wise的方式加到下一片继续进行卷积。卷积核的大小为Cxw,w为设置的卷积核宽度。对每片都进行卷积后,再把每一片都堆叠为原来形状的feature map,输入下一个网络层。
2)这种切片卷积的卷积方向也是可以改变的,当在H方向进行切片时,既可以朝上进行逐片卷积,也可以朝下进行逐片卷积,当在W方向进行切片时,既可以朝左进行逐片卷积,也可以朝右进行逐片卷积。
3)预测得到对车道线进行实例分割的prob map后,将prob map输入一个小网络,实现对多条车道线是否存在的二分类预测。 - 输出:一个对车道线的实例分割的prob map以及一个对每条车道线存在与否的二值预测结果。对两者进行综合后处理,对于二分类预测中存在概率大于0.5的车道线,在prob map上每隔20行找到一个车道线prob最大的位置,连接这些点,可以得到最终的车道线定位。
- 损失函数:实例分割probmap的预测:cross entropy loss,车道线是否存在的二分类预测:cross entropy loss
实验
数据集
自制cuLane数据集,TuSimple数据集(由于在CityScapes数据集上的实验主要是语义分割,与车道线检测无关,所以不做展述)
评价指标
cuLane数据集:把车道线看作30个像素宽的长条状目标,通过计算预测车道线和gt车道线的IoU判断是否为True Positive。如果IoU大于某个threshold,则认定为True Positive。然后计算Precison和Recall,再计算F1-score。
TuSimple数据集:pixel accuracy
结果
TuSimple测试集:实现96.53%的准确率
CuLane数据集:
- SCNN中多方向切片卷积的影响。实验表明,添加更多不同方向切片卷积能够提升效果。

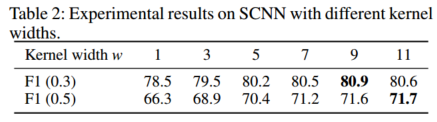
- 切片卷积核宽度w的影响。
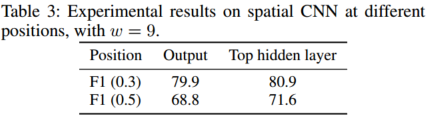
- 在不同位置进行切片卷积的影响。在Top hidden layer后进行切片卷积效果更好,因为top hidden layer的输出包含了更丰富的特征信息
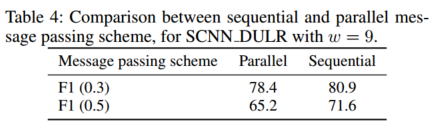
- 按序前向传播的影响。
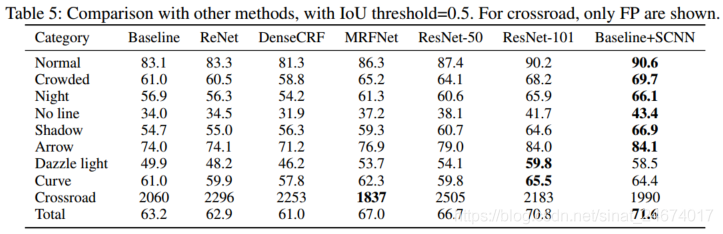
- 各个方法结果对比
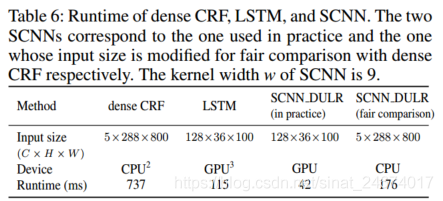
- 计算效率比较。Runtime不包括backbone的运行时间
优缺点
优点:
- 制作了一个规模更大,场景更加丰富的车道线检测数据集,并考虑到了遮挡物体的检测
- 使用SCNN_DULR实现了比其他方法更好的车道线检测效果
缺点:
- 从Table 6可以看出光是一个SCNN_DULR模块就要42ms,虽然速度比CRF要快很多,但是要实现真正的实时检测还是比较困难
- 在对车道线存在与否的二分类预测中,应该也把可预测车道线的数量定死,在车道线变化的场景中可能不适用
反思
- 对于速度无法达到实时的问题,是否可以通过移植到其他深度学习框架实现算法加速?甚至可以使用tensorRT推理引擎?

相关文章推荐
- SCNN车道线检测--(SCNN)Spatial As Deep: Spatial CNN for Traffic Scene Understanding(论文解读)
- SCNN车道线检测--(SCNN)Spatial As Deep: Spatial CNN for Traffic Scene Understanding(论文解读)
- Spatial As Deep: Spatial CNN for Traffic Scene Understanding论文翻译
- 车道线检测Enhanced free space detection in multiple lanes based on single CNN with scene identification解读
- 《A Lightened CNN for Deep Face Representation》论文解读 本文来自中科院,原文地址为: https://arxiv.org/abs/1511.02683
- 论文阅读-《BlitzNet: A Real-Time Deep Network for Scene Understanding》
- 目标检测分割--BlitzNet: A Real-Time Deep Network for Scene Understanding
- Colorization as a Proxy Task for Visual Understanding论文解读
- 【论文阅读笔记】Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- 深度学习论文随记(二)---VGGNet模型解读-2014年(Very Deep Convolutional Networks for Large-Scale Image Recognition)
- 【论文笔记】 R2CNN: Rotational Region CNN for Orientation Robust Scene Text Detection
- DeepID2+:Deeply Learned Attributes for Crowded Scene Understanding
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 论文笔记
- Joint Deep Learning For Pedestrian Detection(论文笔记-深度学习:行人检测)
- 【转】R-CNN学习笔记3:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPP-net)
- [深度学习论文笔记][Scene Classification] Learning Deep Features for Scene Recognition using Places Database
- 论文学习-深度学习目标检测2014至201901综述-Deep Learning for Generic Object Detection A Survey
- SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- MSCNN论文解读-A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
- [论文解读] MSCNN: A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection