如何从 0 到 1 设计、构建移动分析架构
作者:处厚,目前主要负责支付宝数据分析组件开发和通过移动开发平台 mPaaS 对外输出工作。本专题主要围绕 mPaaS 移动分析服务 MAS 展开分享如何从 0 到 1 设计、构建移动分析架构。
直播回顾地址(请复制到浏览器中打开):t.cn/EoVbajX
0. 移动分析的过去与未来
移动分析,这个名字其实不够全面,本质上是“移动数据分析”。因此我们接下来讨论的具体业务问题虽然仍在数据统计分析的范畴,但由于移动端应用的蓬勃发展,因此我们将具体业务与 BI、数据仓库等技术深度结合,并逐步推演沉淀了移动分析架构设计的思考。
移动数据分析在发展初期和现阶段的情况已经是完全不同:
- 发展初期:从业务层面看,App 处于蓝海市场时获客容易,因此研发团队有条件更关注业务发展,专注开发好用的 App 来吸引客户;从技术层面看,BI/数据仓库技术曲高和寡,仍旧运行在大型企业中,如运营商、能源机构等。同时,开源数据平台还处在初级阶段。
- 现阶段:经过了多年的高速发展,移动数据分析已经进入了成熟期,App 厂商需要应对严厉的市场竞争才能存活。因此业务团队一方面需要更加熟悉 App 运营状况,精细化运营客户,另一方面,Hadoop 作为基础的大数据平台产品已经相对成熟,不仅方便于数据开发,对于自建大数据平台而言也非常适配。 而市面上众多提供数据分析服务的公司能够坚持到现在,也足以说明相关能力确实在解决移动开发者的相应痛点:
1、App 已经下发,那么 App 的运行情况实际如何?
2、用户的数量及以后的增长趋势如何评估
3、App 中的哪些功能是实际上受用户喜爱和欢迎的?
4、用户画像(用户所在区域、用户使用设备的价位、用户使用 App 的频次)
这些问题,如果解决起来,和线上耦合性较小。但是直接使用线上的数据库来做则是非常困难,而且消耗很大,这就需要使用数据仓库技术,来处理移动数据,形成指标报表,从而深度支持业务方完成运营决策,更精准地展开用户运营;或者形成 AI 算法,提供新的用户服务。
那么,我们今天探讨一下,如何从 0 到 1 设计、构建一个移动分析平台。
1. 移动分析架构简析
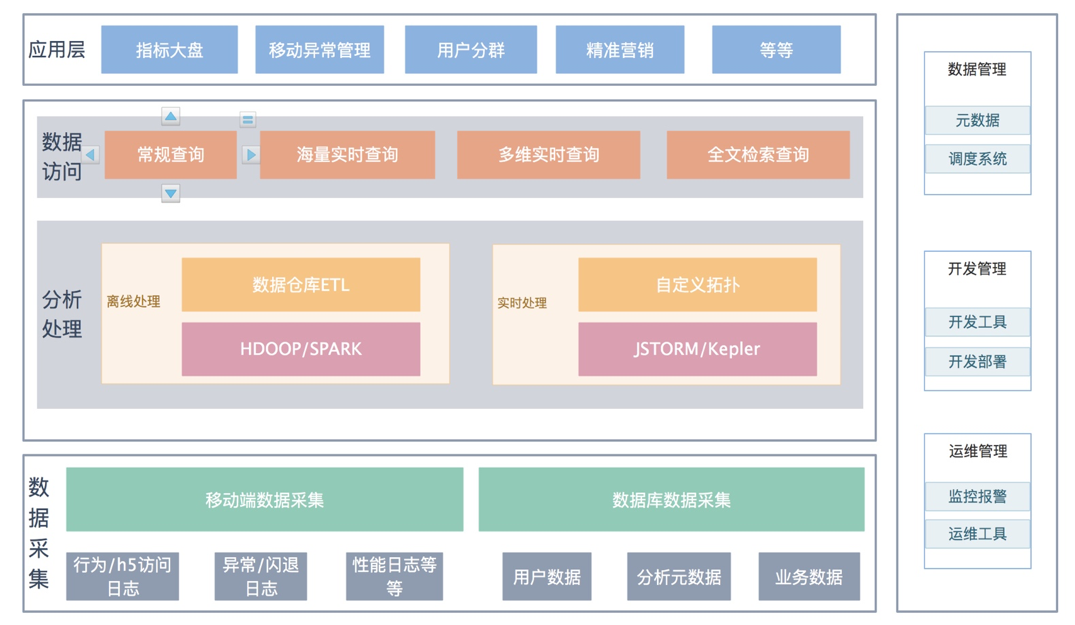
大数据平台架构的层次划分没啥标准,主要是由于应用的分类横纵交错,因此基于大部分数据平台架构的共性基础上,我们总结归纳了一些思路,方便大家理解和应用到实际业务中。首先,我们将大数据平台架构划分为“四横一纵”:
- 四横:数据采集、数据处理/分析、数据访问 应用
- 一纵:管控体系
开发管理,数据管理, 运维管理等等属于数据管理体系中非常重要的部分,目标是逐步完善四层架构体系,并将移动数据分析处理体系这样的来复枪变成机关枪,强大而快速。
2. 移动分析架构详解
【数据采集】
数据采集部分,我们可以将具体工作分为两块:
- 日志采集接口:接受移动端上报数据,并将接受的日志落盘。这个模块一般需要自己开发。
- 采集传输工具:监听日志文件,将落盘的问题读出,发送至需要的数据存储端,例如 HDFS, Kafka 等。这个模块一般可以采用开源或者商业的组件:Apache Flume, Elastic Logstash,Aliyun Logtail 等等。
两者虽然可以合在一起,但是一般都是分开来,分开管理的好处是显而易见的:灵活,高并发,吞吐量兼顾。
除了采集 App 数据之外,针对数据库数据的采集,一般选用 Hadoop 大数据套件中专门用来采集关系型数据库的 Sqoop。对于关系型数据库的 mySQL,MariaDDB,Oracle,SQLServer 等都可以使用它来进行数据采集,快速健壮。当然除了 Sqoop 之外,Datax,kettle 甚至 Hive 都可以作为选型考虑。
基于 mPaaS 移动分析服务 MAS 产品本身日志类型较简单,同时产品使用需要兼顾速度以及灵活支持后端数据通道和存储,我们最终使用了 Apache Flume 以及 Hive 作为选型组合。
【数据处理、分析】
根据数据处理场景要求不同,可以划分为离线、实时流处理、即席查询等等。
在这个部分,可能也是要分两个部分:基础组件和业务流程。基础组件有较大共性,而业务流程因为不同的业务团队而差异较大,从而有不同的设计和实践方案,因此不能一概而论。接下来我们围绕 mPaaS 的数据计算流程进行简单解析:
- 离线部分
离线是数据计算的基石,也是最早发展起来的。Hadoop/Hive/Spark 现在基本成为现在开源离线数据处理的标配。基于 Hive/Spark 构建分布式数据仓库,可以支持相对复杂的数据集分析场景,擅长海量的数据分析计算,但是运行时间来说相对较长。因此对计算时间不敏感的数据可以通过这种方式来进行处理,一般情况下的第二天凌晨开始计算,能够完成前一天业务数据的计算并导出。
基于 Hive/Spark,我们可以使用 SQL 非常灵活地开发 ETL 任务,对数据完成清洗,转换与加载。在做离线开发时,由于比较强调逻辑模型和分层设计,因此我们普遍用数仓的知识来指导开发。
一般而言,我们会使用纬度建模,也叫星型模型。为了分析方便,商业纬度往往会被分成不同层次,并融合到数据模型中。对应的,分层设计中我们主要分为接入层,汇总层和应用层。
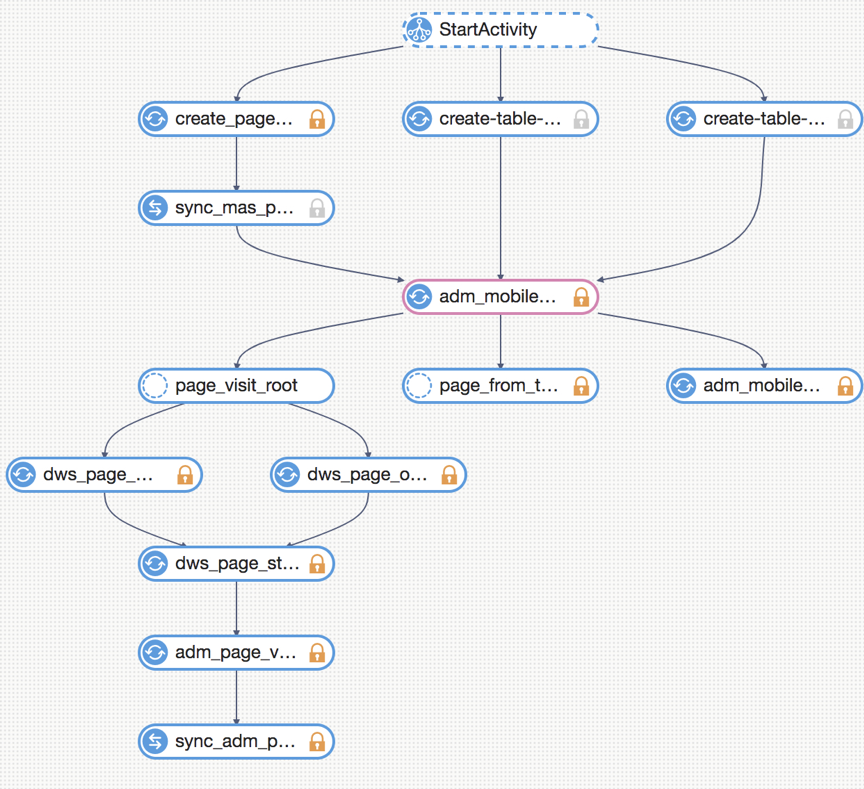
[图为页面访问接口数据处理过程]
以 mPaaS MAS 的离线为例,ETL 中接入事实表,从数据库同步的 10 张维度表为接入层,对数据汇总后,形成了庞大的中间层,最后形成了面向设备分析、留存分析、页面分析、漏斗分析等应用层。
- 实时流计算
离线计算只能提供 N 个小时之前的数据计算结果,这对业务方而言,效率实在太低。在相当多的业务场景下,比如淘宝的双十一大促大盘,当前的计算结果需要被实时获取,从而时刻更新消费总额。因此,实时流计算便延伸出来,Spark Streaming、Storm(triden)/JStorm/Flink 是目前最常见的几种实时流计算技术,他们分别在吞吐量以及准确性上各善其场。
目前,mPaaS MAS 使用 JStorm/Kepler 技术,其中 JStorm 是一个分布式实时计算引擎,类似 Hadoop MapReduce。用户按照规定的编程规范实现一个任务,将任务提交到 JStorm 上,JStorm 即可将任务 7*24 小时调度起来。核心原理如下图:

JStorm 提交运行的程序称为 Topology。Topology 处理的最小的消息单位是一个Tuple,也就是一个任意对象的数组。Topology 由 Spout 和 Bolt 构成。Spout 是发出 Tuple 的结点。Bolt 可以随意订阅某个 Spout 或者Bolt 发出的 Tuple。Spout 和 Bolt 都统称为 Component。
- 即席查询
对大量数据进行多维分析的情况下,传统的 SQL 数据库是远远不能满足需要的。ES/Druid 等提供了高效的索引,在分布式的情况下,支持亿级数据量以及秒级多维查询。目前在众多商业公司中得到的极广的应用与落地。
蚂蚁金服在 Druid 基础上,开发了 Explorer 从而更加完善地支持 SQL 与 mysql-jdbc-driver。Druid 列式设计可最大限度地减少 I/O 争用,后者是导致分析处理发生延迟的主要原因。列式设计还可提供极高的压缩率,那么可有效将其性能提高一倍。
Druid 协议层提供 MySQL 协议的接口,通过 mysql-jdbc-driver,可以向 Explorer 发起 insert,select 请求;而计算层基于 Drill,支持多种类型的存储,集群线性扩展,执行计划可定制;存储层则基于 Druid,拥有针对 OLAP 特有的存储格式和计算能力。Explorer 整体架构如下图:
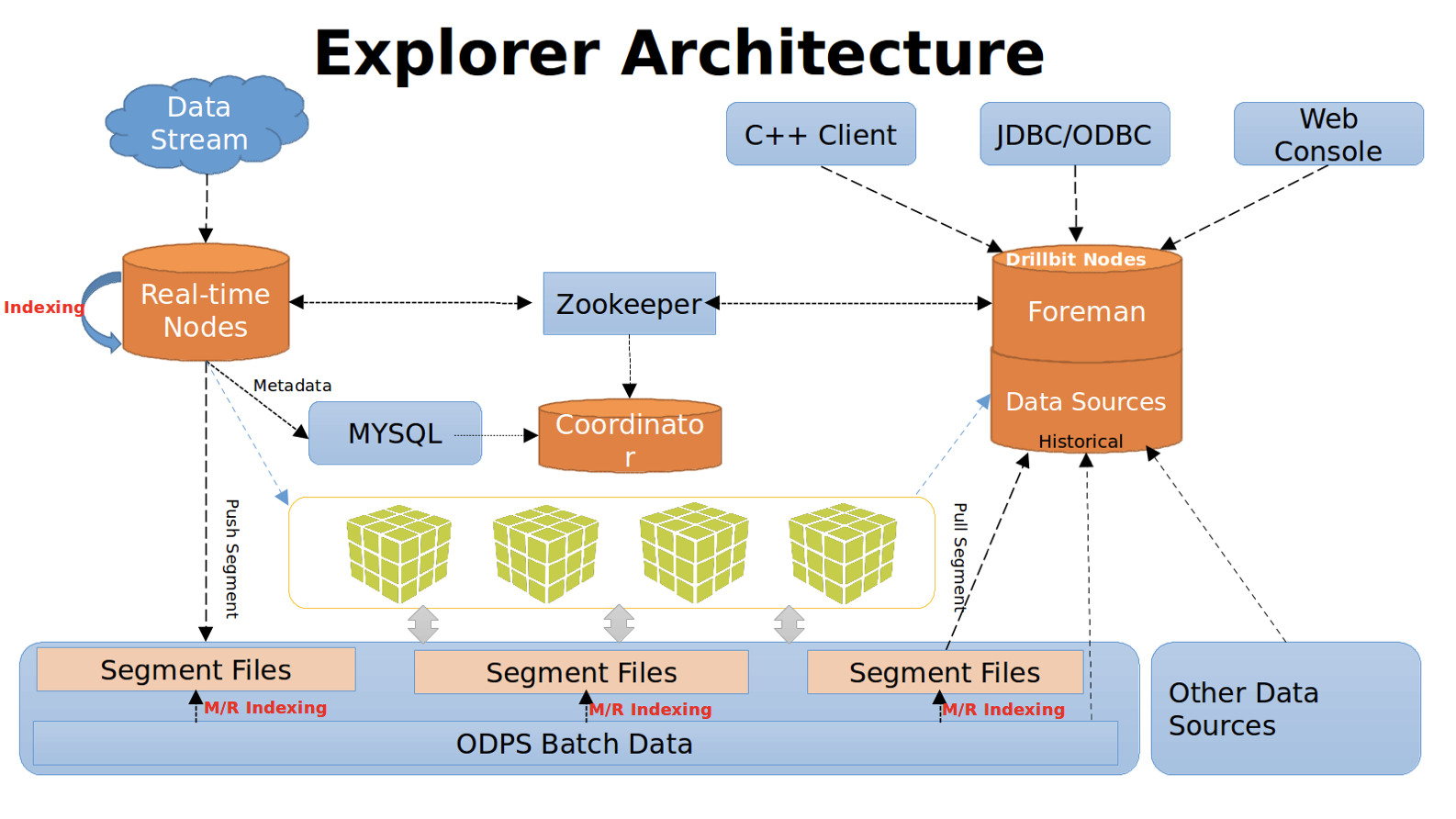
对于 MAS 自定义分析中,因无法预先确定用户自定义聚合规则,以及属性维度,因此选择了 Explorer,并利用其强大的预聚合能力来支撑。在 Kepler/JStorm 实时计算拓扑中,仅需根据用户自定义的属性维度,切分后实时插入 Explorer 即可完成聚合。
- 数据访问
通过数据平台对于数据处理和分析之后,产出了大量的数据指标等内容,放在 HDFS 上,可以通过 Hive/Sqoop 等技术,将数据从 HDFS 中,回流到在线系统中,提供高速访问。
Hbase/OTS 等列式存储引擎提供了大容量,高性能,高可用的能力,查询速度在毫秒级,对于百亿级别的查询也是可以支持,同时具备了一定的高可用性。限制的部分仅仅需要通过 rowkey 或者 rowkey 的前缀进行范围查询。
MySQL 等数据库,针对数据量小的统计结果,可以存放到 SQL 数据库中,对于查询等操作同样非常方便。
在上一个小节,我们已经介绍过 ES/Druid 等即席查询数据库。它们对于多维分析可以提供极其有效的帮助。对于一些数据精细化分析的业务场景,通过数据漏斗等方式可以先删掉大量无效数据,结合自定义的多维分析,能够有效提升分析的效率和质量。
3. 应用
- 指标
经过以上各个阶段,我们已经完成了业务数据的各项计算,得到了针对 App 的版本,渠道、iOS/Android 平台、业务纬度等聚合的计算结果,从而获取到针对“新增、累计用户、设备、渠道”等各项分类数据。
- 日志管理
围绕日志管理功能,我们需要再提到 ES 工具。基于 ES 的全文索引能力,其可以提供非常强大的日志查询回放能力。对于定位错误,辅助开发都有非常好的作用。
- 异常管理
移动端因为离开发者较远,因此无法像 server 端可以快速的看到错误。因此,针对移动端所面临的闪退、卡顿卡死等现象进行日志采集,有助于更好地优化产品体验,同时支持应用快速发版,也是现在敏捷开发的重要保证和支持。
- 管控体系
有了离线计算,实时流式计算以及应用积累的业务数据,管控平台的建设需要提上日程。它的作用就是催化上述分析能力以及相关数据,从而帮助业务方持续不断地优化分析方式来使用数据,将步枪升级为冲锋枪。
对于离线、实时计算的开发管理、数据管理、运维管理等模块,一般都是集成在数据平台这个层次上。开源系统也提供了 Hive Web Interface 等工具,但是功能还比较弱。
调度系统 Oozie azkaban Zeus 离线 SQL 开发 Hue Zepplin 元数据管理 Hive 实时需要自行开发
mPaaS 移动分析服务 MAS
mPaaS,即mobile PaaS,简单来说它是源于支付宝技术的一个移动开发平台,包含了移动开发、测试、发布、分析、运营各个方面的云到端的一体化的解决方案。
移动分析服务 MAS 在 mPaaS 产品体系中,定位是支持移动端应用进行数据采集和分析,帮助业务方展开精细化、智能化运营,同时结合应用日志采集与分析等功能从而帮助开发团队更快、更精确地找到问题并快速修复。此外,移动分析能力在蚂蚁金服内部经历了双 11、双 12 等高并发大促业务的挑战和锤炼。
目前,mPaaS 移动分析服务 MAS 已经在支付宝香港版、印度 Paytm、印尼 Dana、上海地铁、华夏银行等多个项目中完成能力输出和落地应用。欢迎阅读 移动分析服务 MAS 技术文档,进一步了解更多产品功能和优势介绍。

- 手机设计指南(一):如何理解移动信息架构?
- PLUTO平台是由美林数据技术股份有限公司下属西安交大美林数据挖掘研究中心自主研发的一款基于云计算技术架构的数据挖掘产品,产品设计严格遵循国际数据挖掘标准CRISP-DM(跨行业数据挖掘过程标准),具备完备的数据准备、模型构建、模型评估、模型管理、海量数据处理和高纬数据可视化分析能力。
- 如何构建一个ERP系统(需求分析、系统架构、系统设计、系统编码、测试、交付程序及文文件)。
- PLUTO平台是由美林数据技术股份有限公司下属西安交大美林数据挖掘研究中心自主研发的一款基于云计算技术架构的数据挖掘产品,产品设计严格遵循国际数据挖掘标准CRISP-DM(跨行业数据挖掘过程标准),具备完备的数据准备、模型构建、模型评估、模型管理、海量数据处理和高纬数据可视化分析能力。
- 为移动而设计, 如何理解移动信息架构?(一)
- 如何评估A段架构设计呢? 微软也常使用AHP分析
- 如何评估A段架构设计呢? 微软也常使用AHP分析
- 敏捷开发下, 如何将需求分析,架构(软件)设计,开发与测试,一气呵成式的结合且高效的完成 ?
- 如何构建千万用户级别 后台数据库架构设计的思路
- 如何在Visual Studio 2017中使用C# 7+语法 构建NetCore应用框架之实战篇(二):BitAdminCore框架定位及架构 构建NetCore应用框架之实战篇系列 构建NetCore应用框架之实战篇(一):什么是框架,如何设计一个框架 NetCore入门篇:(十二)在IIS中部署Net Core程序
- 网狐棋牌游戏平台服务器架构设计分析
- TYPESDK手游聚合SDK客户端设计思路与架构之一:设计需求分析
- 79-Spark Standalone架构设计要点分析
- 服务器架构设计,常见问题分析
- Tomcat 系统架构与设计模式,第 2 部分: 设计模式分析
- 如何实现稳定的千万级PV移动应用架构
- PHP实例学习之————MVC架构模式分析与设计
- 移动优先的设计常识:应用如何组织?
- 面向AARRR 的 移动架构设计 思考备忘
- 5个层次分析:产品设计中的“借鉴”思想如何运用?