Scrapy 伪分布式爬虫
2019-06-03 21:56
316 查看
Scrapy 伪分布式爬虫
应用 Scrapy框架 ,使用redis实现伪分布式爬虫。
# settings 配置redis SCHEDULER = "scrapy_redis.scheduler.Scheduler" DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" SCHEDULER_PERSIST = True
# spider 引入并配置redis
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from proxy.items import ProxyItem
from scrapy_redis.spiders import RedisCrawlSpider
class XiciSpider(RedisCrawlSpider):
name = 'xici'
redis_key = 'myspider:start_urls'
def parse_start_url(self, response):
print(response)
rules = (
Rule(LinkExtractor(allow=r'/nt/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
print(response.url)
item = ProxyItem()
list = response.xpath('//table[@id="ip_list"]/tr')
for listItem in list:
item['country'] = listItem.xpath('.//td[1]/img/@alt').get()
item['ipAddress'] = listItem.xpath('.//td[2]/text()').get()
item['port'] = listItem.xpath('.//td[3]/text()').get()
item['serverAddress'] = listItem.xpath('.//td[4]/a/text()').get()
item['type'] = str(listItem.xpath('.//td[6]/text()').get()).lower()
item['timeToLive'] = listItem.xpath('.//td[9]/text()').get()
item['proofTime'] = listItem.xpath('.//td[10]/text()').get()
yield item
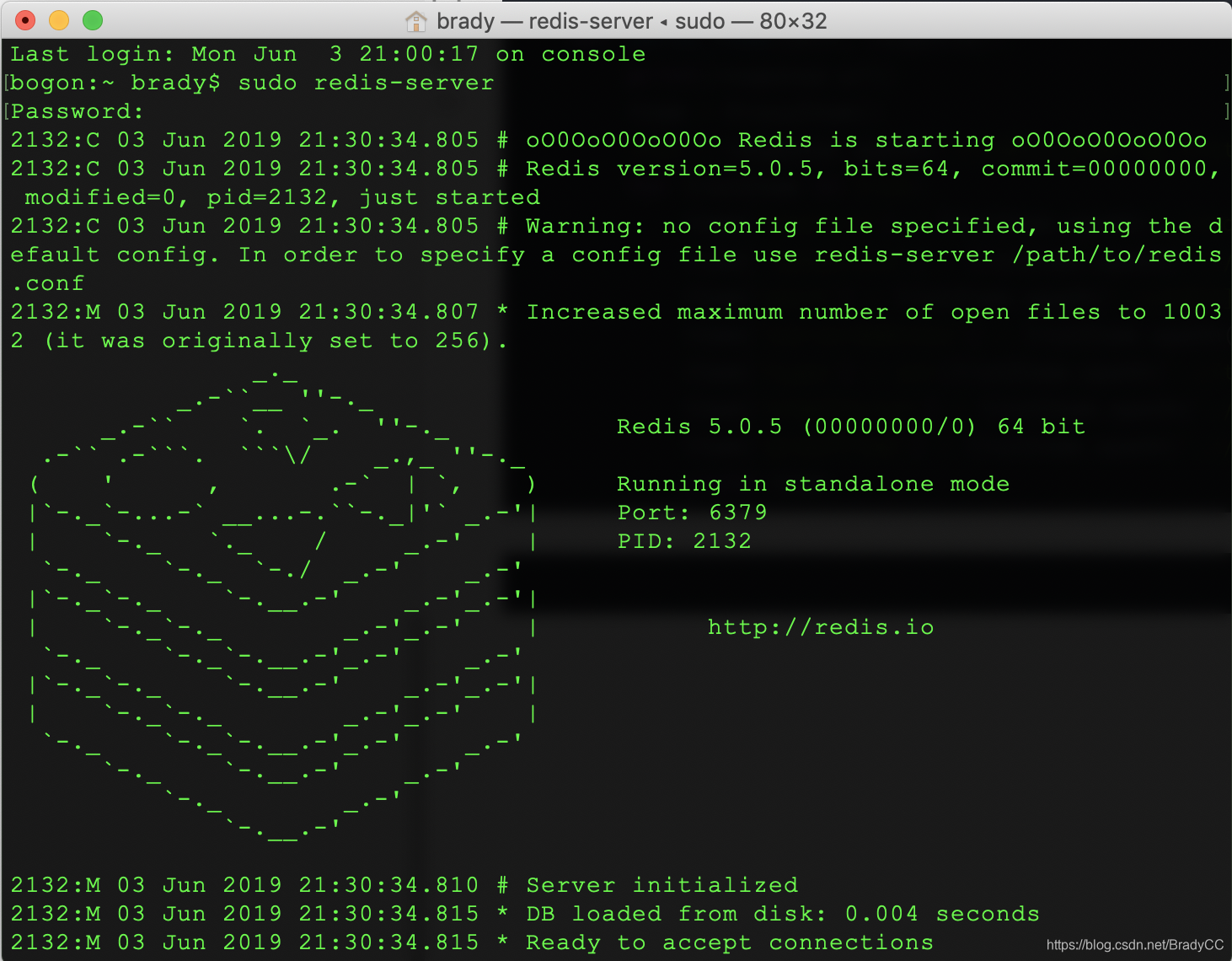
启动 redis服务 - redis-server。
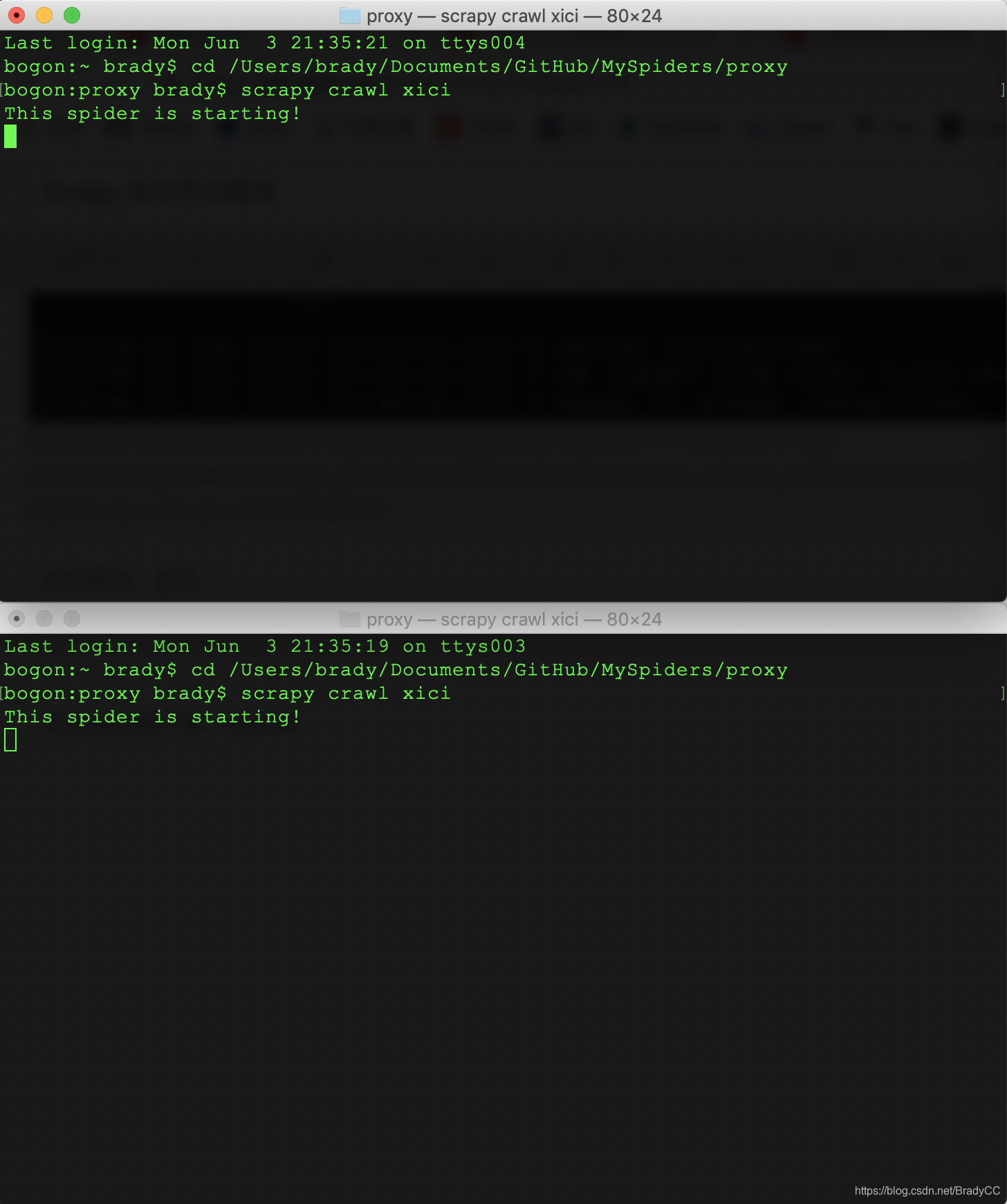
启动爬虫,监听
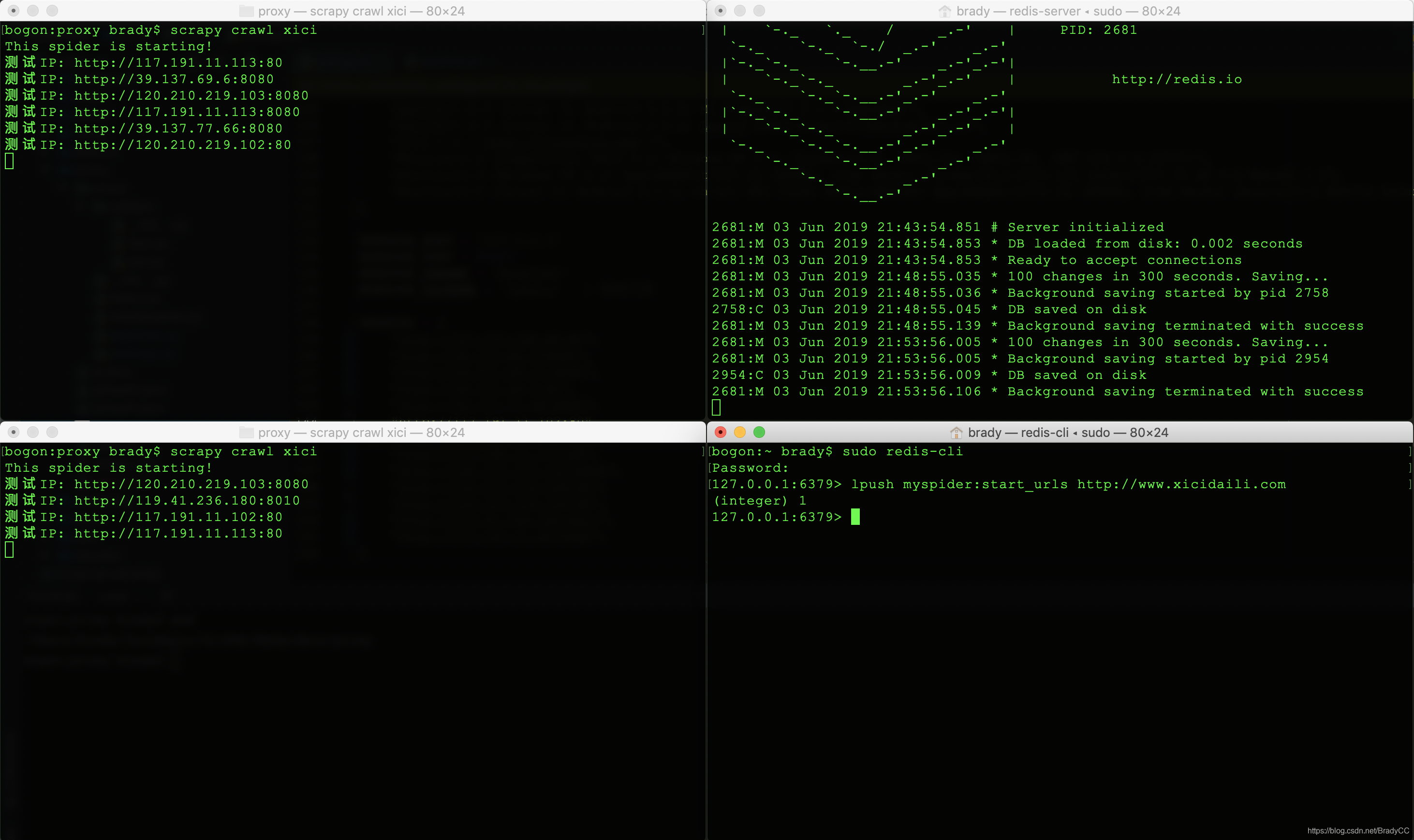
启动redis客户端 - redis-cli, 执行伪分布式爬虫


相关文章推荐
- Scrapy分布式爬虫之ES搜索引擎网站
- 第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中
- 第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查
- python爬虫框架之Scrapy之分布式 + selenium爬取蘑菇街
- Redis-Scrapy分布式爬虫:当当网图书为例
- scrapy-redis实现爬虫分布式爬取分析与实现
- 第三百五十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—chrome谷歌浏览器无界面运行、scrapy-splash、splinter
- 第三百五十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy信号详解
- 第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
- 分布式爬虫:使用Scrapy抓取数据
- 简单的scrapy爬虫分布式
- 第三百三十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式
- 部署Scrapy分布式爬虫项目
- 第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
- 第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念
- python爬虫框架之Scrapy分布式的使用