Hive环境搭建以及基本操作和运维(详细),如内置函数,Join和GroupBy以及where用法 和JDBC 的java代码操作(Mysql数据库)
Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据。它架构在Hadoop之上,总归为大数据,并使得查询和分析方便。并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。
术语“大数据”是大型数据集,其中包括体积庞大,高速,以及各种由与日俱增的数据的集合。 使用传统的数据管理系统,它是难以加工大型数据。 因此,Apache软件基金会推出了一款名为Hadoop的解决大数据管理和处理难题的框架。
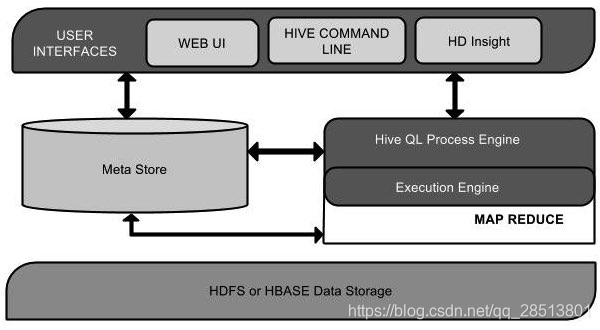
那么hive到底是什么呢? 其实Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据。它架构在Hadoop之上,总归为大数据,并使得查询和分析方便。 最初,Hive是由Facebook开发,后来由Apache软件基金会开发,并作为进一步将它作为名义下Apache Hive为一个开源项目。它用在好多不同的公司。例如,亚马逊使用它在 Amazon Elastic MapReduce。
从上面的hive得到架构图可以了解到不同组件之间的单元关系
| 单元名称 | 操作 |
|---|---|
| 用户接口/界面 | Hive是一个数据仓库基础工具软件,可以创建用户和HDFS之间互动。用户界面,Hive支持是Hive的Web UI,Hive命令行,HiveHD洞察(在Windows服务器)。 |
| 元存储 | Hive选择各自的数据库服务器,用以储存表,数据库,列模式或元数据表,它们的数据类型和HDFS映射。 |
| HiveQL处理引擎 | HiveQL类似于SQL的查询上Metastore模式信息。这是传统的方式进行MapReduce程序的替代品之一。相反,使用Java编写的MapReduce程序,可以编写为MapReduce工作,并处理它的查询。 |
| 执行引擎 | HiveQL处理引擎和MapReduce的结合部分是由Hive执行引擎。执行引擎处理查询并产生结果和MapReduce的结果一样。它采用MapReduce方法。 |
| HDFS 或 HBASE | Hadoop的分布式文件系统或者HBASE数据存储技术是用于将数据存储到文件系统。 |
Hive工作原理
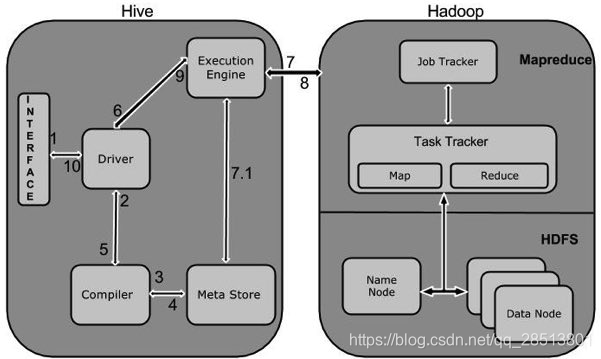
下表定义Hive和Hadoop框架的交互方式:
| Step No | 操作 |
|---|---|
| 1 | Execute Query … Hive接口,如命令行或Web UI发送查询驱动程序(任何数据库驱动程序,如JDBC,ODBC等)来执行。 |
| 2 | Get Plan…在驱动程序帮助下查询编译器,分析查询检查语法和查询计划或查询的要求. |
| 3 | Get Metadata… 编译器发送元数据请求到Metastore(任何数据库) |
| 4 | Send Metadata… Metastore发送元数据,以编译器的响应。 |
| 5 | Send Plan…编译器检查要求,并重新发送计划给驱动程序。到此为止,查询解析和编译完成。 |
| 6 | Execute Plan…驱动程序发送的执行计划到执行引擎。 |
| 7 | Execute Job…在内部,执行作业的过程是一个MapReduce工作。执行引擎发送作业给JobTracker,在名称节点并把它分配作业到TaskTracker,这是在数据节点。在这里,查询执行MapReduce工作 |
| 7.1 | Metadata Ops…与此同时,在执行时,执行引擎可以通过Metastore执行元数据操作。 |
| 8 | Fetch Result…执行引擎接收来自数据节点的结果。 |
| 9 | Send Results…执行引擎发送这些结果值给驱动程序。 |
| 10 | Send Results…驱动程序将结果发送给Hive接口。 |
Hive所有数据类型分为四种类型,给出如下:
列类型 文字 Null 值 复杂类型
一:列举型
列类型被用作Hive的列数据类型。它们如下: ①整型 整型数据可以指定使用整型数据类型,INT。 当数据范围超过INT的范围,需要使用BIGINT,如果数据范围比INT小,使用SMALLINT。 TINYINT比SMALLINT小。

②字符串类型
字符串类型的数据类型可以使用单引号('')或双引号(“”)来指定。它包含两个数据类型:VARCHAR和CHAR。
Hive遵循C-类型的转义字符。

时间戳
它支持传统的UNIX时间戳可选纳秒的精度。 它支持的java.sql.Timestamp格式“YYYY-MM-DD HH:MM:SS.fffffffff”和格式“YYYY-MM-DD HH:MM:ss.ffffffffff”。
日期
DATE值在年/月/日的格式形式描述 {{YYYY-MM-DD}}.
小数点
在Hive 小数类型与Java大十进制格式相同。它是用于表示不可改变任意精度。语法和示例如下:
DECIMAL(precision, scale) decimal(10,0)
联合类型
联合是异类的数据类型的集合。可以使用联合创建的一个实例。语法和示例如下:
UNIONTYPE<int, double, array<string>, struct<a:int,b:string>>
{0:1}
{1:2.0}
{2:["three","four"]}
{3:{"a":5,"b":"five"}}
{2:["six","seven"]}
{3:{"a":8,"b":"eight"}}
{0:9}
{1:10.0}
复杂类型
数组
在Hive 数组与在Java中使用的方法相同。
Syntax: ARRAY<data_type>
映射
映射在Hive类似于Java的映射。
Syntax: MAP<primitive_type, data_type>
结构体
在Hive结构体类似于使用复杂的数据。
Syntax: STRUCT<col_name : data_type [COMMENT col_comment], ...>
Hive是一种数据库技术,可以定义数据库和表来分析结构化数据。
主题结构化数据分析是以表方式存储数据,并通过查询来分析。
CREATE DATABASE语句
创建数据库是用来创建数据库在Hive中语句。在Hive数据库是一个命名空间或表的集合。此语法声明如下:
CREATE DATABASE|SCHEMA [IF NOT EXISTS] <database name>
在这里,IF NOT EXISTS是一个可选子句,通知用户已经存在相同名称的数据库。可以使用SCHEMA 在DATABASE的这个命令。下面的查询执行创建一个名为userdb数据库:
hive> CREATE DATABASE [IF NOT EXISTS] userdb; 或者 hive> CREATE SCHEMA userdb;
JDBC 程序
在JDBC程序来创建数据库如下。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveCreateDb {
private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.getConnection("jdbc:hive://localhost:10000/default", "", "");
Statement stmt = con.createStatement();
stmt.executeQuery("CREATE DATABASE userdb");
System.out.println(“Database userdb created successfully.”);
con.close();
}
}
保存程序在一个名为HiveCreateDb.java文件。下面的命令用于编译和执行这个程序。
$ javac HiveCreateDb.java
$ java HiveCreateDb
输出:
Database userdb created successfully.
DROP DATABASE语句
DROP DATABASE是删除所有的表并删除数据库的语句。它的语法如下:
DROP DATABASE StatementDROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
下面的查询用于删除数据库。假设要删除的数据库名称为userdb。
hive> DROP DATABASE IF EXISTS userdb;
以下是使用CASCADE查询删除数据库。这意味着要全部删除相应的表在删除数据库之前。
hive> DROP DATABASE IF EXISTS userdb CASCADE;
以下使用SCHEMA查询删除数据库。
hive> DROP SCHEMA userdb;
在JDBC程序来删除数据库如下。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveDropDb {
private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.getConnection("jdbc:hive://localhost:10000/default", "", "");
Statement stmt = con.createStatement();
stmt.executeQuery("DROP DATABASE userdb");
System.out.println(“Drop userdb database successful.”);
con.close();
}
}
Create Table是用于在Hive中创建表的语句。语法和示例如下:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [ROW FORMAT row_format] [STORED AS file_format]
假设需要使用CREATE TABLE语句创建一个名为employee表。下表列出了employee表中的字段和数据类型:
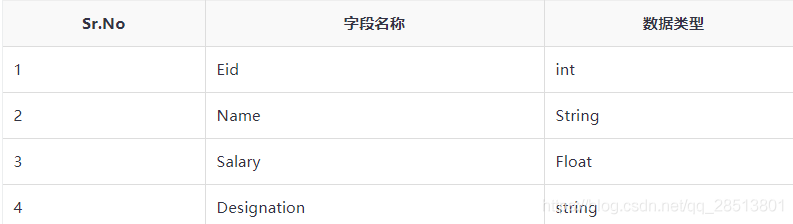
下面的数据是一个注释,行格式字段,如字段终止符,行终止符,并保存的文件类型。
COMMENT ‘Employee details’ FIELDS TERMINATED BY ‘\t’ LINES TERMINATED BY ‘\n’ STORED IN TEXT FILE
下面的查询创建使用上述数据的表名为 employee。
hive> CREATE TABLE IF NOT EXISTS employee ( eid int, name String, > salary String, destination String) > COMMENT ‘Employee details’ > ROW FORMAT DELIMITED > FIELDS TERMINATED BY ‘\t’ > LINES TERMINATED BY ‘\n’ > STORED AS TEXTFILE;
如果添加选项IF NOT EXISTS,Hive 忽略大小写,万一表已经存在的声明。
成功创建表后,能看到以下回应:
OK Time taken: 5.905 seconds hive>
下面是是使用JDBC程序来创建表给出的一个例子。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveCreateTable {
private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("CREATE TABLE IF NOT EXISTS "
+" employee ( eid int, name String, "
+" salary String, destignation String)"
+" COMMENT ‘Employee details’"
+" ROW FORMAT DELIMITED"
+" FIELDS TERMINATED BY ‘\t’"
+" LINES TERMINATED BY ‘\n’"
+" STORED AS TEXTFILE;");
System.out.println(“ Table employee created.”);
con.close();
}
}
输出
Table employee created.
LOAD DATA语句
一般来说,在SQL创建表后,我们就可以使用INSERT语句插入数据。但在Hive中,可以使用LOAD DATA语句插入数据。
同时将数据插入到Hive,最好是使用LOAD DATA来存储大量记录。
有两种方法用来加载数据:一种是从本地文件系统,第二种是从Hadoop文件系统。
加载数据的语法如下:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] \ LOCAL是标识符指定本地路径。它是可选的。 OVERWRITE 是可选的,覆盖表中的数据。 PARTITION 这是可选的
我们将插入下列数据到表中。在/home/user目录中名为sample.txt的文件
1201 Gopal 45000 Technical manager 1202 Manisha 45000 Proof reader 1203 Masthanvali 40000 Technical writer 1204 Kiran 40000 Hr Admin 1205 Kranthi 30000 Op Admin
下面的查询加载给定文本插入表中。
hive> LOAD DATA LOCAL INPATH '/home/user/sample.txt' > OVERWRITE INTO TABLE employee;
下载成功完成,能看到以下回应:
OK Time taken: 15.905 seconds hive>
下面给出的是JDBC程序将给定的数据加载到表中。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveLoadData {
private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("LOAD DATA LOCAL INPATH '/home/user/sample.txt'" + "OVERWRITE INTO TABLE employee;");
System.out.println("Load Data into employee successful");
con.close();
}
}
输出:
Load Data into employee successful
Alter Table 语句
它是在Hive中用来修改的表。
声明接受任意属性,我们希望在一个表中修改以下语法。
ALTER TABLE name RENAME TO new_name ALTER TABLE name ADD COLUMNS (col_spec[, col_spec ...]) ALTER TABLE name DROP [COLUMN] column_name ALTER TABLE name CHANGE column_name new_name new_type ALTER TABLE name REPLACE COLUMNS (col_spec[, col_spec ...])
Rename To… 语句
下面是查询重命名表,把 employee 修改为 emp。
hive> ALTER TABLE employee RENAME TO emp;
JDBC 程序
在JDBC程序重命名表如下。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveAlterRenameTo {
private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("ALTER TABLE employee RENAME TO emp;");
System.out.println("Table Renamed Successfully");
con.close();
}
}
输出
Table renamed successfully.
Change 语句
下表包含employee表的字段,它显示的字段要被更改(粗体)
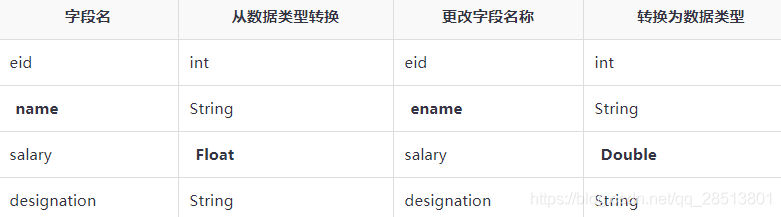
下面查询重命名使用上述数据的列名和列数据类型:
hive> ALTER TABLE employee CHANGE name ename String; hive> ALTER TABLE employee CHANGE salary salary Double;
JDBC 程序
下面给出的是使用JDBC程序来更改列。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveAlterChangeColumn {
private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("ALTER TABLE employee CHANGE name ename String;");
stmt.executeQuery("ALTER TABLE employee CHANGE salary salary Double;");
System.out.println("Change column successful.");
con.close();
}
}
输出
Change column successful.
添加列语句
下面的查询增加了一个列名dept在employee表。
hive> ALTER TABLE employee ADD COLUMNS ( > dept STRING COMMENT 'Department name');
JDBC程序添加列到表如下。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveAlterAddColumn {
private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("ALTER TABLE employee ADD COLUMNS " + " (dept STRING COMMENT 'Department name');");
System.out.prinln("Add column successful.");
con.close();
}
}
输出
Add column successful.
REPLACE语句
以下从employee表中查询删除的所有列,并使用emp替换列:
hive> ALTER TABLE employee REPLACE COLUMNS ( > eid INT empid Int, > ename STRING name String);
下面给出的是JDBC程序使用empid代替eid列,name代替ename列。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveAlterReplaceColumn {
private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("ALTER TABLE employee REPLACE COLUMNS "
+" (eid INT empid Int,"
+" ename STRING name String);");
System.out.println(" Replace column successful");
con.close();
}
}
输出:
Replace column successful.
Drop Table语句
语法如下:
DROP TABLE [IF EXISTS] table_name;
以下查询删除一个名为 employee 的表:
hive> DROP TABLE IF EXISTS employee; 对于成功执行查询,能看到以下回应: OK Time taken: 5.3 seconds hive>
下面JDBC程序删除employee表。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveDropTable {
private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("DROP TABLE IF EXISTS employee;");
System.out.println("Drop table successful.");
con.close();
}
}
输出
Drop table successful
添加分区
可以通过添加分区表改变所述表。假设我们有一个表叫employee ,拥有如 Id, Name, Salary, Designation, Dept, 和 yoj等字段。
ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec [LOCATION 'location1'] partition_spec [LOCATION 'location2'] ...; partition_spec: : (p_column = p_col_value, p_column = p_col_value, ...)
以下查询用于将分区添加到employee表。
hive> ALTER TABLE employee > ADD PARTITION (year=’2019’) > location '/2019/part2019';
重命名分区
ALTER TABLE table_name PARTITION partition_spec RENAME TO PARTITION partition_spec;
以下查询用来命名一个分区:
hive> ALTER TABLE employee PARTITION (year=’1203’) > RENAME TO PARTITION (Yoj=’1203’);
删除分区
下面语法用于删除分区:
ALTER TABLE table_name DROP [IF EXISTS] PARTITION partition_spec, PARTITION partition_spec,...;
以下查询是用来删除分区:
hive> ALTER TABLE employee DROP [IF EXISTS] > PARTITION (year=’2019’);
关系运算符
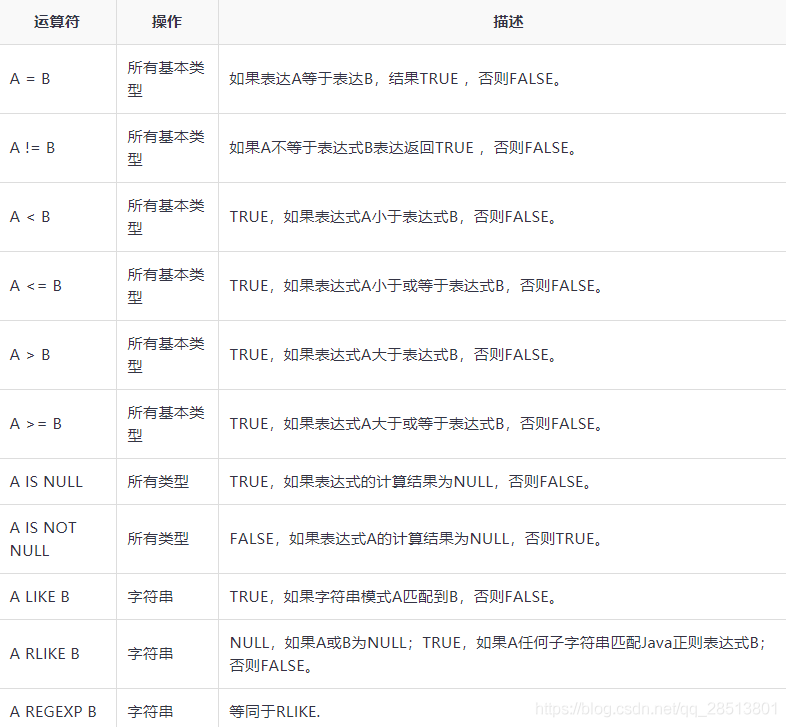
让我们假设employee表由字段:Id, Name, Salary, Designation, 和Dept组成,如下图所示。生成一个查询检索员工详细信息 - ID为1205。
+-----+--------------+--------+---------------------------+------+ | Id | Name | Salary | Designation | Dept | +-----+--------------+------------------------------------+------+ |1201 | Gopal | 45000 | Technical manager | TP | |1202 | Manisha | 45000 | Proofreader | PR | |1203 | Masthanvali | 40000 | Technical writer | TP | |1204 | Krian | 40000 | Hr Admin | HR | |1205 | Kranthi | 30000 | Op Admin | Admin| +-----+--------------+--------+---------------------------+------+
以下查询执行检索使用上述表中的雇员的详细信息:
hive> SELECT * FROM employee WHERE Id=1205; 成功执行的查询,能看到以下回应: +-----+-----------+-----------+----------------------------------+ | ID | Name | Salary | Designation | Dept | +-----+---------------+-------+----------------------------------+ |1205 | Kranthi | 30000 | Op Admin | Admin | +-----+-----------+-----------+----------------------------------+
下面的查询执行以检索薪水大于或等于40000卢比的雇员的详细信息。
hive> SELECT * FROM employee WHERE Salary>=40000; 成功执行的查询,能看到以下回应: +-----+------------+--------+----------------------------+------+ | ID | Name | Salary | Designation | Dept | +-----+------------+--------+----------------------------+------+ |1201 | Gopal | 45000 | Technical manager | TP | |1202 | Manisha | 45000 | Proofreader | PR | |1203 | Masthanvali| 40000 | Technical writer | TP | |1204 | Krian | 40000 | Hr Admin | HR | +-----+------------+--------+----------------------------+------+
算术运算符

下面的查询相加两个数字,20和30。
hive> SELECT 20+30 ADD FROM temp; 在成功执行查询后,能看到以下回应: +--------+ | ADD | +--------+ | 50 | +--------+
逻辑运算符
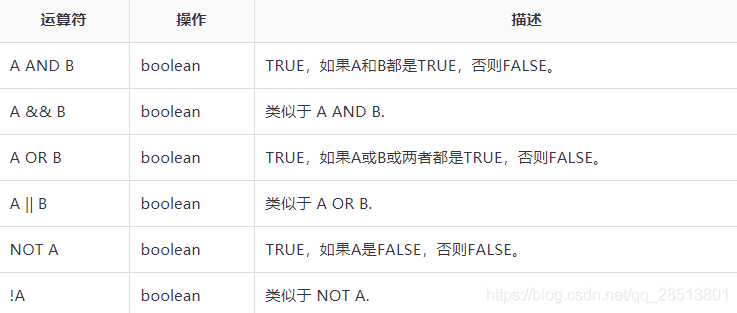
下面的查询用于检索部门是TP并且工资超过40000卢比的员工详细信息。
hive> SELECT * FROM employee WHERE Salary>40000 && Dept=TP; 成功执行查询后,能看到以下回应: +------+--------------+-------------+-------------------+--------+ | ID | Name | Salary | Designation | Dept | +------+--------------+-------------+-------------------+--------+ |1201 | Gopal | 45000 | Technical manager | TP | +------+--------------+-------------+-------------------+--------+
复杂的运算符
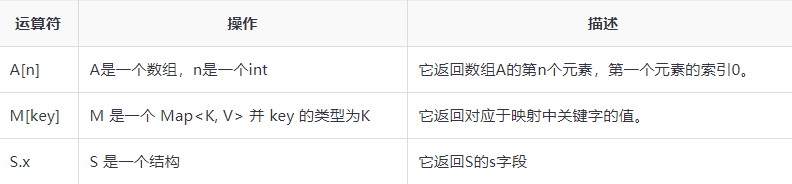
内置函数
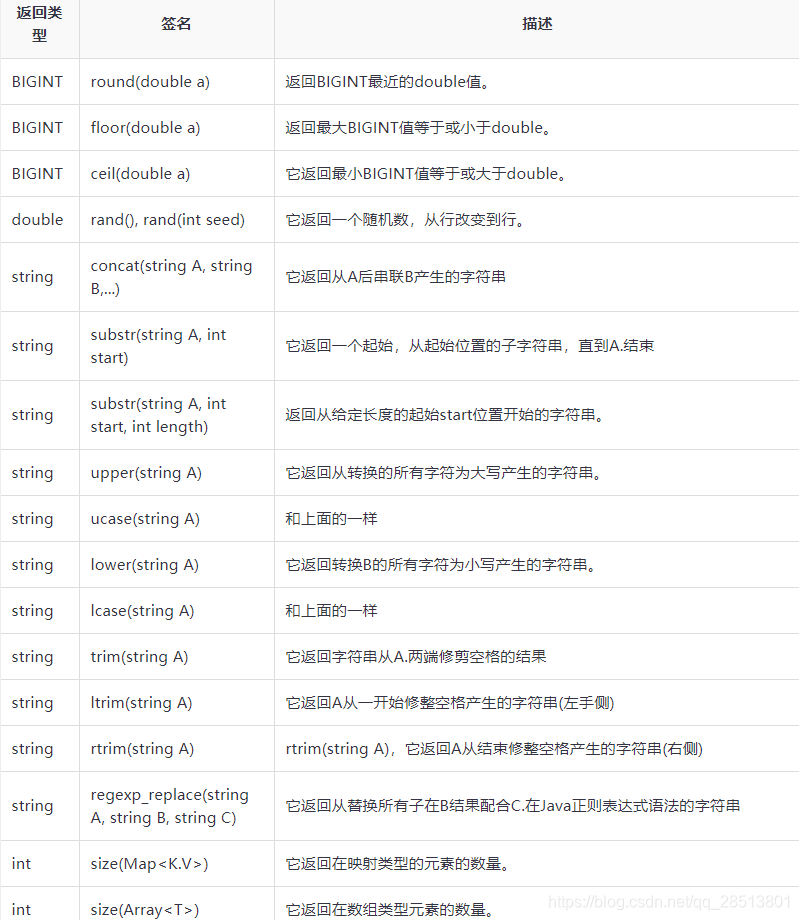
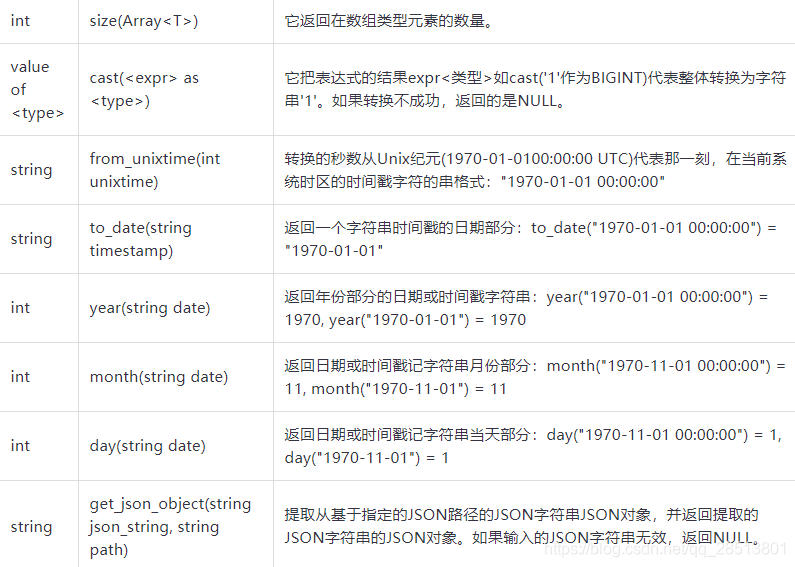
以下查询演示了一些内置函数:
round() 函数
hive> SELECT round(2.6) from temp; 成功执行的查询,能看到以下回应: 2.0
floor() 函数
hive> SELECT ceil(2.6) from temp; 成功执行的查询,能看到以下回应: 3.0
聚合函数
Hive支持以下内置聚合函数。这些函数的用法类似于SQL聚合函数。
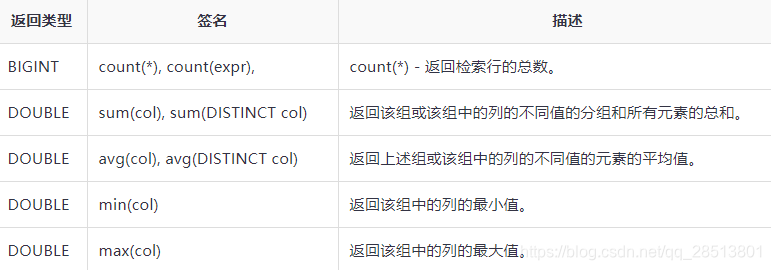
。根据用户的需求创建视图。可以将任何结果集数据保存为一个视图。视图在Hive的用法和SQL视图用法相同。它是一个标准的RDBMS概念。我们可以在视图上执行所有DML操作。
创建一个视图
可以创建一个视图,在执行SELECT语句的时候。语法如下:
CREATE VIEW [IF NOT EXISTS] view_name [(column_name [COMMENT column_comment], ...) ] [COMMENT table_comment] AS SELECT ...
示例
举个例子来看。假设employee表拥有如下字段:Id, Name, Salary, Designation 和 Dept。生成一个查询检索工资超过30000卢比的员工详细信息,我们把结果存储在一个名为视图 emp_30000.
+------+--------------+-------------+-------------------+--------+ | ID | Name | Salary | Designation | Dept | +------+--------------+-------------+-------------------+--------+ |1201 | Gopal | 45000 | Technical manager | TP | |1202 | Manisha | 45000 | Proofreader | PR | |1203 | Masthanvali | 40000 | Technical writer | TP | |1204 | Krian | 40000 | Hr Admin | HR | |1205 | Kranthi | 30000 | Op Admin | Admin | +------+--------------+-------------+-------------------+--------+下面使用上述业务情景查询检索员的工详细信息: hive> CREATE VIEW emp_30000 AS > SELECT * FROM employee > WHERE salary>30000;
删除一个视图
使用下面的语法来删除视图:
DROP VIEW view_name
下面的查询删除一个名为emp_30000的视图:
hive> DROP VIEW emp_30000;
创建索引
索引也不过是一个表上的一个特定列的指针。创建索引意味着创建一个表上的一个特定列的指针。它的语法如下:
CREATE INDEX index_name ON TABLE base_table_name (col_name, ...) AS 'index.handler.class.name' [WITH DEFERRED REBUILD] [IDXPROPERTIES (property_name=property_value, ...)] [IN TABLE index_table_name] [PARTITIONED BY (col_name, ...)] [ [ ROW FORMAT ...] STORED AS ... | STORED BY ... ] [LOCATION hdfs_path] [TBLPROPERTIES (...)]
例子
让我们举个索引例子。使用之前的字段 Id, Name, Salary, Designation, 和 Dept创建一个名为index_salary的索引,对employee 表的salary列索引。
下面的查询创建一个索引:
hive> CREATE INDEX inedx_salary ON TABLE employee(salary) > AS 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler'; 这是一个指向salary列。如果列被修改,变更使用的索引值存储。
删除索引
下面的语法用来删除索引:
DROP INDEX <index_name> ON <table_name>
下面的查询删除名为index_salary索引
hive> DROP INDEX index_salary ON employee;
Hive查询语言(HiveQL)是一种查询语言,Hive处理在Metastore分析结构化数据
SELECT语句用来从表中检索的数据。 WHERE子句中的工作原理类似于一个条件。它使用这个条件过滤数据,并返回给出一个有限的结果。内置运算符和函数产生一个表达式,满足以下条件。
下面给出的是SELECT查询的语法:
SELECT [ALL | DISTINCT] select_expr, select_expr, ... FROM table_reference [WHERE where_condition] [GROUP BY col_list] [HAVING having_condition] [CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list]] [LIMIT number];
让我们举个例子SELECT … WHERE子句。假设employee表有如下 Id, Name, Salary, Designation, 和 Dept等字段,生成一个查询检索超过30000薪水的员工详细信息。
+------+--------------+-------------+-------------------+--------+ | ID | Name | Salary | Designation | Dept | +------+--------------+-------------+-------------------+--------+ |1201 | Gopal | 45000 | Technical manager | TP | |1202 | Manisha | 45000 | Proofreader | PR | |1203 | Masthanvali | 40000 | Technical writer | TP | |1204 | Krian | 40000 | Hr Admin | HR | |1205 | Kranthi | 30000 | Op Admin | Admin | +------+--------------+-------------+-------------------+--------+
下面的查询检索使用上述业务情景的员工详细信息:
hive> SELECT * FROM employee WHERE salary>30000; 成功执行查询后,能看到以下回应: +------+--------------+-------------+-------------------+--------+ | ID | Name | Salary | Designation | Dept | +------+--------------+-------------+-------------------+--------+ |1201 | Gopal | 45000 | Technical manager | TP | |1202 | Manisha | 45000 | Proofreader | PR | |1203 | Masthanvali | 40000 | Technical writer | TP | |1204 | Krian | 40000 | Hr Admin | HR | +------+--------------+-------------+-------------------+--------+
在JDBC程序应用,其中针对给定的例子如下子句。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveQLWhere {
private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
Resultset res = stmt.executeQuery("SELECT * FROM employee WHERE salary>30000;");
System.out.println("Result:");
System.out.println(" ID \t Name \t Salary \t Designation \t Dept ");
while (res.next()) {
System.out.println(res.getInt(1) + " " + res.getString(2) + " " + res.getDouble(3) + " " + res.getString(4) + " " + res.getString(5));
}
con.close();
}
}
输出:
ID Name Salary Designation Dept
1201 Gopal 45000 Technical manager TP
1202 Manisha 45000 Proofreader PR
1203 Masthanvali 40000 Technical writer TP
1204 Krian 40000 Hr Admin HR
ORDER BY子句用于检索基于一列的细节并设置排序结果按升序或降序排列。
下面给出的是ORDER BY子句的语法:
SELECT [ALL | DISTINCT] select_expr, select_expr, ... FROM table_reference [WHERE where_condition] [GROUP BY col_list] [HAVING having_condition] [ORDER BY col_list]] [LIMIT number];
让我们举个SELECT … ORDER BY子句的例子。假设员工表,如下Id, Name, Salary, Designation, 和 Dept 的字段,生成一个查询用于检索员工的详细信息。
+------+--------------+-------------+-------------------+--------+ | ID | Name | Salary | Designation | Dept | +------+--------------+-------------+-------------------+--------+ |1201 | Gopal | 45000 | Technical manager | TP | |1202 | Manisha | 45000 | Proofreader | PR | |1203 | Masthanvali | 40000 | Technical writer | TP | |1204 | Krian | 40000 | Hr Admin | HR | |1205 | Kranthi | 30000 | Op Admin | Admin | +------+--------------+-------------+-------------------+--------+
下面是使用上述业务情景查询检索员工详细信息:
hive> SELECT Id, Name, Dept FROM employee ORDER BY DEPT; 成功执行查询后,能看到以下回应: +------+--------------+-------------+-------------------+--------+ | ID | Name | Salary | Designation | Dept | +------+--------------+-------------+-------------------+--------+ |1205 | Kranthi | 30000 | Op Admin | Admin | |1204 | Krian | 40000 | Hr Admin | HR | |1202 | Manisha | 45000 | Proofreader | PR | |1201 | Gopal | 45000 | Technical manager | TP | |1203 | Masthanvali | 40000 | Technical writer | TP | +------+--------------+-------------+-------------------+--------+
下面是JDBC程序应用给定Order By子句的例子。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveQLOrderBy {
private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
Resultset res = stmt.executeQuery("SELECT * FROM employee ORDER BY DEPT;");
System.out.println(" ID \t Name \t Salary \t Designation \t Dept ");
while (res.next()) {
System.out.println(res.getInt(1) + " " + res.getString(2) + " " + res.getDouble(3) + " " + res.getString(4) + " " + res.getString(5));
}
con.close();
}
}
输出
ID Name Salary Designation Dept
1205 Kranthi 30000 Op Admin Admin
1204 Krian 40000 Hr Admin HR
1202 Manisha 45000 Proofreader PR
1201 Gopal 45000 Technical manager TP
1203 Masthanvali 40000 Technical writer TP
1204 Krian 40000 Hr Admin HR
GROUP BY子句用于分类所有记录结果的特定集合列。它被用来查询一组记录。
GROUP BY子句的语法如下:
SELECT [ALL | DISTINCT] select_expr, select_expr, ... FROM table_reference [WHERE where_condition] [GROUP BY col_list] [HAVING having_condition] [ORDER BY col_list]] [LIMIT number];
让我们以SELECT… GROUP BY子句为例。假设员工表有如下Id, Name, Salary, Designation, 和 Dept字段。产生一个查询以检索每个部门的员工数量。
+------+--------------+-------------+-------------------+--------+ | ID | Name | Salary | Designation | Dept | +------+--------------+-------------+-------------------+--------+ |1201 | Gopal | 45000 | Technical manager | TP | |1202 | Manisha | 45000 | Proofreader | PR | |1203 | Masthanvali | 40000 | Technical writer | TP | |1204 | Krian | 45000 | Proofreader | PR | |1205 | Kranthi | 30000 | Op Admin | Admin | +------+--------------+-------------+-------------------+--------+
下面使用上述业务情景查询检索员工的详细信息。
hive> SELECT Dept,count(*) FROM employee GROUP BY DEPT; 成功执行查询后,能看到以下回应: +------+--------------+ | Dept | Count(*) | +------+--------------+ |Admin | 1 | |PR | 2 | |TP | 3 | +------+--------------+
下面给出的是JDBC程序应用对给定的GROUP BY子句例子。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveQLGroupBy {
private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
Resultset res = stmt.executeQuery(“SELECT Dept,count(*) ” + “FROM employee GROUP BY DEPT; ”);
System.out.println(" Dept \t count(*)");
while (res.next()) {
System.out.println(res.getString(1) + " " + res.getInt(2));
}
con.close();
}
}
输出:
Dept Count(*)
Admin 1
PR 2
TP 3
JOIN是子句用于通过使用共同值组合来自两个表特定字段。它是用来从数据库中的两个或更多的表组合的记录。它或多或少类似于SQL JOIN。
语法
join_table:
table_reference JOIN table_factor [join_condition]
| table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference
join_condition
| table_reference LEFT SEMI JOIN table_reference join_condition
| table_reference CROSS JOIN table_reference [join_condition]
我们在本章中将使用下面的两个表。考虑下面的表CUSTOMERS…
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+ 考虑另一个表命令如下: +-----+---------------------+-------------+--------+ |OID | DATE | CUSTOMER_ID | AMOUNT | +-----+---------------------+-------------+--------+ | 102 | 2009-10-08 00:00:00 | 3 | 3000 | | 100 | 2009-10-08 00:00:00 | 3 | 1500 | | 101 | 2009-11-20 00:00:00 | 2 | 1560 | | 103 | 2008-05-20 00:00:00 | 4 | 2060 | +-----+---------------------+-------------+--------+ 有不同类型的联接给出如下: JOIN LEFT OUTER JOIN RIGHT OUTER JOIN FULL OUTER JOIN
JOIN
JOIN子句用于合并和检索来自多个表中的记录。 JOIN和SQLOUTER JOIN 类似。连接条件是使用主键和表的外键。
下面的查询执行JOIN的CUSTOMER和ORDER表,并检索记录:
hive> SELECT c.ID, c.NAME, c.AGE, o.AMOUNT > FROM CUSTOMERS c JOIN ORDERS o > ON (c.ID = o.CUSTOMER_ID); 成功执行查询后,能看到以下回应: +----+----------+-----+--------+ | ID | NAME | AGE | AMOUNT | +----+----------+-----+--------+ | 3 | kaushik | 23 | 3000 | | 3 | kaushik | 23 | 1500 | | 2 | Khilan | 25 | 1560 | | 4 | Chaitali | 25 | 2060 | +----+----------+-----+--------+
LEFT OUTER JOIN
HiveQL LEFT OUTER JOIN返回所有行左表,即使是在正确的表中没有匹配。这意味着,如果ON子句匹配的右表0(零)记录,JOIN还是返回结果行,但在右表中的每一列为NULL。 LEFT JOIN返回左表中的所有的值,加上右表,或JOIN子句没有匹配的情况下返回NULL。
下面的查询演示了CUSTOMER 和ORDER 表之间的LEFT 4000 OUTER JOIN用法:
hive> SELECT c.ID, c.NAME, o.AMOUNT, o.DATE > FROM CUSTOMERS c > LEFT OUTER JOIN ORDERS o > ON (c.ID = o.CUSTOMER_ID); 成功执行查询后,能看到以下回应: +----+----------+--------+---------------------+ | ID | NAME | AMOUNT | DATE | +----+----------+--------+---------------------+ | 1 | Ramesh | NULL | NULL | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | | 5 | Hardik | NULL | NULL | | 6 | Komal | NULL | NULL | | 7 | Muffy | NULL | NULL | +----+----------+--------+---------------------+
RIGHT OUTER JOIN
HiveQL RIGHT OUTER JOIN返回右边表的所有行,即使有在左表中没有匹配。如果ON子句的左表匹配0(零)的记录,JOIN结果返回一行,但在左表中的每一列为NULL。
RIGHT JOIN返回右表中的所有值,加上左表,或者没有匹配的情况下返回NULL。
下面的查询演示了在CUSTOMER和ORDER表之间使用RIGHT OUTER JOIN。
hive> SELECT c.ID, c.NAME, o.AMOUNT, o.DATE > FROM CUSTOMERS c > RIGHT OUTER JOIN ORDERS o > ON (c.ID = o.CUSTOMER_ID); 成功执行查询后,能看到以下回应: +------+----------+--------+---------------------+ | ID | NAME | AMOUNT | DATE | +------+----------+--------+---------------------+ | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | +------+----------+--------+---------------------+
FULL OUTER JOIN
HiveQL FULL OUTER JOIN结合了左边,并且满足JOIN条件合适外部表的记录。连接表包含两个表的所有记录,或两侧缺少匹配结果那么使用NULL值填补
下面的查询演示了CUSTOMER 和ORDER 表之间使用的FULL OUTER JOIN:
hive> SELECT c.ID, c.NAME, o.AMOUNT, o.DATE > FROM CUSTOMERS c > FULL OUTER JOIN ORDERS o > ON (c.ID = o.CUSTOMER_ID); 成功执行查询后,能看到以下回应: +------+----------+--------+---------------------+ | ID | NAME | AMOUNT | DATE | +------+----------+--------+---------------------+ | 1 | Ramesh | NULL | NULL | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | | 5 | Hardik | NULL | NULL | | 6 | Komal | NULL | NULL | | 7 | Muffy | NULL | NULL | | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | +------+----------+--------+---------------------+
HIVE环境搭建。
实验原理:
Hive工具中默认使用的是derby数据库,该数据库使用简单,该数据库使用简单,
操作灵活,但是存在一定的局限性,hive支持使用第三方数据库,
例如mysql,通过配置可以把mysql集成到hive工具中,在事迹的应用当中就比较方便,mysql功能更强大一些,社会中应用也广泛一些。
实验环境:Centos7+Hadoop2.7.6 + jdk1.8.0_171+mysql+hive1.2.2
[root@master softpackage]# ls apache-hive-1.2.2-bin.tar.gz hadoop-2.7.6.tar.gz jdk-12.0.1_linux-x64_bin.tar.gz spark-2.0.1-bin-hadoop2.7.tgz apache-hive-2.3.4-bin.tar.gz hadoop-3.1.2-src.tar.gz jdk-8u171-linux-x64.tar.gz spark-2.4.1-bin-hadoop2.7.tgz [root@master softpackage]# pwd /opt/softpackage [root@master softpackage]#
一:解压Hive
1.1 在linux系统下,首先执行cd /opt/softpackage 命令进入到opt目录下的softpackage目录中。然后把该目录下的hive压缩包解压到/opt/目录下
[root@master softpackage]# tar -zxvf apache-hive-1.2.2-bin.tar.gz -C /opt/
1.2执行解压完毕后,查看一下我们的解压包
[root@master opt]# cd /opt/ [root@master opt]# ls apache-hive-1.2.2-bin hadoop-2.7.6 jdk1.8.0_171 mm.txt softpackage centos hbase-1.2.12 like mysql-connector-java-5.1.7-bin.jar word.txt CentOS-7-x86_64-DVD-1511.iso hbase-1.2.12-bin.tar.gz mapper.py reducer.py [root@master opt]#

二 :配置Hive
2.1 解压完毕hive压缩包后,切换目录到/opt/apache-hive-1.2.2-bin 下并且查看文件列表
[root@master opt]# cd apache-hive-1.2.2-bin/ [root@master apache-hive-1.2.2-bin]# ls bin conf examples hcatalog lib LICENSE NOTICE README.txt RELEASE_NOTES.txt scripts [root@master apache-hive-1.2.2-bin]#
2.2 进入到我们的该目录下的conf目录中,并将文件重命名执行:cp hive-env.sh.template hive-env.sh
[root@master apache-hive-1.2.2-bin]# cd conf/ [root@master conf]# ls beeline-log4j.properties.template hive-env.sh.template hive-log4j.properties.template ivysettings.xml hive-env.sh hive-exec-log4j.properties.template hive-site.xml [root@master conf]#
2.3然后编辑我们的配置文件: vi hive-env.sh
[root@master conf]# vi hive-env.sh
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Set Hive and Hadoop environment variables here. These variables can be used
# to control the execution of Hive. It should be used by admins to configure
# the Hive installation (so that users do not have to set environment variables
# or set command line parameters to get correct behavior).
#
# The hive service being invoked (CLI/HWI etc.) is available via the environment
# variable SERVICE
# Hive Client memory usage can be an issue if a large number of clients
# are running at the same time. The flags below have been useful in
# reducing memory usage:
#
# if [ "$SERVICE" = "cli" ]; then
# if [ -z "$DEBUG" ]; then
# export HADOOP_OPTS="$HADOOP_OPTS -XX:NewRatio=12 -Xms10m -XX:MaxHeapFreeRatio=40 -XX:MinHeapFreeRatio=15 -XX:+UseParNewGC -XX:-UseGCOverhea
dLimit"
# else
# export HADOOP_OPTS="$HADOOP_OPTS -XX:NewRatio=12 -Xms10m -XX:MaxHeapFreeRatio=40 -XX:MinHeapFreeRatio=15 -XX:-UseGCOverheadLimit"
# fi
# fi
# The heap size of the jvm stared by hive shell script can be controlled via:
#
# export HADOOP_HEAPSIZE=1024
#
# The heap size of the jvm stared by hive shell script can be controlled via:
#
# export HADOOP_HEAPSIZE=1024
#
# Larger heap size may be required when running queries over large number of files or partitions.
# By default hive shell scripts use a heap size of 256 (MB). Larger heap size would also be
# appropriate for hive server (hwi etc).
# Set HADOOP_HOME to point to a specific hadoop install directory
# HADOOP_HOME=${bin}/../../hadoop
HADOOP_HOME=/opt/hadoop-2.7.6
# Hive Configuration Directory can be controlled by:
# export HIVE_CONF_DIR=
# Folder containing extra ibraries required for hive compilation/execution can be controlled by:
# export HIVE_AUX_JARS_PATH=
"hive-env.sh" 55L, 2408C

2.4继续咋子hive的配置文件conf中执行:mv hive-default.xml.template hive-site.xml
[root@master conf]# mv hive-site.xml.template hive-site.xml
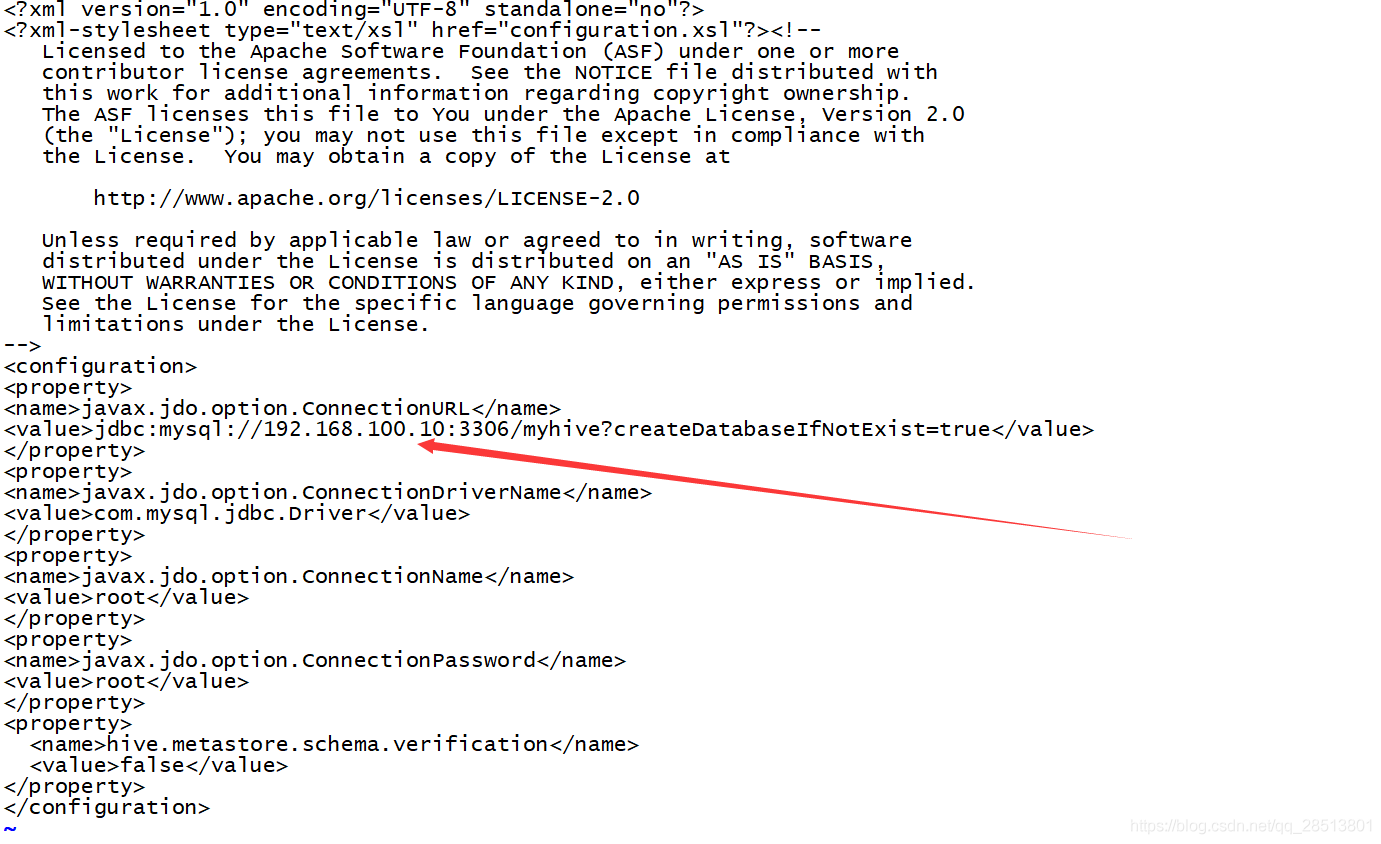
2.5 使用vi编辑我们的hive-site.xml文件
注意:mysql url的路径地址的ip地址根据本机情况进行修改
[root@master conf]# vi hive-site.xml <?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information regarding copyright ownership. The ASF licenses this file to You under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. --> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://192.168.100.10:3306/myhive?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> </property> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> </configuration> ~
2.6 进入到我们的hive的安装目录下,进入到其bin文件下继续修改我们的hive-config.sh 文件
增加内容:
export JAVA_HOME=/opt/jdk1.8.0_171 export HADOOP_HOME=/opt/hadoop-2.7.6 export HIVE_HOME=/opt/apache-hive-1.2.2-bin
参考如下:
[root@master apache-hive-1.2.2-bin]# ls
bin conf examples hcatalog lib LICENSE NOTICE README.txt RELEASE_NOTES.txt scripts
[root@master apache-hive-1.2.2-bin]# cd bin/
[root@master bin]# ls
beeline ext hive hive-config.sh hiveserver2 metatool schematool
[root@master bin]# pwd
/opt/apache-hive-1.2.2-bin/bin
[root@master bin]# vi hive-config.sh
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# processes --config option from command line
#
this="$0"
while [ -h "$this" ]; do
ls=`ls -ld "$this"`
link=`expr "$ls" : '.*-> \(.*\)$'`
if expr "$link" : '.*/.*' > /dev/null; then
this="$link"
else
this=`dirname "$this"`/"$link"
fi
done
# convert relative path to absolute path
bin=`dirname "$this"`
script=`basename "$this"`
bin=`cd "$bin"; pwd`
this="$bin/$script"
# the root of the Hive installation
if [[ -z $HIVE_HOME ]] ; then
export HIVE_HOME=`dirname "$bin"`
fi
#check to see if the conf dir is given as an optional argument
while [ $# -gt 0 ]; do # Until you run out of parameters . . .
case "$1" in
--config)
shift
confdir=$1
shift
HIVE_CONF_DIR=$confdir
;;
--auxpath)
shift
HIVE_AUX_JARS_PATH=$1
shift
;;
*)
break;
;;
esac
done
# Allow alternate conf dir location.
HIVE_CONF_DIR="${HIVE_CONF_DIR:-$HIVE_HOME/conf}"
export HIVE_CONF_DIR=$HIVE_CONF_DIR
export HIVE_AUX_JARS_PATH=$HIVE_AUX_JARS_PATH
# Default to use 256MB
export HADOOP_HEAPSIZE=${HADOOP_HEAPSIZE:-256}
export JAVA_HOME=/opt/jdk1.8.0_171
export HADOOP_HOME=/opt/hadoop-2.7.6
export HIVE_HOME=/opt/apache-hive-1.2.2-bin
2.7然后编辑我们的环境变量/etc/profile,配置hive的环境变量
修改完之后,一定要source /etc/profile使其生效
[root@master bin]# vi /etc/profile
# /etc/profile
# System wide environment and startup programs, for login setup
# Functions and aliases go in /etc/bashrc
# It's NOT a good idea to change this file unless you know what you
# are doing. It's much better to create a custom.sh shell script in
# /etc/profile.d/ to make custom changes to your environment, as this
# will prevent the need for merging in future updates.
pathmunge () {
case ":${PATH}:" in
*:"$1":*)
;;
*)
if [ "$2" = "after" ] ; then
PATH=$PATH:$1
else
PATH=$1:$PATH
fi
esac
}
if [ -x /usr/bin/id ]; then
if [ -z "$EUID" ]; then
# ksh workaround
EUID=`id -u`
UID=`id -ru`
fi
USER="`id -un`"
LOGNAME=$USER
MAIL="/var/spool/mail/$USER"
fi
# Path manipulation
if [ "$EUID" = "0" ]; then
pathmunge /usr/sbin
pathmunge /usr/local/sbin
else
pathmunge /usr/local/sbin after
pathmunge /usr/sbin after
fi
HOSTNAME=`/usr/bin/hostname 2>/dev/null`
HISTSIZE=1000
if [ "$HISTCONTROL" = "ignorespace" ] ; then
export HISTCONTROL=ignoreboth
else
export HISTCONTROL=ignoredups
fi
export PATH USER LOGNAME MAIL HOSTNAME HISTSIZE HISTCONTROL
# By default, we want umask to get set. This sets it for login shell
# Current threshold for system reserved uid/gids is 200
# You could check uidgid reservation validity in
# /usr/share/doc/setup-*/uidgid file
if [ $UID -gt 199 ] && [ "`id -gn`" = "`id -un`" ]; then
umask 002
else
umask 022
fi
for i in /etc/profile.d/*.sh ; do
if [ -r "$i" ]; then
if [ "${-#*i}" != "$-" ]; then
. "$i"
else
. "$i" >/dev/null
fi
fi
done
unset i
unset -f pathmunge
export JAVA_HOME=/opt/jdk1.8.0_171
export HBASE_HOME=/opt/hbase-1.2.12
export HIVE_HOME=/opt/apache-hive-1.2.2-bin
export HADOOP_HOME=/opt/hadoop-2.7.6
export PATH=$JAVA_HOME/bin:$HBASE_HOME/bin:$HIVE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH

2.8 配置环境变量之后,可以执行hive命令 ./hive 进入到hive shell,环境表示安装配置成功。
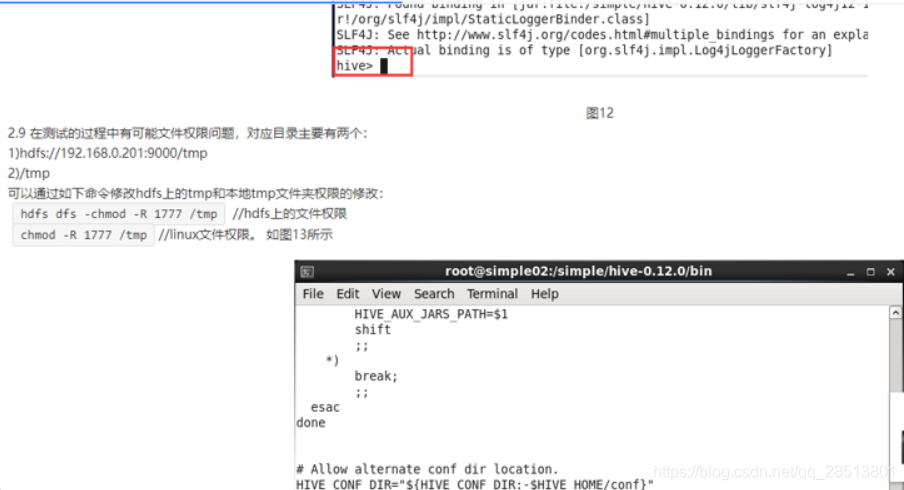
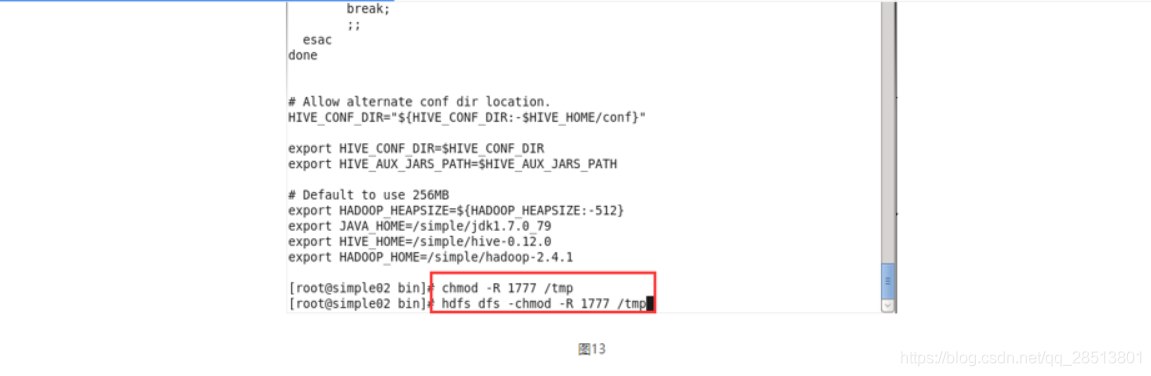
下面是简单运维操作
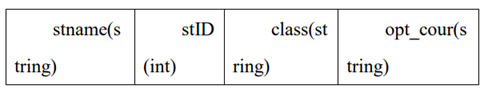
.使用 Hive 工具来创建数据表 xd_phy_course,并定义该表为外部表,外部 存储位置为/1daoyun/data/hive,
将 phy_course_xd.txt 导入到该表中,其中 xd_phy_course 表的数据结构如下表所示。
导入完成后,在 hive 中查询数据表 xd_phy_course 的数据结构信息,
将以上操作命令(相关数据库命令语言请全部 使用小写格式)
和输出结果以文本形式提交到答题框。
从这个表中我们可以看到整个的数据结构,那么首先hive可以采用mapreduce来进行计算, 下面将操作进行基础演示。由于这里是之前做的一例子,数据表的名称和内容可能不太匹配。
备注: 主要是hive表的删除需要先进行disable然后再去drop掉,我这里之前直接进行drop,造成现在无法直接建立和之前相同名的数据表
hive> create external table xd_phy_course_test1 > (stname string,stID int,class string,op_cour string) > row format delimited fields terminated by '\t' > lines terminated by '\n' location '/1daoyun/data/hive' > ; OK Time taken: 0.308 seconds hive> hive> load data local inpath '/usr/hdp/2.6.1.0-129/hbase/phy_course_xd.txt' into table xd_phy_course_test1; Loading data to table default.xd_phy_course_test1 Table default.xd_phy_course_test1 stats: [numFiles=1, totalSize=30] OK Time taken: 0.869 seconds hive> desc xd_phy_course_test1; OK stname string stid int class string op_cour string Time taken: 0.553 seconds, Fetched: 4 row(s) hive>
使用 Hive 工具来统计 phy_course_xd.txt 文件中某高校报名选修各个体育 科目的总人数,其中 phy_course_xd.txt 文件数据结构如下表所示,选修科目字段 为 opt_cour,
将统计的结果导入到表 phy_opt_count 中,通过 SELECT 语句查询 表 phy_opt_count 内容,
将统计语句以及查询命令(相关数据库命令语言请全部 使用小写格式)和输出结果以文本形式提交到答题框。
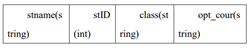
hive> create table xd_phy_course3 > (stname string,stID int,class string,opt_course string) > row format delimited fields terminated by '\t' > lines terminated by '\n' > ; OK Time taken: 2.995 seconds hive> hive> create table phy_opt_count > (opt_cour string,cour_count int) > row format delimited fields terminated by '\t' > lines terminated by '\n' > ; OK Time taken: 0.585 seconds > load data local inpath '/opt/phy_course_xd1.txt' into table xd_phy_course3; Loading data to table default.xd_phy_course3 Table default.xd_phy_course3 stats: [numFiles=2, numRows=0, totalSize=577, rawDataSize=0] OK Time taken: 1.032 seconds hive> hive> select * from phy_opt_count; OK basketball 11 Time taken: 0.124 seconds, Fetched: 1 row(s)
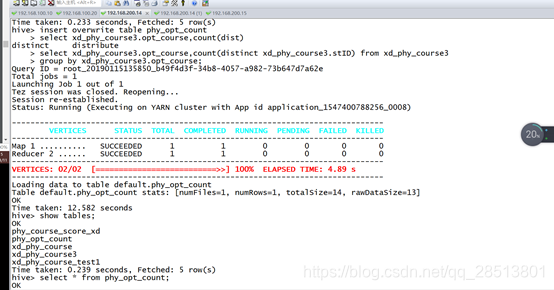
使用 Hive 工具来查找出 phy_course_xd.txt 文件中某高校 Software_1403 班 级报名选修 volleyball 的成员所有信息,其中 phy_course_xd.txt 文件数据结构如 下表所示,选修科目字段为 opt_cour,班级字段为 class,将以上操作命令(相关 数据库命令语言请全部使用小写格式)和输出结果以文本形式提交到答题框.
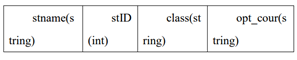
hive> select * from xd_phy_course_test1 where class='www' and op_cour='mmm'; OK Time taken: 0.198 seconds hive>
使用 Hive 工具来统计 phy_course_xd.txt 文件中某高校报名选修各个体育 科目的总人数,其中 phy_course_xd.txt 文件数据结构如下表所示,选修科目字段 为 opt_cour,将统计的结果导入到表 phy_opt_count 中,通过 SELECT 语句查询 表 phy_opt_count 内容,将统计语句以及查询命令(相关数据库命令语言请全部 使用小写格式)和输出结果以文本形式提交到答题框。
hive> create table xd_phy_course3 > (stname string,stID int,class string,opt_course string) > row format delimited fields terminated by '\t' > lines terminated by '\n' > ; OK Time taken: 2.995 seconds hive> hive> create table phy_opt_count > (opt_cour string,cour_count int) > row format delimited fields terminated by '\t' > lines terminated by '\n' > ; OK Time taken: 0.585 seconds > load data local inpath '/opt/phy_course_xd1.txt' into table xd_phy_course3; Loading data to table default.xd_phy_course3 Table default.xd_phy_course3 stats: [numFiles=2, numRows=0, totalSize=577, rawDataSize=0] OK Time taken: 1.032 seconds hive> hive> select * from phy_opt_count; OK basketball 11 Time taken: 0.124 seconds, Fetched: 1 row(s)
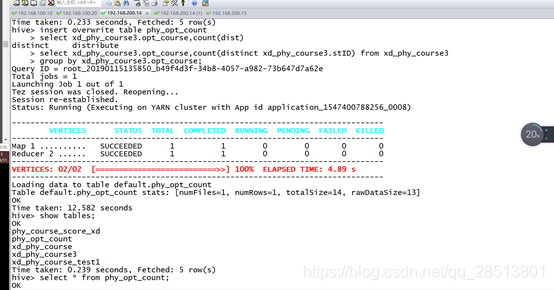
.使用 Hive 工具来查找出 phy_course_score_xd.txt 文件中某高校 Software_1403 班级体育选修成绩在 90 分以上的成员所有信息,其中 phy_course_score_xd.txt 文件数据结构如下表所示,选修科目字段为 opt_cour,成 绩字段为 score,将以上操作命令(相关数据库命令语言请全部使用小写格式) 和输出结果以文本形式提交到答题框。

hive> > create table phy_course_score_xd > (stname string,stID int,class string,opt_cour string,score float) > row format delimited fields terminated by '\t' > lines terminated by '\n' > ; OK Time taken: 0.491 seconds hive> load data local inpath '/opt/phy_course_xd3.txt' into table phy_course_score_xd; Loading data to table default.phy_course_score_xd Table default.phy_course_score_xd stats: [numFiles=1, numRows=0, totalSize=396, rawDataSize=0] OK Time taken: 0.872 seconds hive> select * from phy_course_score_xd; OK wmm 1711040132 oneban basketball 73.0 wmx 1711040133 twoban basketball 90.0 wmc 1711040134 thrban basketball 78.0 wmv 1711040135 fouban basketball 88.0 wmb 1711040136 fivban basketball 95.0 wmr 1711040137 oneban basketball 89.0 wmt 1711040138 twoban basketball 89.0 wmg 1711040130 thrban basketball 89.0 wmh 1711040125 fouban basketball 87.0 wmf 1711040123 fivban basketball 68.0 wmo 1711040156 twoban basketball 45.0 Time taken: 0.092 seconds, Fetched: 11 row(s) hive> select * from phy_course_score_xd where class='oneban' and score>60; OK wmm 1711040132 oneban basketball 73.0 wmr 1711040137 oneban basketball 89.0 Time taken: 0.094 seconds, Fetched: 2 row(s) hive>
使用 Hive 工具来统计 phy_course_score_xd.txt 文件中某高校各个班级体育 课的平均成绩,使用 round 函数保留两位小数。其中 phy_course_score_xd.txt 文 件数据结构如下表所示,班级字段为 class,成绩字段为 score,将以上操作命令 (相关数据库命令语言请全部使用小写格式)和输出结果以文本形式提交到答题 框。

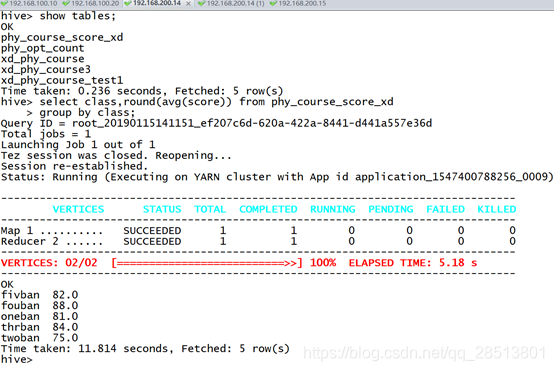
使用 Hive 工具来统计 phy_course_score_xd.txt 文件中某高校各个班级体育 课的最高成绩。其中 phy_course_score_xd.txt 文件数据结构如下表所示,班级字 段为 class,成绩字段为 score,将以上操作命令(相关数据库命令语言请全部使 用小写格式)和输出结果以文本形式提交到答题框。

在 Hive 数据仓库将网络日志 weblog_entries.txt 中分开的 request_date 和 request_time 字段进行合并,并以一个下划线“_”进行分割,如下图所示,其中 weblog_entries.txt 的数据结构如下表所示。将以上操作命令(相关数据库命令语 言请全部使用小写格式)和后十行输出结果以文本形式提交到答题框。

> create table weblog_entries
> (md5 string,url string,request_date string,request_time string,ip string)
> row format delimited fields terminated by '\t'
> lines terminated by '\n'
> ;
OK
Time taken: 0.524 seconds
hive>
hive> load data local inpath '/opt/weblog_entries.txt' into table weblog_entries;
Loading data to table default.weblog_entries
Table default.weblog_entries stats: [numFiles=1, numRows=0, totalSize=840, rawDataSize=0]
OK
Time taken: 1.101 seconds
hive> select * from weblog_entries;
OK
wadadwadwadwadafevfacacac http://example.com/dad 2019-01-11 10:16:32 192.168.200.14
wadaddadadadadafevfacacac http://example.com/dad 2019-01-12 10:13:20 192.168.200.13
wadbghdhdggwadafevfacacac http://example.cn/dadd 2019-01-13 12:29:55 192.168.200.15
bdndndadwadwadafevfacacac http://example.com/hhd 2019-01-14 14:28:20 192.168.200.16
wadadgdgdadwadafevfacacac http://example.com/der 2019-01-15 16:46:24 192.168.200.75
wadadwbbbbdwadafevfacacac http://example.com/yur 2019-01-16 18:21:21 192.168.200.56
wadadwadwadwadafevvsvacac http://example.com/iid 2019-02-17 15:11:36 192.168.200.88
wadadwadwadwadafevfaoooac http://example.com/ood 2019-02-18 14:55:35 192.168.200.67
wadadwadwadwadafevfasssac http://example.com/ppd 2019-02-19 11:33:30 192.168.200.44
wadadwadwadwadafevfacdfac http://example.com/ddd 2019-02-20 17:42:11 192.168.200.33
Time taken: 0.167 seconds, Fetched: 10 row(s)
hive> select concat_ws('_',request_date,request_time)
> from weblog_entries limit 10;
OK
2019-01-11_10:16:32
2019-01-12_10:13:20
2019-01-13_12:29:55
2019-01-14_14:28:20
2019-01-15_16:46:24
2019-01-16_18:21:21
2019-02-17_15:11:36
2019-02-18_14:55:35
2019-02-19_11:33:30
2019-02-20_17:42:11
Time taken: 0.161 seconds, Fetched: 10 row(s)
hive>
.使用 Hive 动态地关于网络日志 weblog_entries.txt 的查询结果创建 Hive 表。通过创建一张名为 weblog_entries_url_length 的新表来定义新的网络日志数 据库的三个字段,分别是 url,request_date,request_time。此外,在表中定义一 个获取 url 字符串长度名为“url_length”的新字段,其中 weblog_entries.txt 的数据 结构如下表所示。完成后查询 weblog_entries_url_length 表文件内容,将以上操 作命令(相关数据库命令语言请全部使用小写格式)和后十行输出结果以文本形 式提交到答题框。

- linux 基本操作以及搭建Java开发环境
- redis集群环境搭建以及java中jedis客户端集群代码实现
- redis集群环境搭建以及java中jedis客户端集群代码实现 博客分类: redis
- java-jdbc操作详细代码分享
- Spark+ECLIPSE+JAVA+MAVEN windows开发环境搭建及入门实例【附详细代码】
- redis集群环境搭建以及java中jedis客户端集群代码实现
- Java操作HDFS开发环境搭建以及HDFS的读写流程
- mac os 利用ssh 搭建git server服务器详细教程,以及git基本用法
- 【Java】利用单例模式、可变参数优化Java操作Mysql数据库、JDBC代码的写作
- 从svn签下代码以及集成开发环境的搭建详细过程
- redis集群环境搭建以及java中jedis客户端集群代码实现
- Hive基本环境搭建(附赠Java和Hadoop的环境搭建)
- redis集群环境搭建以及java中jedis客户端集群代码实现
- mac os 利用ssh 搭建git server服务器详细教程,以及git基本用法(上)
- redis集群环境搭建以及java中jedis客户端集群代码实现
- mac os 利用ssh 搭建git server服务器详细教程,以及git基本用法(下)
- mac os 利用ssh 搭建git server服务器详细教程,以及git基本用法(上)
- linux命令基本操作以及Java的安装与环境的配置
- Spark+ECLIPSE+JAVA+MAVEN windows开发环境搭建及入门实例【附详细代码】
- redis集群环境搭建以及java中jedis客户端集群代码实现 博客分类: redis