mapreduce——实现网站PV排序两种思路
业务需求:
1.统计request.dat中每个页面被访问的总次数,同时,要求输出结果文件中的数据按照次数大小倒序排序 2.统计request.dat中每个页面被访问的总次数,同时,要求输出结果文件中的数据top5
任务一:使用两个mapreduce分开计算
流程图
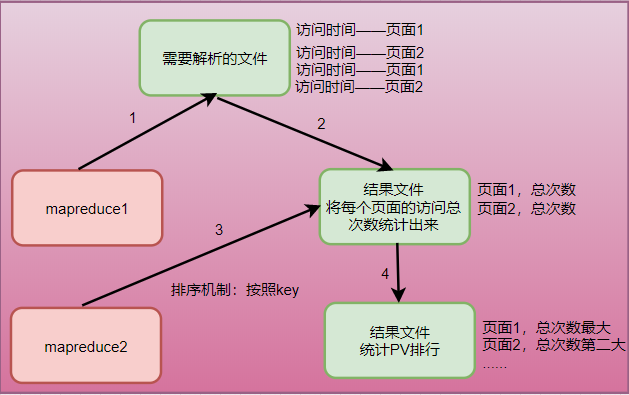
关键技术点:
mapreduce程序内置了一个排序机制:
map work和reduce work,都会对数据按照key的大小来排序
所以最终的输出结果中,一定是按照key有顺序的结果
思路:
本案例中,就可以利用这个机制来实现需求:
1.先写一个mapreduce程序,将每个页面的访问总次数统计出来
2.再写第二个mapreduce程序:
map阶段:读取第一个mapreduce产生的结果文件,将每一条数据解析成一个Java对象URLCountBean(封装一个URL和它的总次数),然后将这个对象作为key,null作为value返回。
要点:这个Java对象要实现WritableComparable接口,以让worker可以调用对象的compareTo方法来实现排序。
reduce阶段:由于worker已经对收到的数据按照URLCountBean的compareTo方法排序,所以,在reduce方法中,只要将数据输出即可,最后的结果自然是按照总次数大小的有序结果。
测试数据:访问日期+网站
2019/05/29 qq.com/a 2019/05/29 qq.com/bx 2019/05/29 qq.com/by 2019/05/29 qq.com/by3 2019/05/29 qq.com/news 2019/05/29 sina.com/news/socail 2019/05/29 163.com/ac 2019/05/29 sina.com/news/socail 2019/05/29 163.com/sport 2019/05/29 163.com/ac 2019/05/29 sina.com/play 2019/05/29 163.com/sport 2019/05/29 163.com/ac 2019/05/29 sina.com/movie 2019/05/29 sina.com/play 2019/05/29 sina.com/movie 2019/05/29 163.com/sport 2019/05/29 sina.com/movie 2019/05/29 163.com/ac 2019/05/29 163.com/ac 2019/05/29 163.com/acc 2019/05/29 qq.com/by 2019/05/29 qq.com/by3 2019/05/29 qq.com/news 2019/05/29 163.com/sport 2019/05/29 sina.com/news/socail 2019/05/29 163.com/sport 2019/05/29 sina.com/movie 2019/05/29 sina.com/news/socail 2019/05/29 sina.com/movie 2019/05/29 qq.com/news 2019/05/29 163.com/bb 2019/05/29 163.com/cc 2019/05/29 sina.com/lady/ 2019/05/29 163.com/cc 2019/05/29 qq.com/news 2019/05/29 qq.com/by 2019/05/29 qq.com/by3 2019/05/29 sina.com/lady/ 2019/05/29 qq.com/by3 2019/05/29 sina.com/lady/ 2019/05/29 qq.com/by3 2019/05/29 qq.com/news 2019/05/29 qq.com/by3 2019/05/29 163.com/sport 2019/05/29 163.com/sport 2019/05/29 sina.com/news/socail 2019/05/29 sina.com/lady/ 2019/05/29 sina.com/play 2019/05/29 sina.com/movie 2019/05/29 sina.com/music 2019/05/29 sina.com/sport 2019/05/29 sina.com/sport 2019/05/29 163.com/sport 2019/05/29 sina.com/news/socail 2019/05/29 sohu.com/lady/ 2019/05/29 sohu.com/play 2019/05/29 sohu.com/movie 2019/05/29 sohu.com/music 2019/05/29 sohu.com/sport 2019/05/29 sohu.com/sport 2019/05/29 sina.com/news/socail 2019/05/29 baidu.com/lady/ 2019/05/29 baidu.com/play 2019/05/29 baidu.com/movie 2019/05/29 baidu.com/music 2019/05/29 baidu.com/movie 2019/05/29 baidu.com/music 2019/05/29 baidu.com/movie 2019/05/29 baidu.com/music 2019/05/29 baidu.com/movie 2019/05/29 baidu.com/music 2019/05/29 baidu.com/movie 2019/05/29 baidu.com/music 2019/05/29 baidu.com/music 2019/05/29 baidu.com/movie 2019/05/29 baidu.com/music 2019/05/29 baidu.com/sport 2019/05/29 baidu.com/sport
编写代码实现
PageCount 序列化
public class PageCount implements WritableComparable<PageCount> {
private String page;
private int count;
public void set(String page, int count) {
this.page = page;
this.count = count;
}
public String getPage() {
return page;
}
public void setPage(String page) {
this.page = page;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
public int compareTo(PageCount o) {
return o.getCount()-this.count==0
?this.page.compareTo(o.getPage())
:o.getCount()-this.count;
}
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(this.page);
dataOutput.writeInt(this.count);
}
public void readFields(DataInput dataInput) throws IOException {
this.page=dataInput.readUTF();
this.count=dataInput.readInt();
}
@Override
public String toString() {
return "PageCount{" +
"page='" + page + '\'' +
", count=" + count +
'}';
}
}
1.先写一个mapreduce程序,将每个页面的访问总次数统计出来
public class PageCountStep1 {
public static class PageCountStep1Mapper extends Mapper<LongWritable,Text,Text,IntWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line=value.toString();
String[] split=line.split(" ");
context.write(new Text(split[1]),new IntWritable(1));
}
}
public static class PageCountStep1Reduce extends Reducer<Text,IntWritable,Text,IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count=0;
for(IntWritable v:values){
count+=v.get();
}
context.write(key,new IntWritable(count));
}
}
public static void main(String[] args)throws Exception {
//加载配置文件
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(PageCountStep1.class);
job.setMapperClass(PageCountStep1Mapper.class);
job.setReducerClass(PageCountStep1Reduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("f:/mrdata/url/input"));
FileOutputFormat.setOutputPath(job, new Path("f:/mrdata/url/outputout"));
boolean res = job.waitForCompletion(true);
System.exit(res?0:1);
}
}
2.再写第二个mapreduce程序对结果进行排序
public class PageCountStep2 {
public static class PageCountStep2Mapper extends Mapper<LongWritable,Text,PageCount,NullWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("\t");
PageCount pageCount = new PageCount();
pageCount.set(split[0],Integer.parseInt(split[1]));
context.write(pageCount,NullWritable.get());
}
}
public static class PageCountStep2Reduce extends Reducer<PageCount,NullWritable,PageCount,NullWritable>{
@Override
protected void reduce(PageCount key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
public static void main(String[] args)throws Exception {
//加载配置文件
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(PageCountStep1.class);
job.setMapperClass(PageCountStep2Mapper.class);
job.setReducerClass(PageCountStep2Reduce.class);
job.setMapOutputKeyClass(PageCount.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(PageCount.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path("f:/mrdata/url/outputout"));
FileOutputFormat.setOutputPath(job, new Path("f:/mrdata/url/sortout"));
boolean res = job.waitForCompletion(true);
System.exit(res?0:1);
}
}
输出结果
1.将每个页面的访问总次数统计出来
163.com/ac 5 163.com/acc 1 163.com/bb 1 163.com/cc 2 163.com/sport 8 baidu.com/lady/ 1 baidu.com/movie 6 baidu.com/music 7 baidu.com/play 1 baidu.com/sport 2 qq.com/a 1 qq.com/bx 1 qq.com/by 3 qq.com/by3 6 qq.com/news 5 sina.com/lady/ 4 sina.com/movie 6 sina.com/music 1 sina.com/news/socail 7 sina.com/play 3 sina.com/sport 2 sohu.com/lady/ 1 sohu.com/movie 1 sohu.com/music 1 sohu.com/play 1 sohu.com/sport 2
2.对结果进行排序输出
PageCount{page='163.com/sport', count=8}
PageCount{page='baidu.com/music', count=7}
PageCount{page='sina.com/news/socail', count=7}
PageCount{page='baidu.com/movie', count=6}
PageCount{page='qq.com/by3', count=6}
PageCount{page='sina.com/movie', count=6}
PageCount{page='163.com/ac', count=5}
PageCount{page='qq.com/news', count=5}
PageCount{page='sina.com/lady/', count=4}
PageCount{page='qq.com/by', count=3}
PageCount{page='sina.com/play', count=3}
PageCount{page='163.com/cc', count=2}
PageCount{page='baidu.com/sport', count=2}
PageCount{page='sina.com/sport', count=2}
PageCount{page='sohu.com/sport', count=2}
PageCount{page='163.com/acc', count=1}
PageCount{page='163.com/bb', count=1}
PageCount{page='baidu.com/lady/', count=1}
PageCount{page='baidu.com/play', count=1}
PageCount{page='qq.com/a', count=1}
PageCount{page='qq.com/bx', count=1}
PageCount{page='sina.com/music', count=1}
PageCount{page='sohu.com/lady/', count=1}
PageCount{page='sohu.com/movie', count=1}
PageCount{page='sohu.com/music', count=1}
PageCount{page='sohu.com/play', count=1}
任务二:使用两个map缓存来充当中间件,做计数使用,适合数据量小的场景使用
分析图
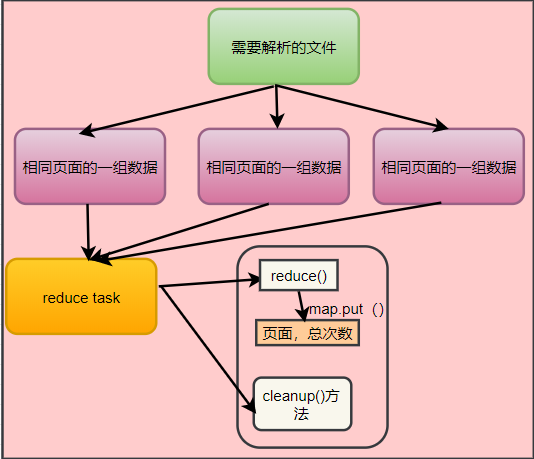
PageCount对象实体
public class PageCount implements Comparable<PageCount>{
private String page;
private int count;
public void set(String page, int count) {
this.page = page;
this.count = count;
}
public String getPage() {
return page;
}
public void setPage(String page) {
this.page = page;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
public int compareTo(PageCount o) {
return o.getCount()-this.count==0
?this.page.compareTo(o.getPage())
:o.getCount()-this.count;
}
}
PageTopMapper:读取数据
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class PageTopMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] split = line.split(" ");
context.write(new Text(split[1]),new IntWritable(1));
}
}
PageTopReducer:对数据进行分析统计
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
public class PageTopReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
TreeMap<PageCount,Object>treeMap=new TreeMap<PageCount, Object>();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count =0;
for(IntWritable value :values){
count +=value.get();
}
PageCount pageCount = new PageCount();
pageCount.set(key.toString(),count);
treeMap.put(pageCount,null);
}
/**
* 所有数据处理完调用
*/
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
Configuration conf = context.getConfiguration();
int top = conf.getInt("top.n", 5);
Set<Map.Entry<PageCount, Object>> entrySet = treeMap.entrySet();
int i=0;
for (Map.Entry<PageCount,Object> entry:entrySet) {
context.write(new Text(entry.getKey().getPage()),new IntWritable(entry.getKey().getCount()));
i++;
//取到排名前n条
if(i==top) return;
}
}
}
JobSubmitter:启动程序
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.util.Properties;
public class JobSubmitter {
public static void main(String[] args) throws Exception{
//加载配置文件
Configuration conf = new Configuration();
//1.直接给定
//conf.setInt("top.n",3);
//2.main方法传参数
//conf.setInt("top.n",Integer.parseInt(args[0]));
//3.通过配置文件
Properties props = new Properties();
props.load(JobSubmitter.class.getClassLoader().
getResourceAsStream("topn.properties"));
conf.setInt("top.n",Integer.parseInt(props.getProperty("top.n")));
//4.xml形式,直接配置,默认加载
Job job = Job.getInstance(conf);
job.setJarByClass(JobSubmitter.class);
job.setMapperClass(PageTopMapper.class);
job.setReducerClass(PageTopReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("f:/mrdata/url/input"));
FileOutputFormat.setOutputPath(job, new Path("f:/mrdata/url/output"));
//job.setNumReduceTasks(3);
boolean res = job.waitForCompletion(true);
System.exit(res?0:1);
}
}
统计结果输出:top5
(adsbygoogle = window.adsbygoogle || []).push({});163.com/sport 8
baidu.com/music 7
sina.com/news/socail 7
baidu.com/movie 6
qq.com/by3 6

- 二分法两种排序方式思路及实现
- 快速排序的两种实现思路和非递归实现--C++实现
- 详谈排序算法之插入类排序(两种思路实现希尔排序)
- 详谈排序算法之交换类排序(两种方法实现快速排序【思路一致】)
- 大型PHP电商网站商品秒杀功能实现思路分析
- 网站性能优化:动态缩略图技术实现思路
- C语言 实现两种排序方法
- MapReduce实现自定义二次排序
- 2017年2月8号 数据统计单位转换(两种实现思路)
- Java编程之TreeSet排序两种解决方法(1)元素自身具备比较功能,元素需要实现Comparable接口覆盖compare(2)创建根据自定义Person类的name进行排序的Comparator
- PageRank_网页排名_MapReduceJava代码实现思路
- mapreduce实现排序并且找出销量最多的数据
- 商城类网站购物车的实现思路
- 【hadoop】大规模中文网站聚类kmeans的mapreduce实现(下)
- 多语言网站生成静态页面实现思路以及用freemarker作模板生成静态页面的实现
- 网站单点登录的实现思路
- (hadoop学习-1)mapreduce实现数据过滤、聚合与排序
- MapReduce实现排序功能
- MapReduce框架中矩阵相乘的算法思路及其实现
- 快速排序的两种实现