Hetian lab day 5 Python标准库之数据结构与文本处理(待更)
2019-05-25 16:04
1576 查看
版权声明:转载请注明 https://blog.csdn.net/qq_38834590/article/details/90547977
span() 返回一个元组包含匹配 (开始,结束) 的位置.
findall,在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次 findall 匹配所有。
文章目录
Part 1 Python标准库之数据结构与文本处理课后题

【解析】search()和match()均用于扫描匹配字符串。match()函数只检测RE是不是在string的开始位置匹配, search()会扫描整个string查找匹配, 也就是说match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回none。
group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
语法格式:
findall(string[, pos[, endpos]])
参数:
string : 待匹配的字符串。
pos : 可选参数,指定字符串的起始位置,默认为 0。
endpos : 可选参数,指定字符串的结束位置,默认为字符串的长度。

【解析】
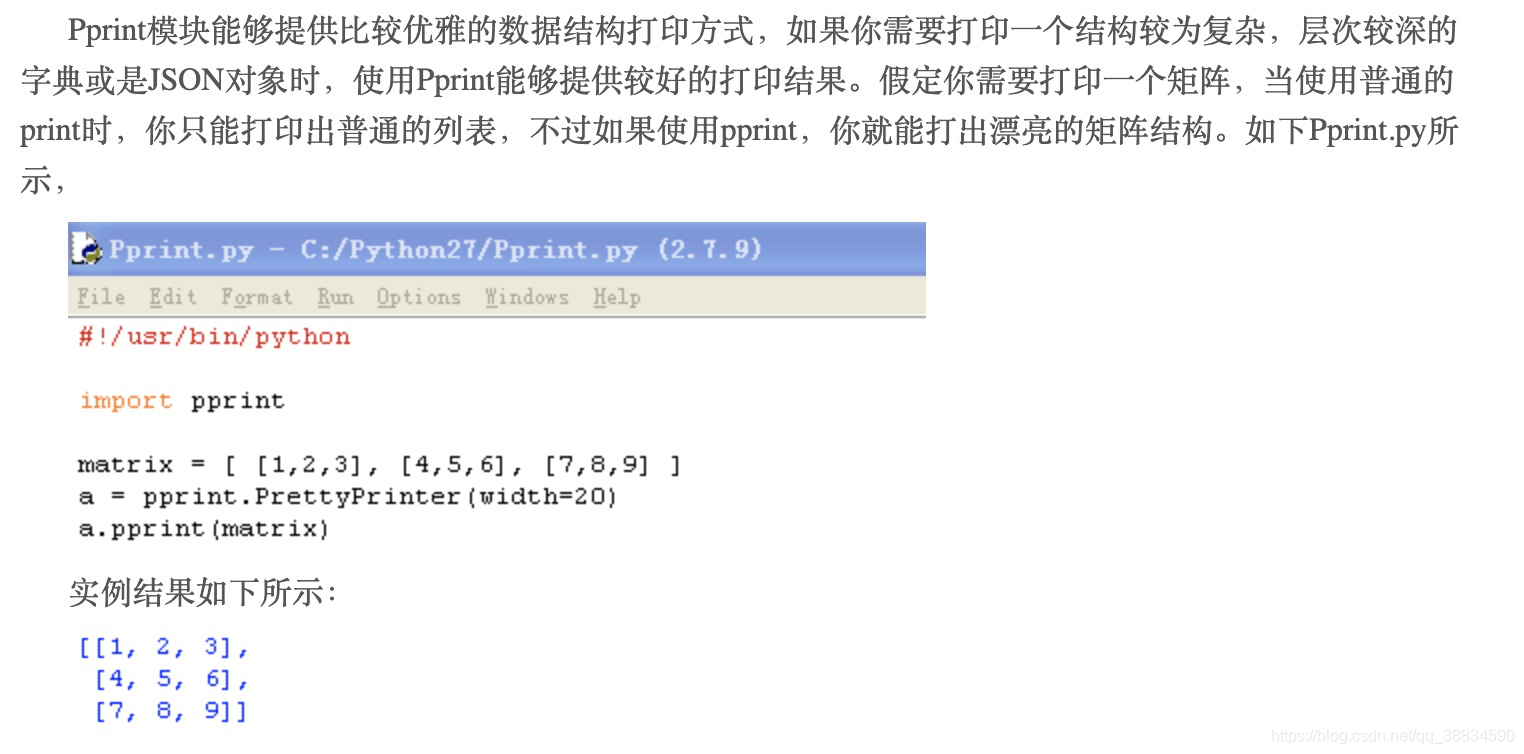
Part 2 实验操作
Part 3 分析与思考
1) Python的string类提供了对字符串进行处理的方法。更进一步,通过标准库中的re包,Python可以用正则表达式(regular expression)来处理字符串。正则表达式是一个字符串模板。Python可以从字符中搜查符合该模板的部分,或者对这一部分替换成其它内容。比如你可以搜索一个文本中所有的数字。正则表达式的关键在于根据自己的需要构成模板。此外,Python标准库还为字符串的输出提供更加丰富的格式, 比如: string包,textwrap包。
2)python中深拷贝和浅拷贝的区别?

相关文章推荐
- Python语言和标准库(第七章:文本处理)
- [Python标准库]pprint——美观打印数据结构
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器库
- Python文本数据分析与处理
- 文本处理(python)
- win10上用Python2.7处理文本,出错IOError: [Errno 2] No such file or directory:如何解决???
- 用python处理文本,本地文件系统以及使用数据库的知识基础
- 可爱的 Python:Python 中的文本处理
- 在Python中使用LDA处理文本
- Python处理文本换行符实例代码
- python+NLTK 自然语言学习处理四:获取文本语料和词汇资源
- python文本处理.python版本2.7.3
- python3-cookbook中一些关于字符串和文本的处理方式
- Python标准库学习笔记-文本
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱
- python处理文本例子1
- Python之mmap内存映射模块(大文本处理)说
- python字符串与文本处理技巧(4): 格式化输出、令牌解析、串上串