Tree、B_Tree,B+_Tree及Mysql索引实现浅析
Tree:
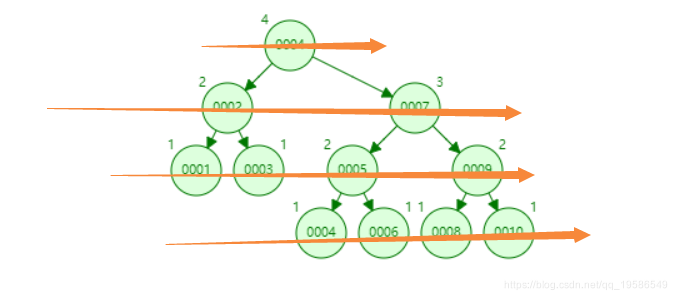
这是一个平衡二叉树,以1~10内容为例,我们可以看到它一共有4级,我们查询10的话需要进行四次查询。如果作为数据库索引实现的话需要进行4次IO读取。
这是平衡二叉树的演示工具网址:https://www.cs.usfca.edu/~galles/visualization/AVLtree.html
B树:
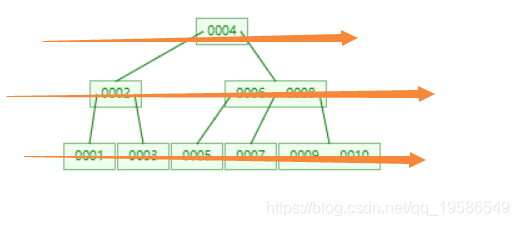
这是一个B-tree ,同样以1~10为例子,它一共有3级,我们查询10的话需要进行3次查询。如果作为数据库索引实现的话需要进行3次IO读取。相比较平衡树来说,在某些情况下我们可以减少对于IO的读取次数。相对于平衡树来说我们查找某个内容的速度变快了,但是怎么用一个数的索引模式去实现范围查询呢?例如我们查询7 ~10的范围,需要找到7往回退然后再往右找10,这样是很麻烦的,我们知道范围查询性能最快的是有序数组。可以很快的取到7 ~10的内容,但是数组的单个内容查询效率比较低(虽然可以使用二分查找,类似于平衡树实现,但是我们想让他的效率更高点)。下面我们就介绍一下B-Tree和数组的结合体,B+Tree
[1,2,3,4,5,6,7,8,9,10]
这是B-tree的演示地址:https://www.cs.usfca.edu/~galles/visualization/BTree.html
B+树:
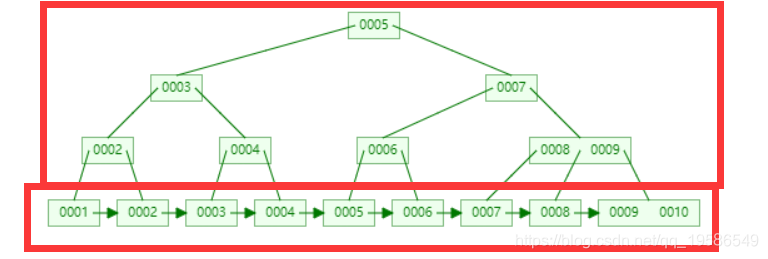
B+树相对于B树增加了叶子节点概念,分为叶子节点和非叶子节点,叶子节点是Key-Value形式的数组结构,非叶子节点是个B树,这样就能提高单个查询和范围查询的效率,相对应的肯定会多占用一些空间,这对我们来说是可以接受的。MySQL中的InnoDB和MyISAM就是采用了B+树的方式实现的索引。但是两者在实现方式上稍有不同:
B+树的演示页面:https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
MyISAM:
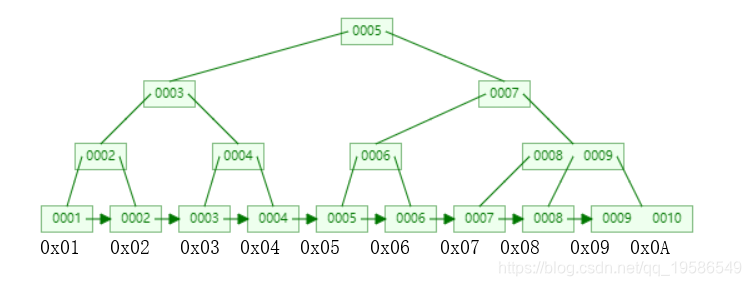
MyISAM 的叶子节点的value对应的是地址,当查询的时候还需要根据地址去寻找对应的值。
InnoDB :
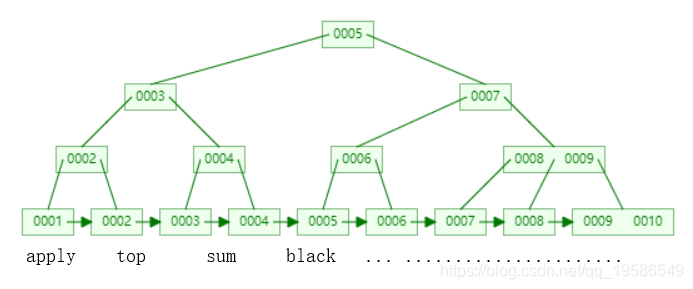
InnoDB中叶子节点的value直接存储的内容。
当然这只是两种存储引擎索引的区别,MyISAM和InnoDB的主要区别有朋友已经总结了:
https://www.geek-share.com/detail/2679916942.html

- 以B tree和B+ tree的区别来分析mysql索引实现
- MySQL中MyISAM和InnoDB对B-Tree索引不同的实现方式
- Mysql-TREE实现
- 关于mysql b-tree索引的一点认知
- MySql中B-Tree索引和Hash索引
- mysql hash 索引 vs B-TREE 索引 理解
- mysql索引的实现数据结构(B-树)
- 2014阿里实习生面试题——mysql如何实现索引的
- MySQL索引的B+Tree查找原理
- 数据库为什么要用B+树结构--MySQL索引结构的实现
- 基于Solr DIH实现MySQL表数据全量索引和增量索引
- 高性能的MySQL(5)创建高性能的索引一B-Tree索引
- 大数据——ubuntu下Nutch 2.2+MySQL实现网站内容的抓取和索引(下集)
- Mysql索引是如何实现的
- MySQL B-Tree索引
- 【转】MySQL中B+Tree索引原理
- MySQL中两种索引Hash与B-Tree的区别
- centos sphinx mysql安装配置sphinxse及全文索引的简单实现
- 自己实现mysql “函数索引”
- MySQL索引使用的数据结构:B-Tree和B+Tree