论文解读《Automatic Text Scoring Using Neural Networks》
论文使用用C&W Embedding及LSTM作为基础,提出了新的文本自动评分模型,取得了好的效果。
具体如下:
为什么要搞出一个SSWES Augmented C&W model?
-C&W Embeddings
在NNLM之后,在CBOW和skip-gram之前,2008年Collobert和Weston 提出的C&W模型不再利用语言模型的结构,而是将目标文本片段整体当做输入,然后预测这个片段是真实文本的概率,所以它的工作主要是改变了目标输出,由于输出只是一个概率大小,不再是词典大小,因此训练效率大大提升,但也由于使用了这种目标输出,使得它的词向量表征能力有限。
和NNLM一样,输入向量经过一个tanh,后计算网络函数
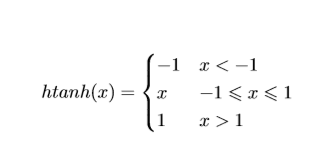

损失函数为hinge loss,使向量中的噪声最小:
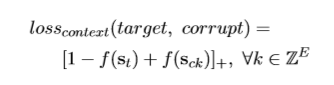
-SSWES
SSWES Augmented C&W model 的核心思想:
1、每个词对文章得分的贡献是不一样的,像is, are, to, 这种对在得分高的文章和得分低的文章中都会出现。
2、信息词汇是那些会影响论文分数的词汇(例如,拼写错误)
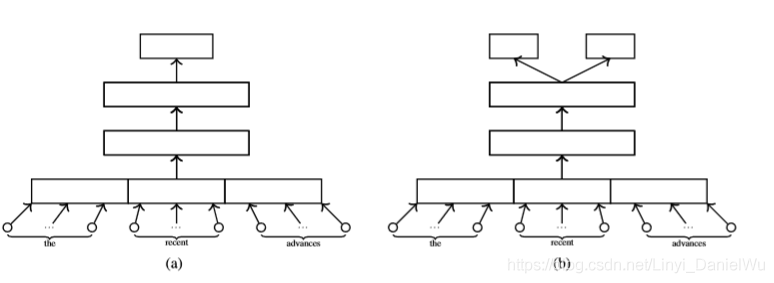
为了获得嵌入词的分数,在输出层加入一层线性回归:如下图,由a变为b
从(计算出整体损失函数作为两个损失函数的加权线性组合,将误差梯度反向传播到嵌入矩阵m。
 ,
,
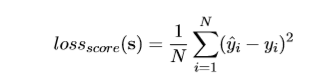

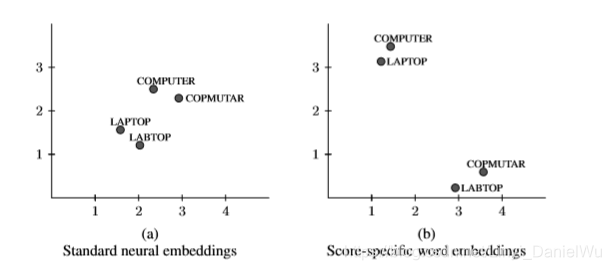
改进后的算法可以将正确拼写的单词在向量空间中与错误拼写的单词分开,但是保留了词的下文相关的信息。
如下图,b相较于a不仅保留了computer与laptop两个词的相似性,还可以在分数上将两组词分开。
实验
作者使用了Kaggle数据集去验证该改进的算法,内容为7-10年级学生的作文,共12976篇文章,每篇150到550个单词。
其结果如下

可见在不同的模型上,sswe均优于其他方法。

- 论文提要“Scalable Object Detection using Deep Neural Networks”
- 论文摘要: Multi-view Face Detection Using Deep Convolutional Neural Networks
- [论文解读] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- Deep Learning 论文解读——Session-based Recommendations with Recurrent Neural Networks
- 论文《Recurrent Convolutional Neural Networks for Text Classification》总结
- 论文总结 - Image Style Transfer Using Convolutional Neural Networks
- 论文笔记(2)-Dropout-Regularization of Neural Networks using DropConnect
- 论文笔记(一)Radio frequency interference mitigation using deep convolutional neural networks
- 论文解读Attribute-Enhanced Face Recognition with Neural Tensor Fusion Networks
- 论文阅读:Reading Text in the Wild with Convolutional Neural Networks
- 论文阅读:Learning and Transferring Mid-Level Image Representations using Convolutional Neural Networks
- Automatic Photo Adjustment Using Deep Neural Networks
- 【论文笔记】Scalable Object Detection using Deep Neural Networks
- 论文阅读:Reading Text in the Wild with Convolutional Neural Networks
- 《image Style Transfer Using Convolutional Neural Networks》论文笔记
- Convolutional Neural Networks for Sentence Classification论文解读
- XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks
- [论文解读] MSCNN: A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
- 论文读书笔记-Using neural network to combine measures of word semantic similarity for image annotation
- 【论文笔记2】图像压缩神经网络在Kodak数据集上首次超越JPEG——Full Resolution Image Compression with Recurrent Neural Networks