shell编程之awk常用参数、变量、函数详解
awk是一个优良的文本处理工具,Linux及UNIX环境中现有的功能最强大的数据处理引擎之一,以Aho、Weinberger、Kernighan三位发明者名字首字母命名为awk,awk是一个行级文本高效处理工具,awk经过改进生成的新的版本有nawk、gawk,一般Linux默认为gawk,gawk是awk的GNU开源免费版本。
awk基本原理是逐行处理文件中的数据,查找与命令行中所给定内容相匹配的模式,如果发现匹配内容,则进行下一个编程步骤,如果找不到匹配内容,则继续处理下一行。其语法参数格式如下:
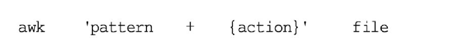
awk常用参数、变量、函数详解如下
(1)awk基本语法参数详解如下:
•□单引号’'是为了和shell命令区分开。
•□大括号{}表示一个命令分组。
•□pattern是一个过滤器,表示匹配pattern条件的行才进行action处理。
□action是处理动作,常见动作为print。
•□使用#作为注释,pattern和action可以只有其一,但不能两者都没有。
常用命令选项
-F fs fs指定输入分隔符,fs可以是字符串或正则表达式,如-F:
-v var=value 赋值一个用户定义变量,将外部变量传递给awk
-f scripfile 从脚本文件中读取awk命令
-m[fr] val 对val值设置内在限制,-mf选项限制分配给val的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。
(2)awk内置变量详解如下:
•□ FS:分隔符,默认是空格。
•□ OFS:输出分隔符。
•□ NR:当前行数,从1开始。
•□ NF:当前记录字段个数。
•□ $0:当前记录。
•□ $1~$n:当前记录第n个字段(列)。
(3)awk内置函数详解如下:
•□ gsub(r,s):在$0中用s代替r。
•□ index(s,t):返回s中t的第一个位置。
•□ length(s):s的长度。
•□ match(s,r):s是否匹配r。
•□ split(s,a,fs):在fs上将s分成序列a。
•□ substr(s,p):返回s从p开始的子串。
(4)awk常用操作符、运算符及判断符,详解如下:
•□ ++--:增加与减少(前置或后置)。
•□ ^∗∗:指数(右结合性)。
•□ !+-:非、一元(unary)加号、一元减号。
•□ +-∗/%:加、减、乘、除、余数。
•□ ===!==:数字比较。
•□ &&:逻辑and。
□ ‖:逻辑or。
•□ =+=-=∗=/=%=^=∗∗=:赋值。
(5)awk与流程控制语句如下:
•□ if(condition){}else{};
•□ while{};
•□ do{}while(condition);
•□ for(init;condition;step){};
•□ break/continue。
(6)BEGIN 和 END 模块
通常,对于每个输入行,awk 都会执行每个脚本代码块一次。然而,在许多编程情况中, 可能需要在 awk 开始处理输入文件中的文本之前执行初始化代码。对于这种情况,awk 允许 您定义一个 BEGIN 块。我们在前一个示例中使用了 BEGIN 块。因为 awk 在开始处理输入文件之前会执行 BEGIN 块,因此它是初始化 FS(字段分隔符)变量、打印页眉或初始化其它 在程序中以后会引用的全局变量的极佳位置。
awk 还提供了另一个特殊块,叫作 END 块。awk 在处理了输入文件中的所有行之后执行 这个块。通常,END 块用于执行最终计算或打印应该出现在输出流结尾的摘要信息。
BEGIN{}: 读入第一行文本之前执行的语句,一般用来初始化操作
{}: 逐行处理
END{}: 处理完最后以行文本后执行,一般用来处理输出结果
实例:
文件开头加REDHAT,末尾加WESTOS,打印行号和内容
[root@localhost]# awk -F: 'BEGIN {print "REDHAT"} {print NR;print} END {print "WESTOS"}' passwd
统计文本总字段个数
[root@server19 mnt]# awk 'BEGIN{i=0}{i+=NF}END{print i}' test.txt

- awk常用参数、变量、函数详解
- awk与shell参数传递(或说变量传递)二三点
- shell编程之变量详解
- 详解Shell编程之变量数值计算(一)
- shell--特殊位置参数变量及常用内置变量
- readonly命令_Linux readonly 命令用法详解:定义只读shell变量或函数
- Shell 编程详解之变量<二>
- Linux 网络编程常用函数详解
- shell的一些常用的语句(if语句,变量,for、while、until语句、函数调用、脚本调用)
- shell脚本程序中的部分常用环境变量和参数变量的说明以及简单shell脚本示例
- const 详解(修饰变量、输入参数、返回值、成员函数)
- 如何向awk中传递shell变量参数
- 70个shell常用操作、 shell编程控制结构:expr、let、for、while、until、shift、if、case、break、continue、函数、select
- socket编程常用函数及参数
- unset命令_Linux unset 命令用法详解:删除指定的shell变量或函数
- shell脚本之正则表达式、函数、grep、sed、awk、printf等基本命令配置详解
- zookeeper入门(3)API常用函数功能与参数详解
- linux unset命令参数及用法详解--linux删除自定义变量或函数
- 详解shell脚本(九)——awk命令编程
- python codecs模块 及几个常用函数参数详解