Python +tensorflow+pygame 破解任意字体反爬
什么是字体反爬?
每个字符在 都可以用 unicode 编码表示 而字体文件可以理解为Unicode 和 字体形状的映射 ,所以在计算机中字符可以变成我们人类所能理解的形状,所以字体反爬的关键就是字体文件,因为它决定了将Unicode字符渲染成什么形状(字)
1.解析反爬效果
这里我们拿猫眼为例:
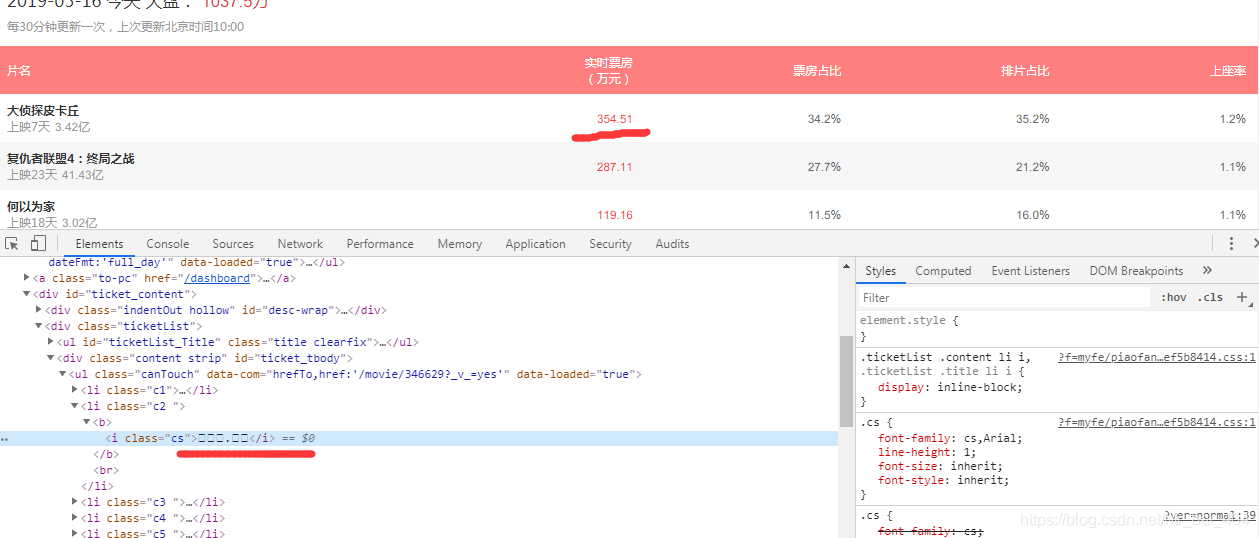

第二图可见,猫眼将数字进行了反爬,&#x 表示16进制 ,e309 表示Unicode 的值,第一幅图中可见,浏览器字体文件渲染的效果和默认渲染的效果,爬虫只能抓到̉这种原始Unicode 或默认渲染的 . , 而真实的数字就需要字体文件了。
2.字体文件获取

从上图可以看到,两个箭头之间就是字体文件了,我们只需将其保存至本地即可
[code]import base64
font_face='d09GRgABAAAAAAggAAsAAAAAC7gAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAABHU1VCAAABCAAAADMAAABCsP6z7U9TLzIAAAE8AAAARAAAAFZW7ldeY21hcAAAAYAAAAC8AAACTC79iqhnbHlmAAACPAAAA5EAAAQ0l9+jTWhlYWQAAAXQAAAALwAAADYVJRd8aGhlYQAABgAAAAAcAAAAJAeKAzlobXR4AAAGHAAAABIAAAAwGhwAAGxvY2EAAAYwAAAAGgAAABoGmAWgbWF4cAAABkwAAAAfAAAAIAEZADxuYW1lAAAGbAAAAVcAAAKFkAhoC3Bvc3QAAAfEAAAAXAAAAI8LScOueJxjYGRgYOBikGPQYWB0cfMJYeBgYGGAAJAMY05meiJQDMoDyrGAaQ4gZoOIAgCKIwNPAHicY2Bk0mWcwMDKwMHUyXSGgYGhH0IzvmYwYuRgYGBiYGVmwAoC0lxTGBwYKr4/Z9b5r8MQw6zDcAUozAiSAwDoeQvweJzFkrENg0AMRf8FQgKkSJkhsgM1EhKDsAATpKLMFJSpMgcjAOIKKJAoKMm/M00kaBOf3kn+PtmWfQCOABxyJy6g3lAw9qKqrO4gsLqLB/0brlTOyOuq8dusS3TRx0M0plM562Xhi/3Ililm3DomEuLA/lyc4MFnTenE28n0A1P/K/1tF3s/Vy8k+QpbrCvB6I0vcJJoM8HsvEsEs3NdCJwz+ljgxDFEAmePMRW4BUylYP7NrAUEH1DvQih4nD2Ty28aVxTG7x0ixsEY4zKPgBNgGDwzgG3G88LAGAgYEj8pNoMxToixEkLcJnGtOHUSq03oQ0qq/gHpplIX3URdZJ9KVbNqU7Ve9A+o1G13rZSNhXtn7DCLK50rnfN95/fNBRCA43+ABAiAAZCQScJPCAB9mHnAI+w34ABDADAqo0J5RCZZkh+xwULvV1i63GrV/3pRgYc9sfLiCN39eNJ3/B8GsD8AC+Jooh/KUgYmMnAGKrwdt7MhTlU0WfJDknBBNsRzPFQ4NmQnCZqStK8GdTGa5l12HHrj44n1h59uze7p6ftlQ9EcsLMyna5Fog/KP+jqWEb1aaMDZ+xRn+/x9u0vFr7uPvvOmIwbML243lwuRWJr4J0f2EN+gmAcbcTxSAy34y5IZpA16sQF8pRApmiKhoTpWFMVLmSH3zjJsBINRmnnUHBDXjtIXc/febZY+MjQVGfvOV/ktEr5fhWjFHqMDiQvrGpTk9124d7Mt68OmyviZLX3ZtyINZbm1moAWlzOYD+DwCkVzVob5z0MyeCnXkw+iMiXjjktV68VYgVitQiv9/7mg7Ns80my+PHWTGbgdTG/9bzGBRxwp/oTRT+5uXl5TZtuAGDrsyeQygQAHpO1NdfEbUejUZ0gKFlKaOaCNoKiUaGdVC8/3Hm1u50vdv+8mCuJeUVkmUL74vnQWCgSlMlI9ZMK/FzYfv/W3cWOQF3LXz3I6K1S83slGww0C7neU75IeEiCf7xS6XM/OvUCPErCXBEBRm5M+uaeyImkuXkO5RH1+jrLu+nzbrfTNXqjfFMvNSoPV6PCo/AEbHXnl6sb0Zx+O9vml1fn629e3tuDm+mUnAcW13/hMdKJ9blaESdoK0ULsWaF64dI2QKBAue7w5e0jMFHdF/Y4UquZzV51lF3J1PVlDSlSlPZS0871w7O/rKQrx3wgmMJpmfEbCY/3IhP+c7VNxeo4Sulq5/tNKxnYh17yIMTvRR2xAVxVUP7JmS4Vw92hLnpUWEwiYl+3W2EJK9I93veop4wAGMkg/jYzJZ3f0UGSqekcJcNh297/KBjVEhyqTIZWdCzi7Bxdv/3fSZGFERBot8bqFYDfm88rgbF+QvTN+bmS472rV1jYkmiswIzcY4e6mseY6+BByWiMiSabMdZU9WUjsNDtjAre7wDG3DEHUj7cwx2xyiGWw8e5RofRNv6/t3kFQ6A/wHUBeDCAAAAeJxjYGRgYABiXqF/ofH8Nl8ZuFkYQOAm08tHCPr/GxYGpvNALgcDE0gUACrwCzkAeJxjYGRgYNb5r8MQw8IAAkCSkQEV8AAAM2IBzXicY2EAghQGBiYd4jAAN4wCNQAAAAAAAAAMACgAcAC0AOYBLAFgAaIBvAH2AhoAAHicY2BkYGDgYTBgYGYAASYg5gJCBob/YD4DAA6DAVYAeJxlkbtuwkAURMc88gApQomUJoq0TdIQzEOpUDokKCNR0BuzBiO/tF6QSJcPyHflE9Klyyekz2CuG8cr7547M3d9JQO4xjccnJ57vid2cMHqxDWc40G4Tv1JuEF+Fm6ijRfhM+oz4Ra6eBVu4wZvvMFpXLIa40PYQQefwjVc4Uu4Tv1HuEH+FW7i1mkKn6Hj3Am3sHC6wm08Ou8tpSZGe1av1PKggjSxPd8zJtSGTuinyVGa6/Uu8kxZludCmzxMEzV0B6U004k25W35fj2yNlCBSWM1paujKFWZSbfat+7G2mzc7weiu34aczzFNYGBhgfLfcV6iQP3ACkSaj349AxXSN9IT0j16JepOb01doiKbNWt1ovippz6sVYYwsXgX2rGVFIkq7Pl2PNrI6qW6eOshj0xaSq9mpNEZIWs8LZUfOouNkVXxp/d5woqebeYIf4D2J1ywQB4nG2JOw6AIBQE3+IHRbyLAQJaAsJdbOxMPL7x2TrNZHZJ0IeifzQEGrTo0ENiwAiFCRoz4ZbXeRS7bK+rjZHbu8x2PrGT47+Elfe6uMqdLbuGErjNbogeH2oXtw=='
b=base64.b64decode(font_face)
with open('myfont.otf','wb')as f:
f.write(b)
3.获取unicode 与字体文件的映射关系
[code]from fontTools.ttLib import TTFont
ttffont=TTFont("myfont.otf")
print(ttffont.getBestCmap())
#{120: 'x', 58066: 'uniE2D2', 58121: 'uniE309', 58475: 'uniE46B', 58956: 'uniE64C', 59276: 'uniE78C',60233: 'uniEB49', 60479: 'uniEC3F', 61519: 'uniF04F', 62378: 'uniF3AA', 63463: 'uniF7E7'}
这是字体文件中的映射
而网页的字体为:. 之类的16位Unicode,我们只需将其转换成10进制的即可
[code]import re
s="."
n16s=re.findall("&#x(.*?);",s)
for n16 in n16s:
n10=int("0x"+n16,16)
print(n10)
# 58121
# 60479
# 58121
# 61519
这样就可以转换成字体文件中可以识别的 unicode 了
4.根据字体文件渲染unicode
这里我们用到pygame 去将unicode 渲染成图片,首先我们要先观察网页用的字体文件的类型

从图中可知猫眼电影所用的字体文件类型为woff ,通过FreeType的支持的所有字体文件格式可以通过渲染
pygame.freetype,即
TTF,Type1和
CFF,OpenType字体,
SFNT,
PCF,
FNT,
BDF,
PFR和Type42字体。可以访问具有UTF-32代码点的所有字形,
pygame不支持woff ,所以这里用个函数进行转换一下,具体代码如下:
[code]import pygame.freetype
from PIL import Image
from io import BytesIO
import base64
import struct
import sys
import zlib
def convert_streams(infile):
infile=BytesIO(infile)
outfile=BytesIO()
WOFFHeader = {'signature': struct.unpack(">I", infile.read(4))[0],
'flavor': struct.unpack(">I", infile.read(4))[0],
'length': struct.unpack(">I", infile.read(4))[0],
'numTables': struct.unpack(">H", infile.read(2))[0],
'reserved': struct.unpack(">H", infile.read(2))[0],
'totalSfntSize': struct.unpack(">I", infile.read(4))[0],
'majorVersion': struct.unpack(">H", infile.read(2))[0],
'minorVersion': struct.unpack(">H", infile.read(2))[0],
'metaOffset': struct.unpack(">I", infile.read(4))[0],
'metaLength': struct.unpack(">I", infile.read(4))[0],
'metaOrigLength': struct.unpack(">I", infile.read(4))[0],
'privOffset': struct.unpack(">I", infile.read(4))[0],
'privLength': struct.unpack(">I", infile.read(4))[0]}
outfile.write(struct.pack(">I", WOFFHeader['flavor']));
outfile.write(struct.pack(">H", WOFFHeader['numTables']));
maximum = list(filter(lambda x: x[1] <= WOFFHeader['numTables'], [(n, 2**n) for n in range(64)]))[-1];
searchRange = maximum[1] * 16
outfile.write(struct.pack(">H", searchRange));
entrySelector = maximum[0]
outfile.write(struct.pack(">H", entrySelector));
rangeShift = WOFFHeader['numTables'] * 16 - searchRange;
outfile.write(struct.pack(">H", rangeShift));
offset = outfile.tell()
TableDirectoryEntries = []
for i in range(0, WOFFHeader['numTables']):
TableDirectoryEntries.append({'tag': struct.unpack(">I", infile.read(4))[0],
'offset': struct.unpack(">I", infile.read(4))[0],
'compLength': struct.unpack(">I", infile.read(4))[0],
'origLength': struct.unpack(">I", infile.read(4))[0],
'origChecksum': struct.unpack(">I", infile.read(4))[0]})
offset += 4*4
for TableDirectoryEntry in TableDirectoryEntries:
outfile.write(struct.pack(">I", TableDirectoryEntry['tag']))
outfile.write(struct.pack(">I", TableDirectoryEntry['origChecksum']))
outfile.write(struct.pack(">I", offset))
outfile.write(struct.pack(">I", TableDirectoryEntry['origLength']))
TableDirectoryEntry['outOffset'] = offset
offset += TableDirectoryEntry['origLength']
if (offset % 4) != 0:
offset += 4 - (offset % 4)
for TableDirectoryEntry in TableDirectoryEntries:
infile.seek(TableDirectoryEntry['offset'])
compressedData = infile.read(TableDirectoryEntry['compLength'])
if TableDirectoryEntry['compLength'] != TableDirectoryEntry['origLength']:
uncompressedData = zlib.decompress(compressedData)
else:
uncompressedData = compressedData
outfile.seek(TableDirectoryEntry['outOffset'])
outfile.write(uncompressedData)
offset = TableDirectoryEntry['outOffset'] + TableDirectoryEntry['origLength'];
padding = 0
if (offset % 4) != 0:
padding = 4 - (offset % 4)
outfile.write(bytearray(padding));
return outfile.getvalue()
font_face='d09GRgABAAAAAAggAAsAAAAAC7gAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAABHU1VCAAABCAAAADMAAABCsP6z7U9TLzIAAAE8AAAARAAAAFZW7ldeY21hcAAAAYAAAAC8AAACTC79iqhnbHlmAAACPAAAA5EAAAQ0l9+jTWhlYWQAAAXQAAAALwAAADYVJRd8aGhlYQAABgAAAAAcAAAAJAeKAzlobXR4AAAGHAAAABIAAAAwGhwAAGxvY2EAAAYwAAAAGgAAABoGmAWgbWF4cAAABkwAAAAfAAAAIAEZADxuYW1lAAAGbAAAAVcAAAKFkAhoC3Bvc3QAAAfEAAAAXAAAAI8LScOueJxjYGRgYOBikGPQYWB0cfMJYeBgYGGAAJAMY05meiJQDMoDyrGAaQ4gZoOIAgCKIwNPAHicY2Bk0mWcwMDKwMHUyXSGgYGhH0IzvmYwYuRgYGBiYGVmwAoC0lxTGBwYKr4/Z9b5r8MQw6zDcAUozAiSAwDoeQvweJzFkrENg0AMRf8FQgKkSJkhsgM1EhKDsAATpKLMFJSpMgcjAOIKKJAoKMm/M00kaBOf3kn+PtmWfQCOABxyJy6g3lAw9qKqrO4gsLqLB/0brlTOyOuq8dusS3TRx0M0plM562Xhi/3Ililm3DomEuLA/lyc4MFnTenE28n0A1P/K/1tF3s/Vy8k+QpbrCvB6I0vcJJoM8HsvEsEs3NdCJwz+ljgxDFEAmePMRW4BUylYP7NrAUEH1DvQih4nD2Ty28aVxTG7x0ixsEY4zKPgBNgGDwzgG3G88LAGAgYEj8pNoMxToixEkLcJnGtOHUSq03oQ0qq/gHpplIX3URdZJ9KVbNqU7Ve9A+o1G13rZSNhXtn7DCLK50rnfN95/fNBRCA43+ABAiAAZCQScJPCAB9mHnAI+w34ABDADAqo0J5RCZZkh+xwULvV1i63GrV/3pRgYc9sfLiCN39eNJ3/B8GsD8AC+Jooh/KUgYmMnAGKrwdt7MhTlU0WfJDknBBNsRzPFQ4NmQnCZqStK8GdTGa5l12HHrj44n1h59uze7p6ftlQ9EcsLMyna5Fog/KP+jqWEb1aaMDZ+xRn+/x9u0vFr7uPvvOmIwbML243lwuRWJr4J0f2EN+gmAcbcTxSAy34y5IZpA16sQF8pRApmiKhoTpWFMVLmSH3zjJsBINRmnnUHBDXjtIXc/febZY+MjQVGfvOV/ktEr5fhWjFHqMDiQvrGpTk9124d7Mt68OmyviZLX3ZtyINZbm1moAWlzOYD+DwCkVzVob5z0MyeCnXkw+iMiXjjktV68VYgVitQiv9/7mg7Ns80my+PHWTGbgdTG/9bzGBRxwp/oTRT+5uXl5TZtuAGDrsyeQygQAHpO1NdfEbUejUZ0gKFlKaOaCNoKiUaGdVC8/3Hm1u50vdv+8mCuJeUVkmUL74vnQWCgSlMlI9ZMK/FzYfv/W3cWOQF3LXz3I6K1S83slGww0C7neU75IeEiCf7xS6XM/OvUCPErCXBEBRm5M+uaeyImkuXkO5RH1+jrLu+nzbrfTNXqjfFMvNSoPV6PCo/AEbHXnl6sb0Zx+O9vml1fn629e3tuDm+mUnAcW13/hMdKJ9blaESdoK0ULsWaF64dI2QKBAue7w5e0jMFHdF/Y4UquZzV51lF3J1PVlDSlSlPZS0871w7O/rKQrx3wgmMJpmfEbCY/3IhP+c7VNxeo4Sulq5/tNKxnYh17yIMTvRR2xAVxVUP7JmS4Vw92hLnpUWEwiYl+3W2EJK9I93veop4wAGMkg/jYzJZ3f0UGSqekcJcNh297/KBjVEhyqTIZWdCzi7Bxdv/3fSZGFERBot8bqFYDfm88rgbF+QvTN+bmS472rV1jYkmiswIzcY4e6mseY6+BByWiMiSabMdZU9WUjsNDtjAre7wDG3DEHUj7cwx2xyiGWw8e5RofRNv6/t3kFQ6A/wHUBeDCAAAAeJxjYGRgYABiXqF/ofH8Nl8ZuFkYQOAm08tHCPr/GxYGpvNALgcDE0gUACrwCzkAeJxjYGRgYNb5r8MQw8IAAkCSkQEV8AAAM2IBzXicY2EAghQGBiYd4jAAN4wCNQAAAAAAAAAMACgAcAC0AOYBLAFgAaIBvAH2AhoAAHicY2BkYGDgYTBgYGYAASYg5gJCBob/YD4DAA6DAVYAeJxlkbtuwkAURMc88gApQomUJoq0TdIQzEOpUDokKCNR0BuzBiO/tF6QSJcPyHflE9Klyyekz2CuG8cr7547M3d9JQO4xjccnJ57vid2cMHqxDWc40G4Tv1JuEF+Fm6ijRfhM+oz4Ra6eBVu4wZvvMFpXLIa40PYQQefwjVc4Uu4Tv1HuEH+FW7i1mkKn6Hj3Am3sHC6wm08Ou8tpSZGe1av1PKggjSxPd8zJtSGTuinyVGa6/Uu8kxZludCmzxMEzV0B6U004k25W35fj2yNlCBSWM1paujKFWZSbfat+7G2mzc7weiu34aczzFNYGBhgfLfcV6iQP3ACkSaj349AxXSN9IT0j16JepOb01doiKbNWt1ovippz6sVYYwsXgX2rGVFIkq7Pl2PNrI6qW6eOshj0xaSq9mpNEZIWs8LZUfOouNkVXxp/d5woqebeYIf4D2J1ywQB4nG2JOw6AIBQE3+IHRbyLAQJaAsJdbOxMPL7x2TrNZHZJ0IeifzQEGrTo0ENiwAiFCRoz4ZbXeRS7bK+rjZHbu8x2PrGT47+Elfe6uMqdLbuGErjNbogeH2oXtw=='
b=base64.b64decode(font_face)
myfont=BytesIO(convert_streams(b))
uni=58121
pygame.freetype.init()
font=pygame.freetype.Font(myfont,64)
rtext=font.render(chr(uni), (0, 0, 0),(255, 255,255))
pil_string_image = pygame.image.tostring(rtext[0], "RGB")
pil_image = Image.frombytes("RGB",rtext[0].get_size(),pil_string_image)
pil_image.show()
运行此段代码可以将 unicode 渲染成图片,
5.利用tensorflow 的cnn 卷石神经网络,训练模型 识别图片中的字符
接下来就是让计算机将图片识别为字符就好了,我们可以从网上下载一个或多个,全字符的字体文件来训练,然后用pygame 来生成样本, 接下来就是TensorFlow 的训练样本的代码:
[code]import numpy as np
import tensorflow as tf
import pygame
import random
from PIL import Image
import pygame.freetype
from io import BytesIO
from io import StringIO
from fontTools.ttLib import TTFont
pygame.init()
sjs=[0,
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,
16, 17, 18, 19, 20, 21, 22,23, 24, 25, 26, 27, 28, 29, 30,
31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42,
43, 44, 45,315, 316, 317, 318, 319, 320, 321, 322,
323, 324, 325, 326, 327, 328,329,
330, 331, 332, 333, 334, 335, 336, 337, 338, 339,
340, 341, 342, 343, 344,
345, 346, 347, 348, 349,
350, 351, 352, 353, 354, 355, 356, 357, 358, 359,
]
kb=0.75
ttf_names=["e:syc.otf",
# "e:syz.otf","e:o1.otf","e:o2.otf","e:o3.otf",
# "e:o4.otf","e:o5.otf","e:o6.otf","e:o7.otf",
# "e:t1.ttf","e:t2.ttf","e:t3.ttf","e:t4.ttf",
]
ttf_name="e:syc.otf"
def change_ttf(ttf_name):
global font
print(ttf_name)
# font=pygame.freetype.Font(ttf_name,random.randint(60,64))
font=pygame.freetype.Font(ttf_name,64)
ttffont=TTFont(ttf_name)
gbcs=list(ttffont.getBestCmap())
gbc=[]
for k in gbcs:
if 33<=k<=126 or 19968<=k<=40869:
gbc.append(k)
# gbc=gbc[500:507]
sgbc=sorted(gbc)
print("gggggg")
IMAGE_HEIGHT = 64
IMAGE_WIDTH = 64
def k2name(k):
s=str(hex(k))[2:]
s="0"*(4-len(s))+s
return s
def k2im(k):
rtext=font.render(chr(k), (0, 0, 0),(255, 255,255))
pil_string_image = pygame.image.tostring(rtext[0], "RGB")
pil_image = Image.frombytes("RGB",rtext[0].get_size(),pil_string_image).resize((IMAGE_WIDTH,IMAGE_HEIGHT))
im=np.array(pil_image.convert("1"))
return im
def gen_captcha_text_and_image(k):
captcha_text=k2name(k)
captcha_image=k2im(k)
return captcha_text, captcha_image
# text, image = gen_captcha_text_and_image(55)
# print("验证码图像channel:", image.shape) # (60, 160, 3)
# 图像大小
MAX_CAPTCHA = 1
print("验证码文本最长字符数", MAX_CAPTCHA) # 验证码最长4字符; 我全部固定为4,可以不固定. 如果验证码长度小于4,用'_'补齐
# 把彩色图像转为灰度图像(色彩对识别验证码没有什么用)
def convert2gray(img):
if len(img.shape) > 2:
# gray = np.mean(img, -1)
# 上面的转法较快,正规转法如下
r, g, b = img[:,:,0], img[:,:,1], img[:,:,2]
gray = 0.2989 * r + 0.5870 * g + 0.1140 * b
return gray
else:
return img
"""
cnn在图像大小是2的倍数时性能最高, 如果你用的图像大小不是2的倍数,可以在图像边缘补无用像素。
np.pad(image,((2,3),(2,2)), 'constant', constant_values=(255,)) # 在图像上补2行,下补3行,左补2行,右补2行
"""
# 文本转向量
# char_set = number + alphabet + ALPHABET + ['_'] # 如果验证码长度小于4, '_'用来补齐
# CHAR_SET_LEN = len(char_set)
CHAR_SET_LEN=16
CHAR_SET_LEN=len(sgbc)
print(CHAR_SET_LEN)
def text2vec(text):
vector = np.zeros(MAX_CAPTCHA*CHAR_SET_LEN)
idx = int("0x"+text,16)
vector[sgbc.index(idx)] = 1
return vector
# 生成一个训练batch
def get_next_batch(kks):
batch_size=len(kks)
batch_x = np.zeros([batch_size, IMAGE_HEIGHT*IMAGE_WIDTH])
batch_y = np.zeros([batch_size, MAX_CAPTCHA*CHAR_SET_LEN])
# 有时生成图像大小不是(60, 160, 3)
i=0
for kk in kks:
text, image = gen_captcha_text_and_image(kk)
image = convert2gray(image)
batch_x[i,:] = image.flatten() / 1 # (image.flatten()-128)/128 mean为0
batch_y[i,:] = text2vec(text)
i+=1
return batch_x, batch_y
####################################################################
X = tf.placeholder(tf.float32, [None, IMAGE_HEIGHT*IMAGE_WIDTH])
Y = tf.placeholder(tf.float32, [None, MAX_CAPTCHA*CHAR_SET_LEN])
keep_prob = tf.placeholder(tf.float32) # dropout
# 定义CNN
def crack_captcha_cnn(w_alpha=0.01, b_alpha=0.1):
x = tf.reshape(X, shape=[-1, IMAGE_HEIGHT, IMAGE_WIDTH, 1])
#w_c1_alpha = np.sqrt(2.0/(IMAGE_HEIGHT*IMAGE_WIDTH)) #
#w_c2_alpha = np.sqrt(2.0/(3*3*32))
#w_c3_alpha = np.sqrt(2.0/(3*3*64))
#w_d1_alpha = np.sqrt(2.0/(8*32*64))
#out_alpha = np.sqrt(2.0/1024)
# 3 conv layer
w_c1 = tf.Variable(w_alpha*tf.random_normal([3, 3, 1, 16]))
b_c1 = tf.Variable(b_alpha*tf.random_normal([16]))
conv1 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x, w_c1, strides=[1, 1, 1, 1], padding='SAME'), b_c1))
conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv1 = tf.nn.dropout(conv1, keep_prob)
print(conv1.shape)
w_c2 = tf.Variable(w_alpha*tf.random_normal([3, 3, 16, 32]))
b_c2 = tf.Variable(b_alpha*tf.random_normal([32]))
conv2 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv1, w_c2, strides=[1, 1, 1, 1], padding='SAME'), b_c2))
conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv2 = tf.nn.dropout(conv2, keep_prob)
print(conv2.shape)
w_c3 = tf.Variable(w_alpha*tf.random_normal([3, 3, 32, 64]))
b_c3 = tf.Variable(b_alpha*tf.random_normal([64]))
conv3 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv2, w_c3, strides=[1, 1, 1, 1], padding='SAME'), b_c3))
conv3 = tf.nn.max_pool(conv3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv3 = tf.nn.dropout(conv3, keep_prob)
print(conv3.shape)
# Fully connected layer
w_d = tf.Variable(w_alpha*tf.random_normal([8*8*64, 1024]))
b_d = tf.Variable(b_alpha*tf.random_normal([1024]))
dense = tf.reshape(conv3, [-1, w_d.get_shape().as_list()[0]])
dense = tf.nn.relu(tf.add(tf.matmul(dense, w_d), b_d))
dense = tf.nn.dropout(dense, keep_prob)
w_out = tf.Variable(w_alpha*tf.random_normal([1024, MAX_CAPTCHA*CHAR_SET_LEN]))
b_out = tf.Variable(b_alpha*tf.random_normal([MAX_CAPTCHA*CHAR_SET_LEN]))
out = tf.add(tf.matmul(dense, w_out), b_out)
#out = tf.nn.softmax(out)
return out
# 训练
def train_crack_captcha_cnn():
output = crack_captcha_cnn()
# loss
#loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(output, Y))
print("ddddddddd",output.shape,Y.shape)
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=output, labels=Y))
# 最后一层用来分类的softmax和sigmoid有什么不同?
# optimizer 为了加快训练 learning_rate应该开始大,然后慢慢衰
optimizer = tf.train.AdamOptimizer(learning_rate=0.0001).minimize(loss)
predict = tf.reshape(output, [-1, MAX_CAPTCHA, CHAR_SET_LEN])
max_idx_p = tf.argmax(predict, 2)
max_idx_l = tf.argmax(tf.reshape(Y, [-1, MAX_CAPTCHA, CHAR_SET_LEN]), 2)
correct_pred = tf.equal(max_idx_p, max_idx_l)
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
saver = tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess, tf.train.latest_checkpoint("e://model5/"))
# sess.run(tf.global_variables_initializer())
step = 0
p=1
xh=0
tc=0
change_ttf(ttf_names[xh%len(ttf_names)])
while True:
random.shuffle(gbc)
kks=[]
for k in gbc:
kks.append(k)
if len(kks)>0 and len(kks)%200==0:
batch_x, batch_y = get_next_batch(kks)
_, loss_ = sess.run([optimizer, loss], feed_dict={X: batch_x, Y: batch_y, keep_prob: kb})
print(step, loss_)
kks=[]
step += 1
else:
if kks:
batch_x, batch_y = get_next_batch(kks)
_, loss_ = sess.run([optimizer, loss], feed_dict={X: batch_x, Y: batch_y, keep_prob: kb})
print(step, loss_)
kks=[]
step += 1
# if xh%20==0:
if True:
xh+=1
change_ttf(ttf_names[xh%len(ttf_names)])
random.shuffle(gbc)
kks=[]
for k in gbc:
kks.append(k)
if len(kks)>0 and len(kks)%200==0:
break
batch_x_test, batch_y_test = get_next_batch(kks)
acc = sess.run(accuracy, feed_dict={X: batch_x_test, Y: batch_y_test, keep_prob: 1.})
print("预测数据:",xh, acc)
if acc >= p:
# xh+=1
# change_ttf(ttf_names[xh%len(ttf_names)])
p=acc
pp=int(str(acc)[2:])
saver.save(sess, "e:/model5/good.model", global_step=pp)
tc+=1
if tc>=20000:
return True
train_crack_captcha_cnn()
我遇到的字体反爬是全字符字体反爬,要比猫眼的只对数字进行字体反爬难度要大的多,所以你们训练的时候如果网站只对
数字进行字体反爬,那就只训练数字即可,准确率应该100%。

- tensorflow mnist手写字体读取使用
- Windows在pip install tensorflow遇到的问题 一些python安装包的时候,超时问题以及权限问题
- 成功解决read_data_sets (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and wil
- tensorflow python cuda nividia驱动版本对照
- Tensorflow.js运行Python下训练的模型
- python tensorflow keras
- Docker Images: Centos7 + Python3.6 + Tensorflow + Opencv + Dlib
- 成功解决mnist.py:110: dense_to_one_hot (from tensorflow.contrib.learn.python.learn.datasets.mnist) is de
- RuntimeWarning: compiletime version 3.5 of module 'tensorflow.python.framework.fast_tensor_util' doe
- tensorflow.python.platform.gfile
- Tensorflow &&python实战--用梯度下降的优化方法来快速解决线性回归问题
- Windows7+anaconda2+python3+PyCharm+TensorFlow 环境搭建(无GPU)
- Python+tensorflow计算整数阶乘的方法与局限性
- python+TensorFlow常见错误汇总,持续更新中......
- python + tensorflow tensorboard HTTP://0.0.0.0:6006 无法访问 解决方法
- 成功解决softmax_cross_entropy_with_logits (from tensorflow.python.ops.nn_ops) is deprecated and will be
- TensorFlow使用next_batch()读取/tensorflow.python.framework.errors_impl.InvalidArgumentError: Expect 3 fi
- MNIST基础手写体识别 tensorflow+Python
- python2+python3+theano+tensorflow