并发容器学习—ConcurrentLinkedQueue和ConcurrentLinkedDuque
2019-05-02 10:39
561 查看
一、ConcurrentLinkedQueue并发容器
1.
ConcurrentLinkedQueue的底层数据结构
ConcurrentLinkedQueue是一个底层基于链表实现的无界且线程安全的队列。遵循先进先出(FIFO)的原则
。队列的头部是队列中时间最长的元素。队列的尾部是队列中时间最短的元素。它采用CAS算法来实现同步,是个非阻塞的队列。
底层链表由一个个Node结点组成,Node的定义如下:
 之前在ArrayList及LinkedList的学习时
Queue及
AbstractCollection都已学过,不在赘言,直接来看
AbstractQueue的源码:
之前在ArrayList及LinkedList的学习时
Queue及
AbstractCollection都已学过,不在赘言,直接来看
AbstractQueue的源码:
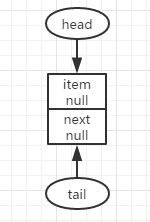 初始状态,队列中没有结点,此时head==tail,指向一个空结点。
初始状态,队列中没有结点,此时head==tail,指向一个空结点。
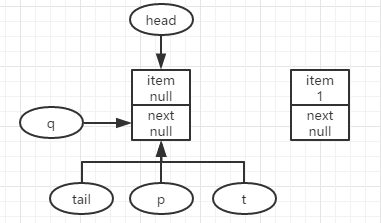
 有第一个结点要入队,通过自旋尝试入队,此时q为p.next,即为null,那么就尝试更新p.next为要新增的结点,如果p.next更新成功,入队成功,再判断p与t是否相同,即是否需要尝试更新tail(p!=t说明tail没有指向队尾),然后结束入队操作;更新p.next失败则继续尝试,直到成功为止(如上右图所示)。
有第一个结点要入队,通过自旋尝试入队,此时q为p.next,即为null,那么就尝试更新p.next为要新增的结点,如果p.next更新成功,入队成功,再判断p与t是否相同,即是否需要尝试更新tail(p!=t说明tail没有指向队尾),然后结束入队操作;更新p.next失败则继续尝试,直到成功为止(如上右图所示)。
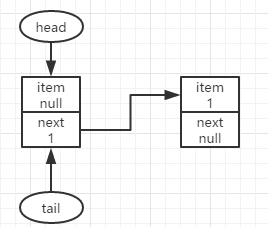
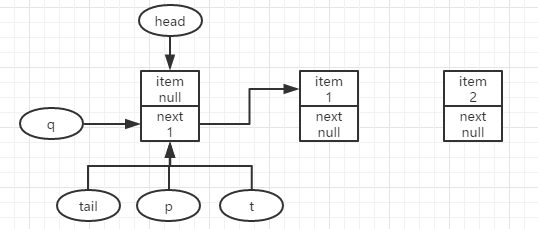 再有第二个结点入队,得到如上图所示,此时q==node1不为null,且p!=q,令p=q指向下个结点重新尝试入队。
再有第二个结点入队,得到如上图所示,此时q==node1不为null,且p!=q,令p=q指向下个结点重新尝试入队。

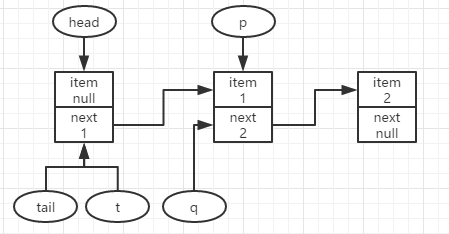 此时q==null,尝试更新p.next为要新增的结点,如果p.next更新成功,入队成功(如上右图所示);失败则继续尝试。
此时q==null,尝试更新p.next为要新增的结点,如果p.next更新成功,入队成功(如上右图所示);失败则继续尝试。
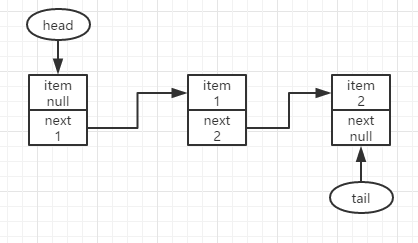 此时判断p!=t,说明tail的指向已经滞后了,没有指向队尾结点,可以尝试更新了,更新成不成功都没有关系,因为不成功也没事,不成功说明有其他线程已经抢先更新过了。成功则tail指向新增结点2.
此时判断p!=t,说明tail的指向已经滞后了,没有指向队尾结点,可以尝试更新了,更新成不成功都没有关系,因为不成功也没事,不成功说明有其他线程已经抢先更新过了。成功则tail指向新增结点2.
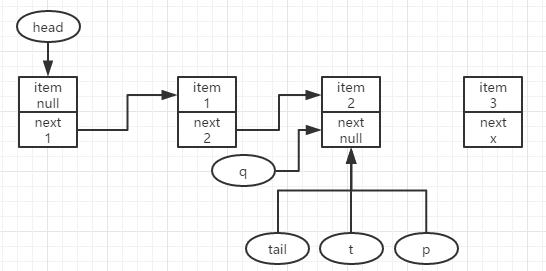
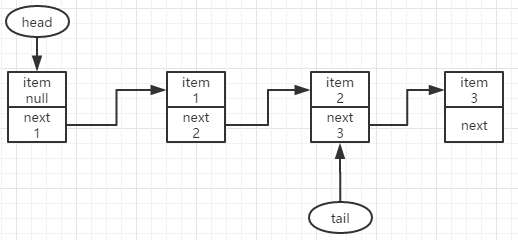 再接下来,入队结点3,此时p=t=tail,q为null,与加入第一个结点过程相同,尝试更新p.next为要新增的结点,成功则结束入队操作;失败则循环继续尝试。
再接下来,入队结点3,此时p=t=tail,q为null,与加入第一个结点过程相同,尝试更新p.next为要新增的结点,成功则结束入队操作;失败则循环继续尝试。
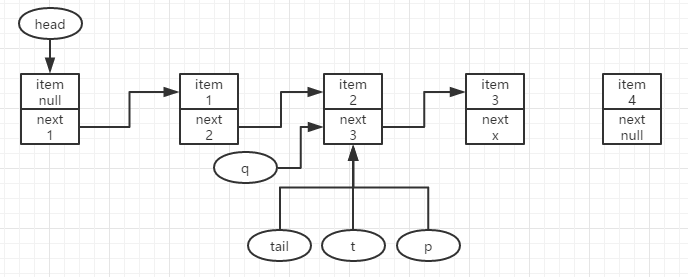 继续入队结点4,此时q==node3不为null,且p!=q,令p=q重新尝试入队。
继续入队结点4,此时q==node3不为null,且p!=q,令p=q重新尝试入队。
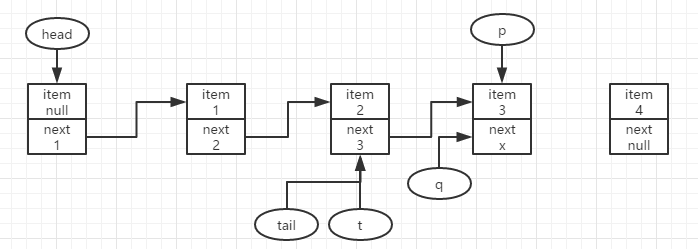 此时q==null,尝试更新p.next为要新增的结点,这里假定更新失败,即有其他线程抢先入队了结点x,且tail也被更新。
此时q==null,尝试更新p.next为要新增的结点,这里假定更新失败,即有其他线程抢先入队了结点x,且tail也被更新。
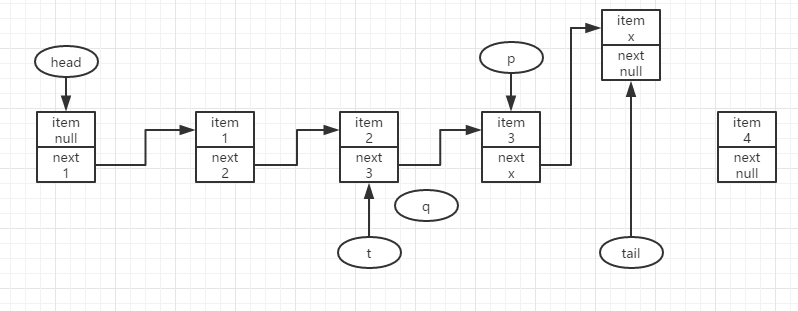
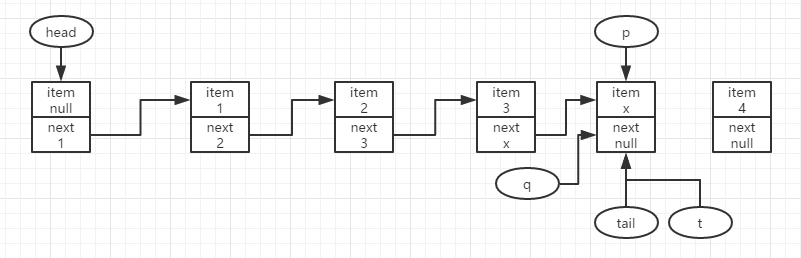 此时p与t不相同,且t与tail也不相同,即tail已经改变,此时结点4要入队只能在新的tail之后去尝试入队,因此直接令p=tail去继续尝试入队。
此时p与t不相同,且t与tail也不相同,即tail已经改变,此时结点4要入队只能在新的tail之后去尝试入队,因此直接令p=tail去继续尝试入队。
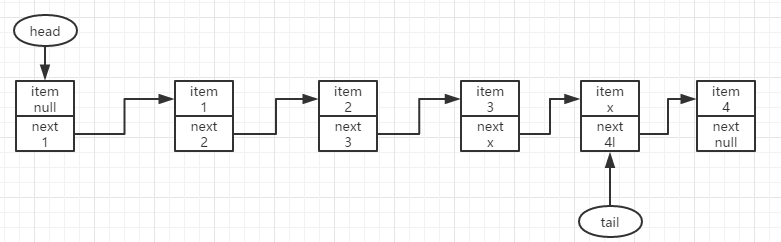 到此在重复前面的入队步骤,q==null,尝试更新p.next为node4.成功则结束。
出队的过程,以上面入完5个结点开始出队过程的分析:
到此在重复前面的入队步骤,q==null,尝试更新p.next为node4.成功则结束。
出队的过程,以上面入完5个结点开始出队过程的分析:
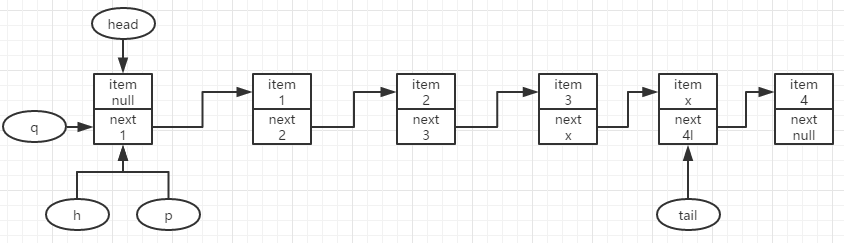 结点1开始出队,此时p=h=head,p.item==null,q=p.next;则可知head结点现在是滞后状态,指向的并不是队首结点,需要查找队首结点,令p=q。
结点1开始出队,此时p=h=head,p.item==null,q=p.next;则可知head结点现在是滞后状态,指向的并不是队首结点,需要查找队首结点,令p=q。
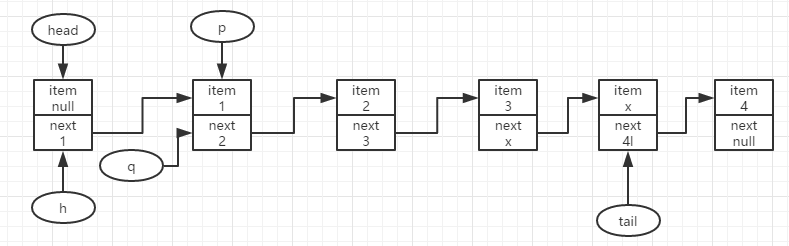 这时p.item!=null,尝试将p.item的值更新为null,因为head之后第一个item不为null的结点即是队首结点,也就是要移除出队的结点,而要被移除的结点的item要被标记成null值,标记成功说明该结点可以删除出队了;若尝试更新失败,说明被其他线程抢先出队,那么就重复上一步继续查找新队首,再尝试出队操作。
这时p.item!=null,尝试将p.item的值更新为null,因为head之后第一个item不为null的结点即是队首结点,也就是要移除出队的结点,而要被移除的结点的item要被标记成null值,标记成功说明该结点可以删除出队了;若尝试更新失败,说明被其他线程抢先出队,那么就重复上一步继续查找新队首,再尝试出队操作。
 若p.item更新成功则判断此时p与h是否相同,若是相同则直接返回item;若是不相同,说明head此时已经滞后了,那么可以尝试更新head(head若是更新成功则h结点的next指向h自身,说明该结点已不再队列中)。
若p.item更新成功则判断此时p与h是否相同,若是相同则直接返回item;若是不相同,说明head此时已经滞后了,那么可以尝试更新head(head若是更新成功则h结点的next指向h自身,说明该结点已不再队列中)。
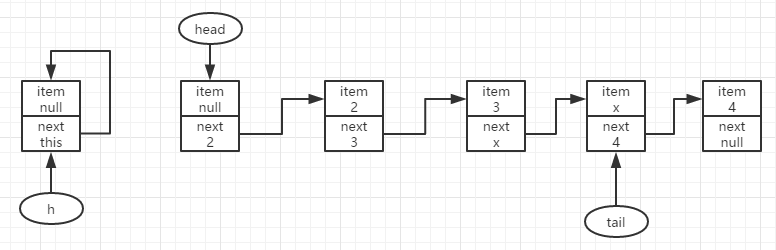 到此,第一个结点的移除就结束了。
到此,第一个结点的移除就结束了。
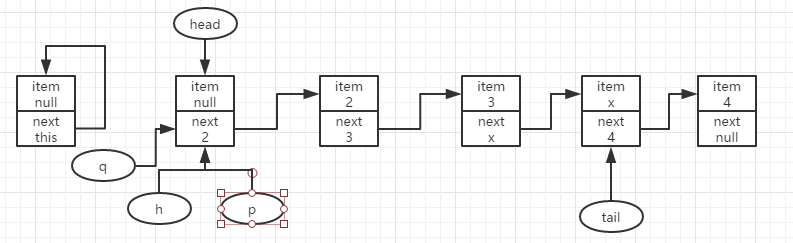 此时,再继续移除队首结点2,如上图所示,有p=h=head,p.item为null,q=p.next且不为null(有后继结点),令p=q往后继续查找队首。
此时,再继续移除队首结点2,如上图所示,有p=h=head,p.item为null,q=p.next且不为null(有后继结点),令p=q往后继续查找队首。
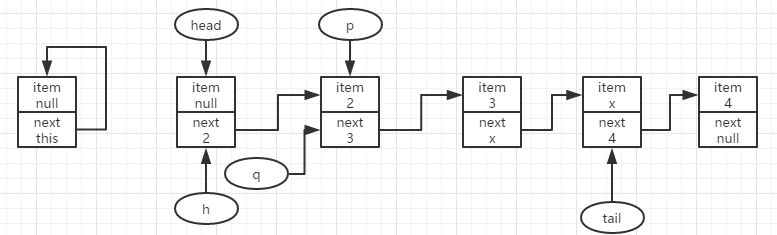 此时p.item=2,不为null,说明找到队首,可以尝试更新结点2的item值,假定此时更新失败,则说明结点2被其他线程抢先移除出队了,那么此时需要继续查找队列中第一个item不为null的结点来出队。
此时p.item=2,不为null,说明找到队首,可以尝试更新结点2的item值,假定此时更新失败,则说明结点2被其他线程抢先移除出队了,那么此时需要继续查找队列中第一个item不为null的结点来出队。
 到此则有p指向node3,此时p.item依旧不为null,则可以执行更新结点3的item,若是更新成功,且head更新失败,则可得到如下图所示结果。
到此则有p指向node3,此时p.item依旧不为null,则可以执行更新结点3的item,若是更新成功,且head更新失败,则可得到如下图所示结果。
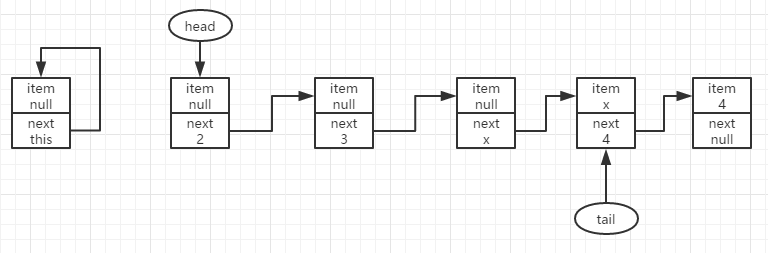 若是继续移除结点x,那么就需要重head开始,遍历到结点x出才可能执行移除出队操作,我们假定在遍历时(在p=h=head之后,结点x正好被移除),有其它线程抢先移除了结点x,并且更新了head的位置,且原本的h的nexr指向h自身。
若是继续移除结点x,那么就需要重head开始,遍历到结点x出才可能执行移除出队操作,我们假定在遍历时(在p=h=head之后,结点x正好被移除),有其它线程抢先移除了结点x,并且更新了head的位置,且原本的h的nexr指向h自身。
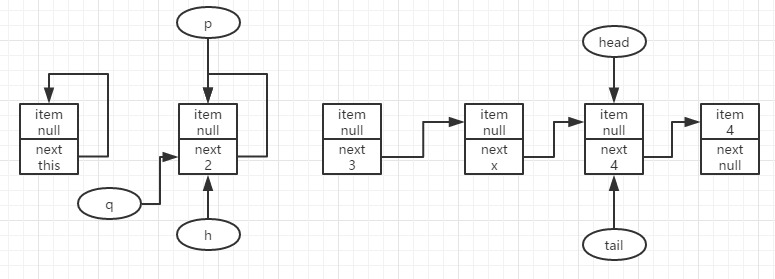 此时有p.item==null,且p==q且不为null,那么需要重新获取p=h=head,得到如下图所示结果。
此时有p.item==null,且p==q且不为null,那么需要重新获取p=h=head,得到如下图所示结果。
 到此,又回到移除队首的初始状态,此时p.item==null,令p=q获取下个结点。
到此,又回到移除队首的初始状态,此时p.item==null,令p=q获取下个结点。
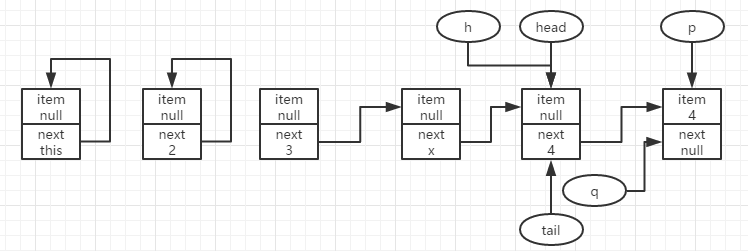 此时,p.item不为null,那么久要尝试更新p.item,假设更新失败,那么此时q=p.next为null,即node4为队尾结点且已经被其他线程抢先移除出队了,那么能做的只剩尝试更新head结点,并且返回null了(队列中没有结点可以移除了,只能返回null)。
从这里还可以看出在
ConcurrentLinkedQueue中head是可以在tail的后面的,这是由于head和tail的滞后性带来的影响。
7.其他的方法
此时,p.item不为null,那么久要尝试更新p.item,假设更新失败,那么此时q=p.next为null,即node4为队尾结点且已经被其他线程抢先移除出队了,那么能做的只剩尝试更新head结点,并且返回null了(队列中没有结点可以移除了,只能返回null)。
从这里还可以看出在
ConcurrentLinkedQueue中head是可以在tail的后面的,这是由于head和tail的滞后性带来的影响。
7.其他的方法
private static class Node<E> {
volatile E item; //存放数据
volatile Node<E> next; //指向下个结点
//构造方法
Node(E item) {
UNSAFE.putObject(this, itemOffset, item); //unsafe操作赋值
}
//CAS方式尝试更新数据
boolean casItem(E cmp, E val) {
return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}
void lazySetNext(Node<E> val) {
UNSAFE.putOrderedObject(this, nextOffset, val);
}
//CAS方式更新下个结点地址
boolean casNext(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
private static final sun.misc.Unsafe UNSAFE;
private static final long itemOffset; //item的内存地址偏移量
private static final long nextOffset; //next的内存地址偏移量
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = Node.class;
itemOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("item"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}
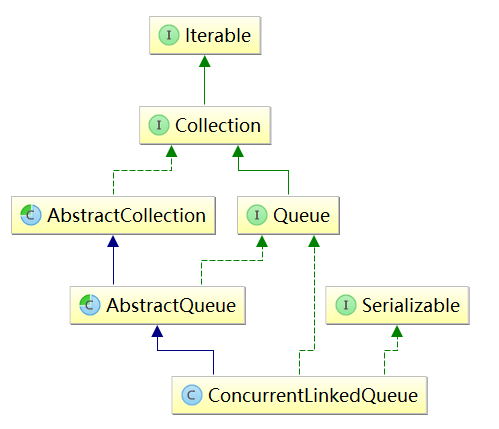
2. ConcurrentLinkedQueue的继承关系 了解了底层的基本实现,再来看看 ConcurrentLinkedQueue的继承关系,如下图所示, ConcurrentLinkedQueue继承了AbstractQueue即实现了Queue接口。
之前在ArrayList及LinkedList的学习时
Queue及
AbstractCollection都已学过,不在赘言,直接来看
AbstractQueue的源码:
public abstract class AbstractQueue<E>
extends AbstractCollection<E>
implements Queue<E> {
protected AbstractQueue() {
}
//向队列末尾新增e元素
public boolean add(E e) {
if (offer(e))
return true;
else
throw new IllegalStateException("Queue full");
}
//删除队首元素,并将其返回
public E remove() {
E x = poll();
if (x != null)
return x;
else
throw new NoSuchElementException();
}
//获取队首元素,但不移除出队列
public E element() {
E x = peek();
if (x != null)
return x;
else
throw new NoSuchElementException();
}
//清空队列中的所有元素
public void clear() {
while (poll() != null)
;
}
//将集合c中的所有元素一次添加到队列末尾
public boolean addAll(Collection<? extends E> c) {
if (c == null)
throw new NullPointerException();
if (c == this)
throw new IllegalArgumentException();
boolean modified = false;
for (E e : c)
if (add(e))
modified = true;
return modified;
}
}
3. 重要属性及构造方法 了解了 ConcurrentLinkedQueue的继承关系,再来看构造方法和一些重要的属性
//底层链表的头结点
private transient volatile Node<E> head;
//底层链表的尾结点
private transient volatile Node<E> tail;
//空构造,创建了一个空队列
public ConcurrentLinkedQueue() {
head = tail = new Node<E>(null);
}
//以结合c中的元素创建一个队列
public ConcurrentLinkedQueue(Collection<? extends E> c) {
Node<E> h = null, t = null;
for (E e : c) {
checkNotNull(e);
Node<E> newNode = new Node<E>(e);
if (h == null)
h = t = newNode;
else {
t.lazySetNext(newNode);
t = newNode;
}
}
if (h == null)
h = t = new Node<E>(null);
head = h;
tail = t;
}
4.入队的实现 队列中添加的方法有两个,分别add和offer,效果没有什么区别,接下来看看实现的过程:
//由源码可见,add的本质还是调用了offer方法
public boolean add(E e) {
return offer(e);
}
public boolean offer(E e) {
//判断待添加的元素是否为null,说明ConcurrentLinkedQueue中不允许null元素
checkNotNull(e);
final Node<E> newNode = new Node<E>(e); //新建结点
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
//判断p是否为尾结点
if (q == null) {
//CAS方式尝试更新p结点的next结点为newNode结点,失败的话继续循环尝试
if (p.casNext(null, newNode)) {
//p的next结点更新成功,说明队列尾结点改变了就继续尝试更新tail的值
//这里判断p!=t,说明tail不是实际的尾结点,应该要更新了,但并不强制
//要求一定要更新成功,即不要求tail一定要指向队列的尾结点,允许tail滞后
//于真正的尾结点
if (p != t)
casTail(t, newNode); //更新tail,失败也没关系
return true;
}
}
else if (p == q)
/**
* p == q说明当前p结点已经被移除出队了,需要重新获取head来进行入队操作
*
* 对于已经移除出队的元素,会将next置为本身,
* 用于判断当前元素已经出队,接着从head继续遍历。
*
* 在整个offer方法的执行过程中,p一定是等于t或者在t的后面的,
* 因此如果p已经不在队列中的话,t也一定不在队列中了(FIFO)。
*
* 所以重新读取一次tail到快照t,
* 如果t未发生变化,就从head开始继续下去。
* 否则让p从新的t开始继续尝试入队是一个更好的选择(此时新的t很可能在head后面)
*/
p = (t != (t = tail)) ? t : head;
else
/**
* 若p与t相等,则让p指向next结点。
* 若p和t不相等,则说明已经经历多次入队失败了(可能被插队了),
* 则重新读取一次tail到t,如果t发生了变化(确实被插队了),则从t开始再次尝试入队。
*/
p = (p != t && t != (t = tail)) ? t : q;
}
}
5.出队的过程
public E poll() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
//判断item是否为null,即判断p结点是否要被移除出队
//若item不为null,则尝试更新item为null,
//因为item若为null表示结点标记为要被移除
if (item != null && p.casItem(item, null)) {
//判断p与h是否还相同
//p与h不相同,说明head可能滞后,即head可能已经不是指向队首结点,
//尝试更新head为p.next(p.next若为null,则说明p为队尾了,head只能更新为p)
//p与h相同则直接返回
if (p != h)
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
}
//判断p是否为队尾,也就是队列是否已经空了
//若队列已经空了,则尝试更新head为p
else if ((q = p.next) == null) {
updateHead(h, p);
return null;
}
//p的next结点若是存在,还需要判断是否在队列中
//若p==q,说明p已经不再队列中了,此时需要重新获取head
//的快照h,并让p=h,尝试移除结点
else if (p == q)
continue restartFromHead;
else
p = q; // 继续向后走一个节点尝试移除结点
}
}
}
final void updateHead(Node<E> h, Node<E> p) {
if (h != p && casHead(h, p))
h.lazySetNext(h); //h的next结点设置为自身
}
6.出入队的过程 ConcurrentLinkedQueue的出入队操作并不是使用加锁的方式实现的线程安全,而是通过无锁的CAS算法实现的,这就使得其代码实现虽然简单,但理解起来晦涩难懂。 ConcurrentLinkedQueue是不允许入队元素时null值的(结点的item不能为null),因为 ConcurrentLinkedQueue对已出队的结点会将item赋上null值。也就是说某个结点的item若为null,则说明该结点是要被删除的结,那么久可以将其重队列中移除了。 ConcurrentLinkedQueue除了对结点有以上要求外,其自身则有如下特点: 1.队列中的所有结点在任意时刻只有最后一个结点的next是为null的。 2.要求head和tail属性不能是null(可以是空结点,即item和next为null)。 3.head和tail具有滞后性,head指向的不一定是队首结点,tail指向的也不一定是队尾结点。 下面以图解的形式先演示入队的过程:
初始状态,队列中没有结点,此时head==tail,指向一个空结点。
有第一个结点要入队,通过自旋尝试入队,此时q为p.next,即为null,那么就尝试更新p.next为要新增的结点,如果p.next更新成功,入队成功,再判断p与t是否相同,即是否需要尝试更新tail(p!=t说明tail没有指向队尾),然后结束入队操作;更新p.next失败则继续尝试,直到成功为止(如上右图所示)。
再有第二个结点入队,得到如上图所示,此时q==node1不为null,且p!=q,令p=q指向下个结点重新尝试入队。
此时q==null,尝试更新p.next为要新增的结点,如果p.next更新成功,入队成功(如上右图所示);失败则继续尝试。
此时判断p!=t,说明tail的指向已经滞后了,没有指向队尾结点,可以尝试更新了,更新成不成功都没有关系,因为不成功也没事,不成功说明有其他线程已经抢先更新过了。成功则tail指向新增结点2.
再接下来,入队结点3,此时p=t=tail,q为null,与加入第一个结点过程相同,尝试更新p.next为要新增的结点,成功则结束入队操作;失败则循环继续尝试。
继续入队结点4,此时q==node3不为null,且p!=q,令p=q重新尝试入队。
此时q==null,尝试更新p.next为要新增的结点,这里假定更新失败,即有其他线程抢先入队了结点x,且tail也被更新。
此时p与t不相同,且t与tail也不相同,即tail已经改变,此时结点4要入队只能在新的tail之后去尝试入队,因此直接令p=tail去继续尝试入队。
到此在重复前面的入队步骤,q==null,尝试更新p.next为node4.成功则结束。
出队的过程,以上面入完5个结点开始出队过程的分析:
结点1开始出队,此时p=h=head,p.item==null,q=p.next;则可知head结点现在是滞后状态,指向的并不是队首结点,需要查找队首结点,令p=q。
这时p.item!=null,尝试将p.item的值更新为null,因为head之后第一个item不为null的结点即是队首结点,也就是要移除出队的结点,而要被移除的结点的item要被标记成null值,标记成功说明该结点可以删除出队了;若尝试更新失败,说明被其他线程抢先出队,那么就重复上一步继续查找新队首,再尝试出队操作。
若p.item更新成功则判断此时p与h是否相同,若是相同则直接返回item;若是不相同,说明head此时已经滞后了,那么可以尝试更新head(head若是更新成功则h结点的next指向h自身,说明该结点已不再队列中)。
到此,第一个结点的移除就结束了。
此时,再继续移除队首结点2,如上图所示,有p=h=head,p.item为null,q=p.next且不为null(有后继结点),令p=q往后继续查找队首。
此时p.item=2,不为null,说明找到队首,可以尝试更新结点2的item值,假定此时更新失败,则说明结点2被其他线程抢先移除出队了,那么此时需要继续查找队列中第一个item不为null的结点来出队。
到此则有p指向node3,此时p.item依旧不为null,则可以执行更新结点3的item,若是更新成功,且head更新失败,则可得到如下图所示结果。
若是继续移除结点x,那么就需要重head开始,遍历到结点x出才可能执行移除出队操作,我们假定在遍历时(在p=h=head之后,结点x正好被移除),有其它线程抢先移除了结点x,并且更新了head的位置,且原本的h的nexr指向h自身。
此时有p.item==null,且p==q且不为null,那么需要重新获取p=h=head,得到如下图所示结果。
到此,又回到移除队首的初始状态,此时p.item==null,令p=q获取下个结点。
此时,p.item不为null,那么久要尝试更新p.item,假设更新失败,那么此时q=p.next为null,即node4为队尾结点且已经被其他线程抢先移除出队了,那么能做的只剩尝试更新head结点,并且返回null了(队列中没有结点可以移除了,只能返回null)。
从这里还可以看出在
ConcurrentLinkedQueue中head是可以在tail的后面的,这是由于head和tail的滞后性带来的影响。
7.其他的方法
//peek的原理与poll差不多,只是peek中获取到队首后,不去进行CAS的更新item操作
//只将item值返回即可
public E peek() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
//判断是不是队首结点,即通过item是否为null,判断当前结点
//是否已被移除出队
//判断p.next是否为null,则是为判断队列是否是空队列
//若是空队列也可结束了
if (item != null || (q = p.next) == null) {
updateHead(h, p); //尝试更新滞后的head
return item;
}
//判断结点是否已经被移除出队,是的话要重新获取head来查找队首
else if (p == q)
continue restartFromHead;
else
p = q;
}
}
}
//统计队列中的元素个数,瞬时值,不能太过依赖
public int size() {
int count = 0;
//获取队首结点,然后遍历队列挨个统计
for (Node<E> p = first(); p != null; p = succ(p))
//判断结点是不是要被移除,或已被移除(item为null,说明是被遗弃的结点,不需要统计)
if (p.item != null)
// Collection.size() spec says to max out
if (++count == Integer.MAX_VALUE)
break;
return count;
}
//获取队首元素,与peek基本一致,只不过返回的是结点,而peek返回的是item
Node<E> first() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) {
boolean hasItem = (p.item != null);
if (hasItem || (q = p.next) == null) {
updateHead(h, p);
return hasItem ? p : null;
}
else if (p == q)
continue restartFromHead;
else
p = q;
}
}
}
//获取后继结点,若是后继结点是自身(已被移除),那么返回head
final Node<E> succ(Node<E> p) {
Node<E> next = p.next;
return (p == next) ? head : next;
}
二、ConcurrentLinkedDueue并发容器
1.ConcurrentLinkedDueue
ConcurrentLinkedDueue的底层数据实现与ConcurrentLinkedQueue类似,都是链表,不同的是ConcurrentLinkedDueue是双向链表,因此ConcurrentLinkedDueue既可以当做队列也可当做栈来使用。并且ConcurrentLinkedDueue实现线程安全的,非阻塞的方式与ConcurrentLinkedQueue一样都是采用CAS算法。若ConcurrentLinkedDueue当做队列使用那么与ConcurrentLinkedQueue没有区别,效率也相同,源码也十分类似,这里就不做过多分析。

相关文章推荐
- 并发容器学习—LinkedTransferQueue
- Java concurrent Framework并发容器之ConcurrentLinkedQueue(1.6)源码分析 ??
- Java并发学习(二十)-ConcurrentLinkedQueue分析
- Java并发容器之非阻塞队列ConcurrentLinkedQueue
- 并发容器分析(四)--ConcurrentLinkedQueue
- Java并发容器和框架--ConcurrentLinkedQueue
- 非阻塞队列ConcurrentLinkedQueue之容器初步学习
- 并发基础_11_并发_容器_ConcurrentLinkedQueue
- 从并发容器ConcurrentLinkedQueue看解决并发问题的设计思路
- 深入浅出 Java Concurrency (20): 并发容器 part 5 ConcurrentLinkedQueue
- Java并发容器——ConcurrentLinkedQueue
- 第六章 Java并发容器和框架(ConcurrentHashMap,ConcurrentLinkedQueue,BlockingQueue,Fork Join)
- Java并发容器:ConcurrentLinkedQueue
- JDK容器与并发—Queue—ConcurrentLinkedQueue
- Java并发容器之ConcurrentLinkedQueue
- Java并发容器之ConcurrentLinkedQueue源码分析
- java 非阻塞算法在并发容器中的实现(ConcurrentLinkedQueue源码)
- 并发容器学习—LinkedBlockingQueue和LinkedBlockingDueue
- Java 并发容器和框架--ConcurrentLinkedQueue
- 【容器】并发队列ConcurrentLinkedQueue和阻塞队列LinkedBlockingQueue用法