上传word文件
开发工具与关键技术:VS C# 作者:宋永烨 撰写时间:2019/4/21
在某些情况下,视图层传入的文件类型会十分复杂,比如当需要上传试题的时候,单个的上传可以通过页面的布局来分类接收,储存,但当需要导入大量试题时,逐个的导入工作量太大了,于是就需要一种可以批量导入的方法但批量导入,接收到的数据全在一起,难以在上传的时候想单个的导入一样处理,于是需要一种设置一种规则,一种导入的规则,当导入的数据按照符合规则输入时,就将它按照规则分割,而实现这一功能的,就是正则表达式(或规则表达式),注:下文默认用户知道填写规则或使用了我们已准备好的模板
一、 处理数据
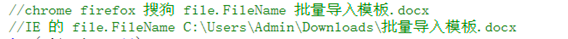
出于兼容性的考虑,在获取文件名时,需要对它的名称处理一下
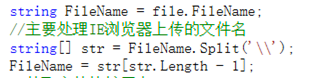
在正则中,反斜杠有特殊含义,所以为了获取它,需要用转义字符来改变他在正则中的意思,当用户使用IE时,剪切就会生效,,获取到它的总长度减一即剪切完后的排在最后一条的数据(序号从零开始排序,长度从一开始,所以要减一),而非IE的用户,剪切后还是本身,即我们需要的值。至于接收用的变量,由于有多个数据,所以需要用数组接收,数据类型为string

将处理好的文件名与一个指定格式的当前时间(当方法调用时会获取电脑的时间)通过字符串拼接的方式组合在一起并赋值给一个数据类型为字符串的变量
二、 储存数据

将数据存储时需要判断存储的路径是否存在,如果存在,就直接进入下面的操作,如果路径不存在,则创建它

将处理完成的数据通过Combine方法将指定时间的文件名称与指定的与服务器虚拟路径对应的物理路径组合成一个路径,并赋值给一个变量,最后将它设置为文件的保存路径

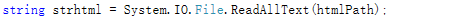
保存路径设置好后,就可以保存文件了,通过上图中的插件,可以将数据的文件类型从word文档的doc或docx等转换成HTML类型的文件

设置文件在数据类型转化完成后的保存路径并赋值给变量,将保存的处理好的文件,读取到document中,再使用插件将它的数据类型修改为HTML文档并保存到设置好的路径中
三、 读取与显示
数据在经历处理,保存后,为了使用户看到是否读取成功与读取后的效果,还要进行一部类似于修改的数据回填的操作

读取储存在指定物理路径下的HTML类型的文件(如果读取不到,说明上一步的储存出现了问题)

读取到的数据将它修改成我们想要的格式,由于数据需要保存到数据库,故不需要除img标签外的任何标签,所以通过正则将p标签匹配到并去除它的style样式,添加一个自定义的样式reg并赋值为demo,将可能存在的pre标签转换为p标签.最后匹配strhtml变量(即通过插件修改文件类型的页面传来的word文档)中的全部符合正则的字符,上图的正则表示的意思是匹配strhtml变量中所有的带有reg属性且值为demo的p标签

创建一个变量,一个可以接收通过正则运算后的结果的变量,然后通过for循环将存储所有p标签的变量中的p标签,通过for循环一个一个取出来

将提取出的值一个一个赋值给strP,然后再调用一个获取p标签内容的正则(自己定义的方法,下文会提到),经它赋值给字符串c,然后创建一个可以接收字符串c的变量的数据类型的变量dic,以键值对的格式储存在dic中,键是自增的i转化的等效字符串的命名,值是变量c即p标签里的内容,最后将dic添加到用于保存结果的变量listLast中

创建一个字符串变量.当处理重复的运行的语句时,使用for循环可以使代码更简洁,但当需要循环的是一个对象或数组,则需要使用foreach,他会将数据遍历循环完全为止.将集合List<Dictionary<string, string>>遍历循环,可以得到若干个Dictionary <string, string>类型的数据,赋值给listItem,再将listItem遍历循环得到若干个string类型的数据并赋值给item.将item赋值给字符串变量strOutHtml并使其再每次循环时叠加(与赋值不同,加等不会将之前获取的数据覆盖),添加完数据后再给字符串变量strOutHtml添加一个换行标签(加等而非赋值).
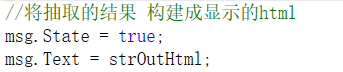
将返回值添加到一个专门用于返回的工具类.msg为该工具类的实例化后的名称,State与Text为其字段,其中State的字段类型为bool类型,用于向页面传输一个状态,完成与否的状态Text的字段类型为String类型,用于向页面传输一个字符串,通常为一句话,比如‘修改成功’,‘修改失败’等,赋值完后将数据返回给页面,用Html的方法赋值,即可读取出其中的img标签并以图片显示
四、获取p标签内容
由于此部分与全文的关系不大,故放在最后
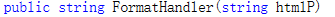
创建一个方法,接收的参数类型为string

由于图片与其它标签皆在p标签中,而图片肯定需要,所以需要判断每一个p标签是否含有img标签,判断的方法通过img特有的src属性即图片的读取地址,然后在所有p标签中寻找,将img标签的存储地址修改为一个临时的存储地址。

通过正则,查询储存了所有p标签的变量htmlstr,匹配到其中的span标签的开始标签与span标签的结束标签和为了防止浏览器的自动清除空格而使用的空格的字符实体,然后将他们替换成空的字符串,效果类似于删除

通过正则将可能存在的注释与p标签去除掉,原理同上,之后将数据返回到传入的参数上,即完成了将数据传入后去掉多余的标签,只留下文本(还有a标签未去除,但会在报春操作中除去),返回给调用方法后赋予的值,即可完成获取p标签内的文本值的功能
注意:
本文中所有的储存地址皆是临时路径,在保存后会移动到用于存储的路径
代码来源与老师

- 带进度的多文件上传(支持上传.doc后缀的word文档并在线预览)
- .NET环境下上传和下载Word文件
- ajax异步上传word以及pdf文件文档
- 上传图片、word等文件到数据库
- weblogic服务上传word等文件直接打开问题解决
- php 上传文件实例 上传并下载word文件
- js+html实现表单上传word等文件
- 上传文件 返回值带 <pre style="word-wrap:break-word;white-space:prewrap;"></pre>
- winfrom 上传word文件
- php实现将上传word文件转为html的方法
- eclipse hadoop windows 运行wordcount程序,上传文件内容为空的原因及解决办法
- word文件上传(前后端分离)
- 也谈使用ASP.NET上传Word文件至服务器,并转成HTML。
- struts2实现word文件上传和在线阅读
- 请教:oa办公问题 上传word文档后,通过ie阅读,再修改后覆盖服务器端的原文件
- windows系统中的浏览器(支持html5的),用html5上传word文件获取到的file.type值为空,ios系统则能获取到
- CKEditor输出成Word文件(包含图片上传)
- Word,Excel,pdf,txt等文件上传并提取内容
- 解决chrome下上传文件 返回值带 <pre style="word-wrap:break-word;white-space:prewrap;"></pre>
- 点滴积累【C#】---C#实现上传word以流形式保存到数据库和读取数据库中的word文件。