使用自己的数据集创建神经网络训练模型,一篇博客就够了。
使用Tensorflow创建自己的数据集,并训练
介绍环境
win10 + pycharm + CPU
介绍背景
要求用卷积神经网络对不同水分的玉米进行分类(最后的目标是实现回归,以后研究),神经网络虽然是科研神器,但是在工业上的应用效果远远不如实验室中的好。我们找到的教程无非是mnist,表情识别,等官方的数据集。对于一个小白来说虽然上手容易,但是收获这得有限。这篇博客我希望把每个知识都讲到尽量的通俗易懂,希望这篇处女作可以给小白指导。文中部分代码参考了ywx1832990,在此感谢。受限于水平,有讲解错误的地方,也欢迎留言探讨。
话不多说 直接上代码
step1:建立两个TFrecords
# pycharm中此模块名为genertateds.py
import os
import tensorflow as tf
from PIL import Image
# 源数据地址
cwd = r'C:\Users\pc\Desktop\orig_picture'
# 生成record路径及文件名
train_record_path =r"C:\Users\pc\Desktop\outputdata\train.tfrecords"
test_record_path =r"C:\Users\pc\Desktop\outputdata\test.tfrecords"
# 分类
classes = {'11.8','13','14.8','16.5','18','20.6','22.8','26.1','28.7','30.6'}
def _byteslist(value):
"""二进制属性"""
return tf.train.Feature(bytes_list = tf.train.BytesList(value = [value]))
def _int64list(value):
"""整数属性"""
return tf.train.Feature(int64_list = tf.train.Int64List(value = [value]))
def create_train_record():
"""创建训练集tfrecord"""
writer = tf.python_io.TFRecordWriter(train_record_path) # 创建一个writer
NUM = 1 # 显示创建过程(计数)
for index, name in enumerate(classes):
class_path = cwd + "/" + name + '/'
l = int(len(os.listdir(class_path)) * 0.7) # 取前70%创建训练集
for img_name in os.listdir(class_path)[:l]:
img_path = class_path + img_name
img = Image.open(img_path)
img = img.resize((128, 128)) # resize图片大小
img_raw = img.tobytes() # 将图片转化为原生bytes
example = tf.train.Example( # 封装到Example中
features=tf.train.Features(feature={
"label":_int64list(index), # label必须为整数类型属性
'img_raw':_byteslist(img_raw) # 图片必须为二进制属性
}))
writer.write(example.SerializeToString())
print('Creating train record in ',NUM)
NUM += 1
writer.close() # 关闭writer
print("Create train_record successful!")
def create_test_record():
"""创建测试tfrecord"""
writer = tf.python_io.TFRecordWriter(test_record_path)
NUM = 1
for index, name in enumerate(classes):
class_path = cwd + '/' + name + '/'
l = int(len(os.listdir(class_path)) * 0.7)
for img_name in os.listdir(class_path)[l:]: # 剩余30%作为测试集
img_path = class_path + img_name
img = Image.open(img_path)
img = img.resize((128, 128))
img_raw = img.tobytes() # 将图片转化为原生bytes
# print(index,img_raw)
example = tf.train.Example(
features=tf.train.Features(feature={
"label":_int64list(index),
'img_raw':_byteslist(img_raw)
}))
writer.write(example.SerializeToString())
print('Creating test record in ',NUM)
NUM += 1
writer.close()
print("Create test_record successful!")
def read_record(filename):
"""读取tfrecord"""
filename_queue = tf.train.string_input_producer([filename]) # 创建文件队列
reader = tf.TFRecordReader() # 创建reader
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(
serialized_example,
features={
'label': tf.FixedLenFeature([], tf.int64),
'img_raw': tf.FixedLenFeature([], tf.string)
}
)
label = features['label']
img = features['img_raw']
img = tf.decode_raw(img, tf.uint8)
img = tf.reshape(img, [128, 128, 3])
img = tf.cast(img, tf.float32) * (1. / 255) - 0.5 # 归一化
label = tf.cast(label, tf.int32)
return img, label
def get_batch_record(filename,batch_size):
"""获取batch"""
image,label = read_record(filename)
image_batch,label_batch = tf.train.shuffle_batch([image,label], # 随机抽取batch size个image、label
batch_size=batch_size,
capacity=2000,
min_after_dequeue=1000)
return image_batch,label_batch
def main():
create_train_record()
create_test_record()
if __name__ == '__main__':
main()
这里值得一提的是 from PIL import Image 在jupyter中某次更新后,会出现无法使用的现象。建议使用jupyter的朋友不要更新。如果更新了可以卸载,重新安装之前的版本
注意 windows下 cwd = r’C:\Users\pc\Desktop\orig_picture’的执行可能会产生一些操作系统层面的格式错误,在下面必须严格遵守 class_path = cwd + “/” + name + ‘/’ 这种格式,否则会出现格式错误。
train_record_path =r"C:\Users\pc\Desktop\outputdata\train.tfrecords"
test_record_path =r"C:\Users\pc\Desktop\outputdata\test.tfrecords"
这两句代码的意思是定义了两个路径,因为这个模块的作用就是创建TFrecord(一种Tensorflow中管理数据的格式,只要想使用Tensorflow,就需要用TFrecord。TFRecord内部使用的是二进制编码,它可以很好的把数据一次性通过一个二进制文件读取进来,而不是一张图片一张图片的读取,节省了时间,增加了效率。)所以需要告诉计算机一个保存的路径
class中不同的数字 classes = {‘11.8’,‘13’,‘14.8’,‘16.5’,‘18’,‘20.6’,‘22.8’,‘26.1’,‘28.7’,‘30.6’} 就是不同的水分
writer = tf.python_io.TFRecordWriter() 这一部分是一个TFRecord的生成器,一般伴随着writer.write(),使用完之后需要关闭生成器,即:writer.close()
tf.train.Example:可以理解为一个包含了Features的内存块,并通过feature将图片的二进制数据和label进行统一封装(把数据和标签统一存储), 然后将example转化为一种字符串的形式, 使用tf.python_io.TFRecordWriter() 写入到TFRecords文件中。
def read_record(filename) 意思是把刚刚创建的tfrecord读取进来 ,至于这里面的函数具体定义了什么,不要深究,我们不是造轮子,会修改其中的关键信息即可,如reshape成128*128的三通道图片。tf.cast()的意思是把tensorflow中的张量数据做一个类型转换,转换成了float32类型
def get_batch_record 获取批的图片数据和标签 。在这里使用了刚刚定义的read_record。tf.train.shuffle_batch是不按照顺序的从队列中读取数据,最后找两个变量image_batch和label_batch接收一下。capacity参数的意义是队列中元素的最大数量,这个无所谓,别设置太小,也别太大,根据你的数据集来决定。
step2:配置图片的参数+定义前向传播过程
#这个模块在pycharm中的名字是forward.py
import tensorflow as tf
# 配置参数
# 图片size
IMAGE_SIZE = 128
NUM_CHANNELS = 3
NUM_LABELS = 10
# 第一层卷积层的尺寸和深度
CONV1_DEEP = 64
CONV1_SIZE = 5
# 第二层卷积层的尺寸和深度
CONV2_DEEP = 128
CONV2_SIZE = 5
# 全连接层的节点个数
FC_SIZE = 10
def get_Weight(shape,regularizer_rate = None): # 定义weight如需正则化需传入zhengzehualv默认值为None
Weight = tf.Variable(tf.truncated_normal(shape=shape,stddev=0.1),dtype=tf.float32) # tensorflow API推荐随机初始化
if regularizer_rate != None:
regularizer = tf.contrib.layers.l2_regularizer(regularizer_rate)
tf.add_to_collection('losses',regularizer(Weight))
return Weight
def get_biase(shape): # 定义biase
biase = tf.Variable(tf.constant(value=0.1,shape=shape),dtype=tf.float32) # tensorflow API推荐初始化0.1
return biase
def create_conv2d(x,w): # 定义卷积层
conv2d = tf.nn.conv2d(x,w,strides=[1,1,1,1],padding='SAME') # 步幅为1、SAME填充
return conv2d
def max_pooling(x): # 定义最大值池化
pool = tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME') # ksize为2、步幅为2、SAME填充
return pool
def create_fc(x,w,b): # 定义全连接层
fc = tf.matmul(x,w) + b
return fc
# 定义前向传播的过程
# 这里添加了一个新的参数train,用于区分训练过程和测试过程。
def inference(input_tensor, train, regularizer_rate):
with tf.variable_scope('layer1-conv1'):
conv1_Weights = get_Weight([CONV1_SIZE,CONV1_SIZE,NUM_CHANNELS,CONV1_DEEP]) # 5*5*64
conv1_baises = get_biase([CONV1_DEEP])
conv1 = tf.nn.bias_add(create_conv2d(input_tensor,conv1_Weights),conv1_baises)
conv1 = tf.nn.relu(conv1) # 使用ReLu激活函数
with tf.name_scope('layer2-pool1'): # 64*64*64
pool1 = max_pooling(conv1)
with tf.variable_scope('layer3-conv2'):
conv2_Weights = get_Weight([CONV2_SIZE,CONV2_SIZE,CONV1_DEEP,CONV2_DEEP]) # 5*5*128
conv2_biases = get_biase([CONV2_DEEP])
conv2 = tf.nn.bias_add(create_conv2d(pool1,conv2_Weights),conv2_biases)
conv2 = tf.nn.relu(conv2)
with tf.name_scope('layer4-pool2'): # 32*32*128
pool2 = max_pooling(conv2)
pool_shape = pool2.get_shape().as_list()
# pool_shape为[batch_size,32,32,128]
# 计算将矩阵拉直成向量之后的长度,这个长度就是矩阵长度及深度的乘积。
nodes = pool_shape[1] * pool_shape[2] * pool_shape[3]
# 通过tf.reshape函数将第四层的输出变成一个batch的向量
reshaped = tf.reshape(pool2, [pool_shape[0], nodes])
# 声明第五层全连接层的变量并实现前向传播过程
with tf.variable_scope('layer5-fc1'):
fc1_Weights = get_Weight([nodes,FC_SIZE],regularizer_rate)
fc1_biases = get_biase([FC_SIZE])
fc1 = tf.nn.relu(create_fc(reshaped,fc1_Weights,fc1_biases))
# 训练过程添加dropout防止过拟合
if train:
fc1 = tf.nn.dropout(fc1, 0.5)
# 声明第六层全连接层的变量并实现前向传播过程
with tf.variable_scope('layer6-fc2'):
fc2_Weights = get_Weight([FC_SIZE,NUM_LABELS],regularizer_rate)
fc2_biases = get_biase([NUM_LABELS])
logit = create_fc(fc1,fc2_Weights,fc2_biases)
# fc2 = tf.nn.relu(fc2) 需要softmax层时使用激活函数
return logit
在写代码的过程中,我们应该把需要配置的参数在开头声明出来(一边写,写到哪个参数,就返回开头定义变量)
IMAGE_SIZE = 128 呼应了上一个模块中的reshape
NUM_CHANNELS = 3 这里涉及到图像的知识,简单来说,设置为3就是彩色图片,设置为1就是灰度图
NUM_LABELS = 10 就是你所提前设置好的标签数(即需要分成多少个类)
CONV1_DEEP = 64 这里的conv卷积层,其实就是我们所说的filter。这里深度deep的意思就是一次性使用多少个filter (就是过滤器的个数,使用几个不同的过滤器,就是确定了深度是几)
CONV1_SIZE = 5 确定卷积(filter)的size,即使用55的"观察窗口" 这样我们第一层的信息量就变成了了55*64
第二层卷积层同理(不懂的小伙伴可以留言)
FC_SIZE = 10 定义全连接层的个数,全连接层的一般是两层,最后一层全连接层就是输出层。全连接层的作用就是特征的加权,最后10个类的所有权值加在一起应该是等于1的。
def get_Weight 这里定义的是后面需要的权重值。
tf.truncated_normal(shape, mean, stddev) :shape表示生成张量的维度(这一部分后面用到了,注意一下),mean是均值,stddev是标准差。这个函数产生正太分布,均值和标准差自己设定。
regularizer_rate的意思是选择一种正则化方式,没有指定的话默认使用l2正则化。l2正则化简单理解就是可以去掉权重值中的超过两次幂的高此项,个人理解是防止过拟合用的。
def get_biase(shape): 定义一个偏置
tf.constant用来定义一个常量,这里的value一般初始化成一个常数或者一个数组。这里初始化成0.1是没有为什么的,不一定非要使用0.1。shape参数和卷积层的深度有关(即,和使用的filter数量有关,不能像0.1一样写死了,是需要变化的)
tf.Variable(initializer,name)用来初始化一个变量。参数initializer是初始化参数,name是可自定义的变量名称
def create_conv2d(x,w)定义一个卷积层,这部分也是很核心的部分
tf.nn.conv2d(x,w,strides=[1,1,1,1],padding=‘SAME’)
x是输入的张量数据 w是权值
strides=[1,1,1,1] (解释一下这个参数,其实不需要过多的纠结,只需要记住,strides在官方定义中就必须是一个一维且具有四个元素的张量,其规定前后必须为1,所以四个参数直接定死了两个,中间的两个参数一般而言都是相同的,步长为1就写 strides=[1,1,1,1] ,步长为2就写 strides=[1,2,2,1] ,由于步长不能过大,因为会损失大量的信息,所以一般选择步长要么为1,要么为2)
padding = ‘SAME’ 同样不需要纠结,就使用SAME即可。本质上说padding是一种filter进行卷积时的策略,一共只有两种策略可以选择,这部分到后面的调优环节再考虑不迟,通常情况下,直接使用SAME是完全没有问题的
def max_pooling(x) 池化层的表面形式来看,十分类似于之前的卷积层。但是二者做的事情是不一样的。池化层的作用是为了避免无关的信息过多,干扰结果,或者影响计算速度所进行的一种降维,是一种特征工程。注意:池化层的输入就是卷积层的输出,这里隐含了一个条件,就是池化层必须在卷积层之后。
tf.nn.max_pool(value, ksize, strides, padding, name=None)中 第一个参数value是最需要注意的,这里的value输入的是feature map(在卷积层中,数据是以一维或者三维的形式存在的。RGB图片可以理解为3个二维图片叠在一起,其中每一个称为一个feature map。而灰度图就仅仅只存在一个feature map)
ksize是池化窗口的大小,取一个四维向量,一般是[1, 1, 1, 1]或者[1, 2, 2, 1]。如果在这里你还在纠结为什么是[1, 1, 1, 1]或者[1, 2, 2, 1],大可不必。在学习的初期,我们不应该被这种细枝末节的细节去分散走我们大多的精力,耗散我们的耐心,降低我们的成就感。你只需要知道,大家都这么用就好。
strides和padding参数的设置同上(没明白的请留言)
def create_fc(x,w,b): 定义一个全连接层,全连接层做的事情,前面已经有提过这里不做赘述,还希望深入了解全连接层作用的同学可以自行查找一些资料
def inference(input_tensor, train, regularizer_rate): 定义一个函数,构造神经网络:神经网络的结构为:输入→卷积层→池化层→卷积层→池化→全连接→全连接。
train这个参数在后面坐了一次if判断,关系到是否要进行dropout
dropout可以理解为在防止过拟合。他的具体过程简要来说,就是不一次性给机器看到所有的数据,每次训练都随机较少一部分数据。
with tf.name_scope的意思就是方便你看代码的,类似于命名空间,不理解可以不看这部分,照着写就可以了。无关痛痒。
在代码运行的中间部分位置使用了一种激活函数–relu。relu函数可以理解为一种可以让机器学习到非线性特征的激活函数。因为我们之前做的无非是矩阵运算,这些都是属于线性运算(要不为啥是线性代数呢…)然而真是的世界中,事物往往都不是线性存在的,加入relu之后我们可以让机器学到这种非线性的特征
step3:定义反向传播网络
如果说之前我们在做的的是从前往后推导,模拟的是人类神经元的思维过程。那么反向传播网络在我看来,就已经超出了人类生物模型的范围,而变成了一种数学上的推导。可以说,在从前往后推导中我们已经建立一种可以用的模型,但是这个模型可以说是“惨不忍睹”,准确率低的令人大致,loss高得不忍直视。我们的前辈想到一种方法,提高模型的准确率。就是所谓的反向传播。通俗解释就是,基于现在的准确率,反向优化建模中所有的参数,再用经过优化的参数,重复建模的过程,再得到一个准确率,一般来说,经过一次优化的参数会提高模型的准确率。那么不断重复之前的过程,重复n多次,在不出现过拟合的前提下,我们最终就可以得到一个很优秀的模型。下面上代码
#这个模块命名为backward.py
#这里需要注意,import genertateds 和 import forward 导入的是刚才定义好的模块,这里体现出了python的继承特点。对python理解不深的同学需要花时间理解一下什么是继承
import tensorflow as tf
import forward
import os
import genertateds
# 定义神经网络相关参数
BACTH_SIZE = 100
LEARNING_RATE_BASE=0.1
LEARNING_RATE_DECAY = 0.99
REGULARAZTION_RATE = 0.0001
TRAINING_STEPS = 150
MOVING_AVERAGE_DECAY = 0.99
train_num_examples = 500
# 模型保存的路径和文件名
MODEL_SAVE_PATH = "LeNet5_model_of_corn1234/"
MODEL_NAME = "LeNet5_model_of_corn1234"
# 定义训练过程
def train():
# 定义输入输出的placeholder
x = tf.placeholder(tf.float32, [
BACTH_SIZE,
forward.IMAGE_SIZE,
forward.IMAGE_SIZE,
forward.NUM_CHANNELS])
y_ = tf.placeholder(tf.int32, [None], name='y-input') # label为int类型
y = forward.inference(x,True,REGULARAZTION_RATE) # 训练过程需要使用正则化
global_step = tf.Variable(0, trainable=False) # 记录step、不可训练的变量
# 定义滑动平均类
variable_average = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variable_average_op = variable_average.apply(tf.trainable_variables())
# 定义损失函数
# cross_entropy_mean = tf.reduce_mean(tf.square(y - y_)) # 使用softmax层时的loss函数
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=y_)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
# 定义指数衰减学习率
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE,
global_step,
train_num_examples/BACTH_SIZE,
LEARNING_RATE_DECAY,
staircase=True)
# 使用AdamOptimizer优化器、记录step
train_step = tf.train.AdamOptimizer(learning_rate).minimize(loss,global_step=global_step)
# 控制计算流程(自己这么理解的...)
with tf.control_dependencies([train_step, variable_average_op]):
train_op = tf.no_op(name='train')
# 初始化TensorFlow持久化类
saver = tf.train.Saver()
# 读取训练集
image_batch,label_batch = genertateds.get_batch_record(genertateds.train_record_path,100)
with tf.Session() as sess:
# 初始化所有变量
init_op = tf.global_variables_initializer()
sess.run(init_op)
# 断点检查
ckpt = tf.train.get_checkpoint_state(MODEL_SAVE_PATH)
# 有checkpoint的话继续上一次的训练
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess,ckpt.model_checkpoint_path)
# 创建线程
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess,coord)
# 开始训练
for i in range(TRAINING_STEPS):
xs, ys = sess.run([image_batch,label_batch])
_, loss_value, step = sess.run([train_op, loss, global_step],
feed_dict={x:xs,y_:ys})
# 每20轮保存一次模型
if i % 20 == 0:
# 输出当前的训练情况
print("After %d training step(s),loss on training batch is %g." % (step, loss_value))
# 保存当前模型
saver.save(
sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME), global_step=global_step)
# 关闭线程
coord.request_stop()
coord.join(threads)
def main():
train()
if __name__ == '__main__':
main()
BACTH_SIZE = 100
这个参数是批尺寸。这是在说,每次拿全部数据中的的一部分过来训练。减少单次的数量,减少时间。如果本身的数据不是很多的话,完全可以直接把全部数据拿过来训练,不需要BACTH_SIZE 这个参数。其实我本身的数据也不是很多,设置这个参数是为了通用性。需要注意的是BACTH_SIZE的值不能太大,也不能太小。太大内存吃不消,也打不到分批的效果。太小可能会出现由于每次取的batch差异性太大,从而使梯度互相抵消,造成结果不收敛。
LEARNING_RATE_BASE=0.1 (学习率的基值)
LEARNING_RATE_DECAY = 0.99 (一般设为接近于1的值)
这两个参数可以合在一起说,因为一般而言,在训练模型的初期,学习率是比较大的,随着训练的步数越来越多,再使用很大的学习率会出现无法收敛的现象(步子太大,本来很小的步子就可以达到最优点,可是直接迈过了最优点。所以经验而谈,最开始可以大步慢走,越深入,越接近最优点,就应该使用小步快跑的方式)这两个参数在后面就是tensorflow中一个调整学习率的API需要的参数。所谓的LEARNING_RATE_BASE=0.1就是初始学习率,LEARNING_RATE_DECAY = 0.99就是学习率的衰减率
REGULARAZTION_RATE = 0.0001 这个参数可以参看前面我对forward.py的描述
TRAINING_STEPS = 150 这个很好理解,就是后面训练的步数
MOVING_AVERAGE_DECAY = 0.99
train_num_examples = 500
这两个参数我们暂时按下不表,后面马上会说到
MODEL_SAVE_PATH = “LeNet5_model_of_corn1234/”
MODEL_NAME = “LeNet5_model_of_corn1234”
以上这两步看着不起眼,但是确实是整个系统中十分重要的一步,也是反向传播网络的灵魂。笔者开始也是在这个位置没有深入理解,导致后面的思维偏离正规。我们需要再次确认,我们现在定义的这个神经网络是在干什么?我希望看到这篇文章的人都可以先不要往后看。先思考5分钟。明白神经网络在干什么,这是对一个新手来说是非常非常重要的。
那么我们下面公布答案,最简单的话说,就是建模。
不管我们在神经网络中,把程序写的多么花哨,多么天花乱坠,神经网络做的事情也仅仅是建模。为什么在网上看到神经网络,最后输出的往往是“准确率”? 难道不是应该对我们的输入进行分类,最后给出一个明确的结果吗?为什么会是一个所谓的“准确率”呢?
不是的,在我们这个构建神经网络的过程中,我们在做的是建模,后面的准确率的本质是,你的测试集在对你构建的模型进行评估,评估模型的准确率。在这里其实并不涉及到具体的分类。
那么具体的分类怎么做呢?答案是,把训练好的模型保存下来,然后再写另外一套别的程序(这部分,我自己还没有具体的理性认识,研究明白了后面会写新的博客)然后我们就要说道刚刚的两句代码了,这两句的代码其实就是在声明一个模型保存的路径和文件名,便于我们以后加载自己的模型,对新的输入进行评估。
def train():这个 模块整个就是在具体的表现训练的过程
x和 y_是两个占位符。所谓占位符,也是不需要太过纠结的细节问题,简单说,就是数据不会是上来一次性全都给你的,而是需要在不同的时间点,分批次给你的。也就是说,输入是在变化的,那么这样,我们在写程序的时候就不可以把程序的输入写死。定义占位符可以完美的解决问题,数据不断的被输入到占位符,程序每次向占位符要数据,然后占位符中的数据更新。
y = forward.inference(x,True,REGULARAZTION_RATE) 这里用了forward.py模块中的一个函数,不理解的同学大可以向上翻。
global_step = tf.Variable(0, trainable=False) 在这里定义了一个“不可训练的变量” ,这个不可训练的变量需要人为设置,并将该参数传入我们的模型。这个参数在后面马上可以用到。
variable_average = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variable_average_op = variable_average.apply(tf.trainable_variables())
这两句代码定义了一个滑动平均类,什么是滑动平均类呢?简而言之,它也是用来更新参数的一个函数,而这种更新参数的方式就是滑动平均,这仅仅是一个名字而已。这个函数初始化需要提供一个衰减速率(decay),用于控制模型的更新速度。MOVING_AVERAGE_DECAY就是这里的衰减速度。可以看到,第二不到吗,等式左边的参数是可以更新的变量,global不参与这里的更新,所以把它设置为不可更新。
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=y_)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection(‘losses’))
这一部分是在定义交叉熵损失函数,交叉熵softmax是在做什么事呢?其实softmax说白了就是在做回归处理。神经网络的本来输出的并不是概率,而是一些经过了复杂的加权,加偏置,非线性处理之后的一个值而已,如何才能让这样一个值变成我们理解的概率值?这就需要softmax。softmax=一部分/一个整体,最后输出的自然就是一个概率值了。(这里不写公式,想看的话网上到处都有) loss最后就等于经过交叉熵之后对张量取平均
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE,global_step,train_num_examples/BACTH_SIZE,
LEARNING_RATE_DECAY,
staircase=True)
这里再定义指数衰减学习率,LEARNING_RATE_BASE是学习率基础值。global_step就是那个手动指定的不能训练的参数
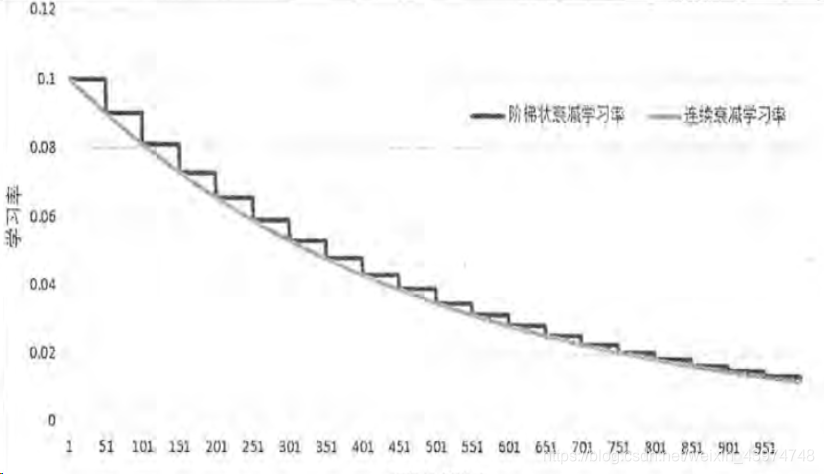
train_num_examples/BACTH_SIZE是衰减的速度,即更新学习率的速度(注意区分,不是学习率本身的变化幅度,而是多长时间需要去变一次。即总训练样本/每次的feed的batch)LEARNING_RATE_DECAY前面提过,是学习率的衰减率(即学习率本身变化的幅度)staircase=True的意思就是梯度衰减,False为平滑衰减。这里借用一张图来解释,何为梯度衰减,何为平滑衰减
train_step = tf.train.AdamOptimizer(learning_rate).minimize(loss,global_step=global_step)
这里需要说明的是,我们最常使用的优化器有两种:随机梯度下降法(SGD) 与 AdamOptimizer,这里我们仅仅需要站在巨人的肩膀上就好。
随机梯度下降的意思,就是在不断的靠近局部(全局)最优点的过程,不断的求导,求导,来达到导数为0的点。每一步求导,基于当前在随机数据批量上的损失,一点点的对参数进行调节
而我们使用AdamOptimizer优化器、记录step。它属于梯度下降的一个分支。它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。可以更好地控制学习速度,使得每一次迭代的学习率都会在一个范围内,不会过大或者过小。
with tf.control_dependencies([train_step, variable_average_op]):
train_op = tf.no_op(name=‘train’)
这里是一个上下文管理器(我自己依旧是按照命名空间来理解的)这部分代码完全不需要背,可以理解为一个固定流程
saver = tf.train.Saver()
image_batch,label_batch = genertateds.get_batch_record(genertateds.train_record_path,100)
这两步,对于有基础的人,应该比较好理解。无非是一个保存模型,一个用来读取训练集中的图片和标签。
with tf.Session() as sess:
这里面在做的事有:1.初始化所有变量(必须加,不要问为什么,加就好了。Tensorflow要求你必须加这两步,否则不work)
2.断点检查 这个意思是你可以在上次训练的模型基础上,接着训练,不需要每次都从头开始
3.创建线程 对于线程,进程,携程不理解的同学需要自行google,这里把这个知识点展开了将不现实(如果需要以后开新的文章介绍) 总而言之,就是你不能把所用东西一次性丢给计算机,而是需要建立一个线程,主线程执行你本应该执行的代码,子线程可以去分批次的拿数据,子线程拿过来一点,主线程就训练一点,边拿边训练。(就好像是本来只有一只手干活,这是手是主线程。主线程忙着的时候,子线程就可以去做一些辅助主线程的工作,来配合子线程)
4.训练,每10轮保存一次模型(随时可以中断,再开启时会自动从上次中断的位置来,生成ckpt文件)
step4:输出测试集的测试结果
#这个模块我命名为test.py
#导入之前的三个模块,分别是genertateds,forward,backward
import time
import forward
import backward
import genertateds
import tensorflow as tf
# 等待时间
TEST_INTERVAL_SECS = 5
# 总测试集样本数量
test_num_examples = 20
def test():
with tf.Graph().as_default() as g:
x = tf.placeholder(tf.float32,[test_num_examples,
forward.IMAGE_SIZE,
forward.IMAGE_SIZE,
forward.NUM_CHANNELS])
y_ = tf.placeholder(tf.int64,[None])
# 测试过程不需要正则化和dropout
y = forward.inference(x,False,None)
# 还原模型中的滑动平均
variable_average = tf.train.ExponentialMovingAverage(backward.MOVING_AVERAGE_DECAY)
variable_average_restore = variable_average.variables_to_restore()
saver = tf.train.Saver(variable_average_restore)
# 计算准确率
correct_prediction = tf.equal(tf.argmax(y,1),y_)
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
image_batch,label_batch = genertateds.get_batch_record(genertateds.test_record_path,20)
while True:
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state(backward.MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess, coord)
image, label = sess.run([image_batch, label_batch])
saver.restore(sess,ckpt.model_checkpoint_path)
# 从文件名称中读取第几次训练
global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
accuracy_score = sess.run(accuracy,feed_dict={x:image,y_:label})
coord.request_stop()
coord.join(threads)
print("After %s training step(s),test accuray = %g"%(global_step,accuracy_score))
else:
time.sleep(TEST_INTERVAL_SECS)
def main():
test()
if __name__ == '__main__':
main()
#等待时间
TEST_INTERVAL_SECS = 5
#总测试集样本数量
test_num_examples = 20
这里再声明两个变量,声明等待时间在后面会用到。time.sleep(TEST_INTERVAL_SECS)的意思是让程序执行到这里,休眠5秒钟,什么都不做。(这个时候cpu可以去处理其他的任何事,只是当前的程序需要休眠)。test_num_examples = 20是后面的占位符需要的参数
def test():
这个函数里做了什么事呢?
首先明确一点,模块名字是test,那么自然,这个函数做的就是验证模型的好坏。怎么评价模型的还坏?自然是对比着验证集来看模型准确率
x和y_是两个占位符,前面已经提过
y由于是在测试,没有正则化处理
variable_average = tf.train.ExponentialMovingAverage(backward.MOVING_AVERAGE_DECAY)
variable_average_restore=variable_average.variables_to_restore()
saver = tf.train.Saver(variable_average_restore)
这里做的之前也有讲过,不再赘述
tf.argmax(input,axis)用来返回返回每行或者每列最大值的索引
tf.equal是一个判等函数
结合起来就是在判断,最大索引值,和测试集中传进来的值是否一致
accuracy= tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
image_batch,label_batch=genertateds.get_batch_record(genertateds.test_record_path,20)这两句代码的细节在上个模块中也提到了,忘记了不妨回看,加深印象
while True:循环
不断的从ckpt中找到训练的模型,用来提供给后面,进行test
到此 一个完整的使用数据集搭建神经网络的过程就完成了闭环。

- pytorch训练(一)——如何使用pytorch创建自己的数据集(含图像的分割处理-一个样本图片分为多个样本图片)
- 详解Matconvnet使用imagenet模型训练自己的数据集
- 深度学习(十四):详解Matconvnet使用imagenet模型训练自己的数据集
- win10系统下使用labelimg 标记自己的数据集并生成tfrecord文件并 开始训练 ,将模型复用,用于识别
- DPM检测模型 训练自己的数据集 读取接口修改
- 使用DPM(Deformable Part Model,voc-release3.1)算法INRIA通过训练你的身体检测模型数据集
- FAIR开源目标识别平台Detectron从入门到放弃(二) 使用自己的数据集(voc2007格式)训练Detectron
- 使用DPM训练自己的模型
- R-FCN+ResNet-50训练自己的数据集模型(python版本)
- Faster RCNN 实践篇 - 使用 resnet 做预训练,Kitti 数据集做 fine-tuning,训练一个目标检测模型
- 使用openface训练自己的第一个模型
- 使用caffe训练并且测试一个自己的模型
- 使用DPM训练自己的模型
- caffe随记(八)---使用caffe训练FCN的pascalcontext-fcn32s模型(pascal-context数据集)
- 使用TensorFlow slim文件夹当中的inception_resnet_v2网络训练自己的分类数据集
- 修改别人标注好的数据集xml文件,使用别人的数据集训练自己的网络
- 使用谷歌Object Detection API进行目标检测、训练新的模型(使用VOC 2012数据集) (转)
- 利用自己的数据集使用VGG16训练Faster R-CNN
- Caffe使用step by step:使用自己数据对已经训练好的模型进行finetuning
- 用已有的模型来训练自己的数据集(finetune)