如何解决Redis中的key过期问题
最近我们在Redis集群中发现了一个有趣的问题。在花费大量时间进行调试和测试后,通过更改key过期,我们可以将某些集群中的Redis内存使用量减少25%。
Twitter内部运行着多个缓存服务。其中一个是由Redis实现的。我们的Redis集群中存储了一些Twitter重要的用例数据,例如展示和参与度数据、广告支出计数和直接消息。
问题背景
早在2016年初,Twitter的Cache团队就对Redis集群的架构进行了大量更新。Redis发生了一些变化,其中包括从Redis 2.4版到3.2版的更新。在此更新后,出现了几个问题,例如用户开始看到内存使用与他们的预期或准备使用的内存不一致、延迟增加和key清除问题。key的清除是一个很大的问题,这可能导致本应持久化的数据可能被删除了,或者请求发送到数据原始存储。
初步调查
受影响的团队和缓存团队开始进行初步的调查。我们发现延迟增加与现在正在发生的key清除有关。当Redis收到写入请求但没有内存来保存写入时,它将停止正在执行的操作,清除key然后保存新key。但是,我们仍然需要找出导致这些新清除的内存使用量增加的原因。
我们怀疑内存中充满了过期但尚未删除的key。有人建议使用扫描,扫描的方法会读取所有的key,并且让过期的key被删除。
在Redis中,key有两种过期方式,主动过期和被动过期。扫描将触发key的被动过期,当读取key时, TTL将会被检查,如果TTL已过期,TTL会被删除并且不返回任何内容。Redis文档中描述了版本3.2中的key的主动过期。key的主动过期以一个名为activeExpireCycle的函数开始。它以每秒运行几次的频率,运行在一个称为cron的内部计时器上。activeExpireCycle函数的作用是遍历每个密钥空间,检查具有TTL集的随机kry,如果满足过期kry的百分比阈值,则重复此过程直到满足时间限制。
这种扫描所有kry的方法是有效的,当扫描完成时,内存使用量也下降了。似乎Redis不再有效地使key过期了。但是,当时的解决方案是增加集群的大小和更多的硬件,这样key就会分布得更多,就会有更多的可用内存。这是令人失望的,因为前面提到的升级Redis的项目通过提高集群的效率降低了运行这些集群的规模和成本。
Redis版本:有什么改变?
Redis版本2.4和3.2之间,activeExpireCycle的实现发生了变化。在Redis 2.4中,每次运行时都会检查每个数据库,在Redis3.2中,可以检查的数据库数量达到了最大值。版本3.2还引入了检查数据库的快速选项。“Slow”在计时器上运行,“fast” 运行在检查事件循环上的事件之前。快速到期周期将在某些条件下提前返回,并且它还具有较低的超时和退出功能阈值。时间限制也会被更频繁地检查。总共有100行代码被添加到此函数中。
进一步调查
最近我们有时间回过头来重新审视这个内存使用问题。我们想探索为什么会出现regression,然后看看我们如何才能更好地实现key expiration。我们的第一个想法是,在Redis中有很多的key,只采样20是远远不够的。我们想研究的另一件事是Redi 3.2中引入数据库限制的影响。
缩放和处理shard的方式使得在Twitter上运行Redis是独一无二的。我们有包含数百万个key的key空间。这对于Redis用户来说并不常见。shard由key空间表示,因此Redis的每个实例都可以有多个shard。我们Redis的实例有很多key空间。Sharding与Twitter的规模相结合,创建了具有大量key和数据库的密集后端。
过期测试的改进
每个循环上采样的数字由变量
ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP配置。我决定测试三个值,并在其中一个有问题的集群中运行这三个值,然后进行扫描,并测量内存使用前后的差异。如果内存使用前后的差异较大,表明有大量过期数据等待收集。这项测试最初在记忆使用方面有积极的结果。
该测试有一个控件和三个测试实例,可以对更多key进行采样。500和200是任意的。值300是基于统计样本大小的计算器的输出,其中总key数是总体大小。在上面的图表中,即使只看测试实例的初始数量,也可以清楚地看出它们的性能更好。这个与运行扫描的百分比的差异表明,过期key的开销约为25%。
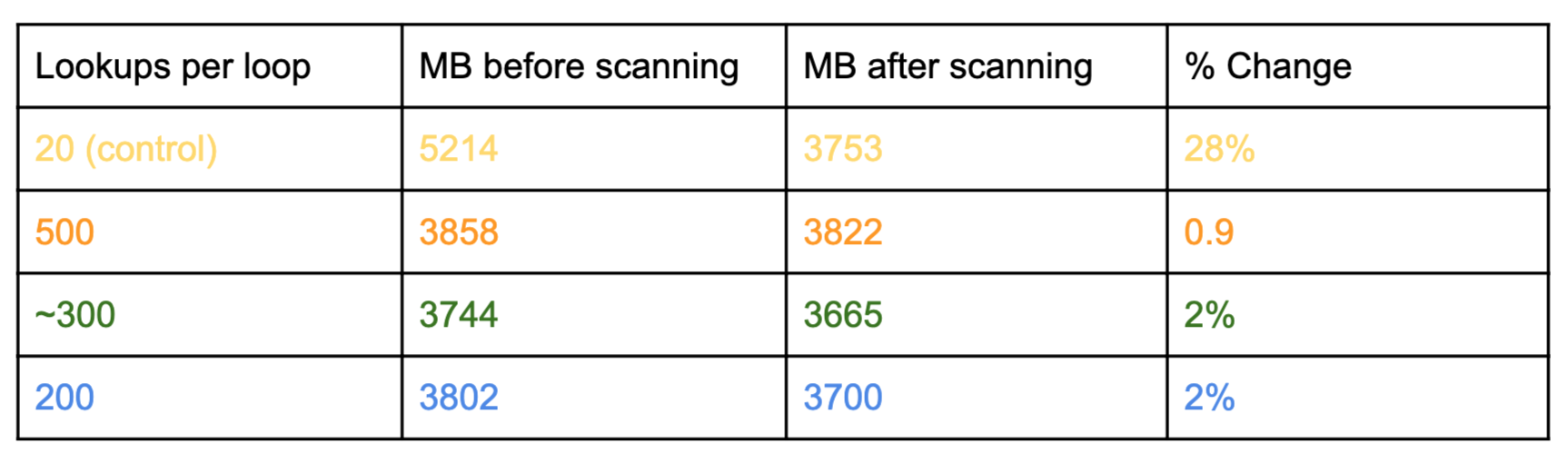 虽然对更多key进行采样有助于我们找到更多过期key,但负延迟效应超出了我们的承受能力。
虽然对更多key进行采样有助于我们找到更多过期key,但负延迟效应超出了我们的承受能力。
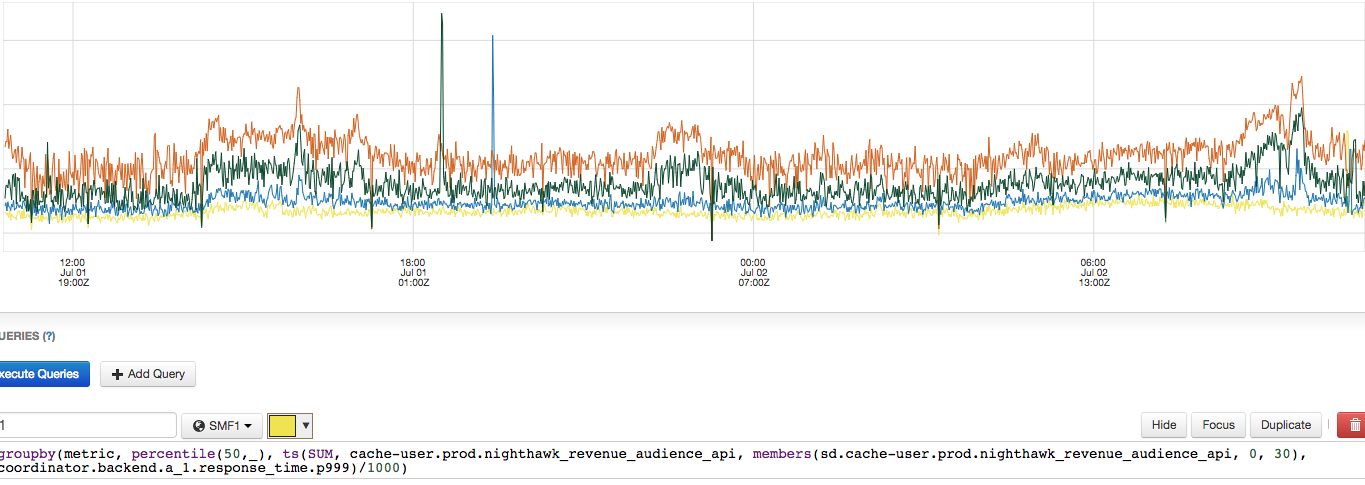 上图显示了99.9%的延迟(以毫秒为单位)。这表明延迟与采样的key的增加相关。橙色代表值500,绿色代表300,蓝色代表200,控制为黄色。这些线条与上表中的颜色相匹配。
上图显示了99.9%的延迟(以毫秒为单位)。这表明延迟与采样的key的增加相关。橙色代表值500,绿色代表300,蓝色代表200,控制为黄色。这些线条与上表中的颜色相匹配。
在看到延迟受到样本大小影响后,我想知道是否可以根据有多少key过期来自动调整样本大小。当有更多的key过期时,延迟会受到影响,但是当没有更多的工作要做时,我们会扫描更少的key并更快地执行。
这个想法基本上是可行的,我们可以看到内存使用更低,延迟没有受到影响,一个度量跟踪样本量显示它随着时间的推移在增加和减少。但是,我们没有采用这种解决方案。这种解决方案引入了一些在我们的控件实例中没有出现的延迟峰值。代码也有点复杂,难以解释,也不直观。我们还必须针对每个不理想的群集进行调整,因为我们希望避免增加操作复杂性。
调查版本之间的拟合
我们还想调查Redis版本之间的变化。Redis新版本引入了一个名为CRON_DBS_PER_CALL的变量。这个变量设置了每次运行此cron时要检查的最大数据库数量。为了测试这种变量的影响,我们简单地注释掉了这些行。
[code]//if (dbs_per_call > server.dbnum || timelimit_exit) dbs_per_call = server.dbnum;
这会比较每次运行时具有限制的,和没有限制的检查所有数据库两个方法之间的效果。我们的基准测试结果十分令人兴奋。但是,我们的测试实例只有一个数据库,从逻辑上讲,这行代码在修改版本和未修改版本之间没有什么区别。变量始终都会被设置。
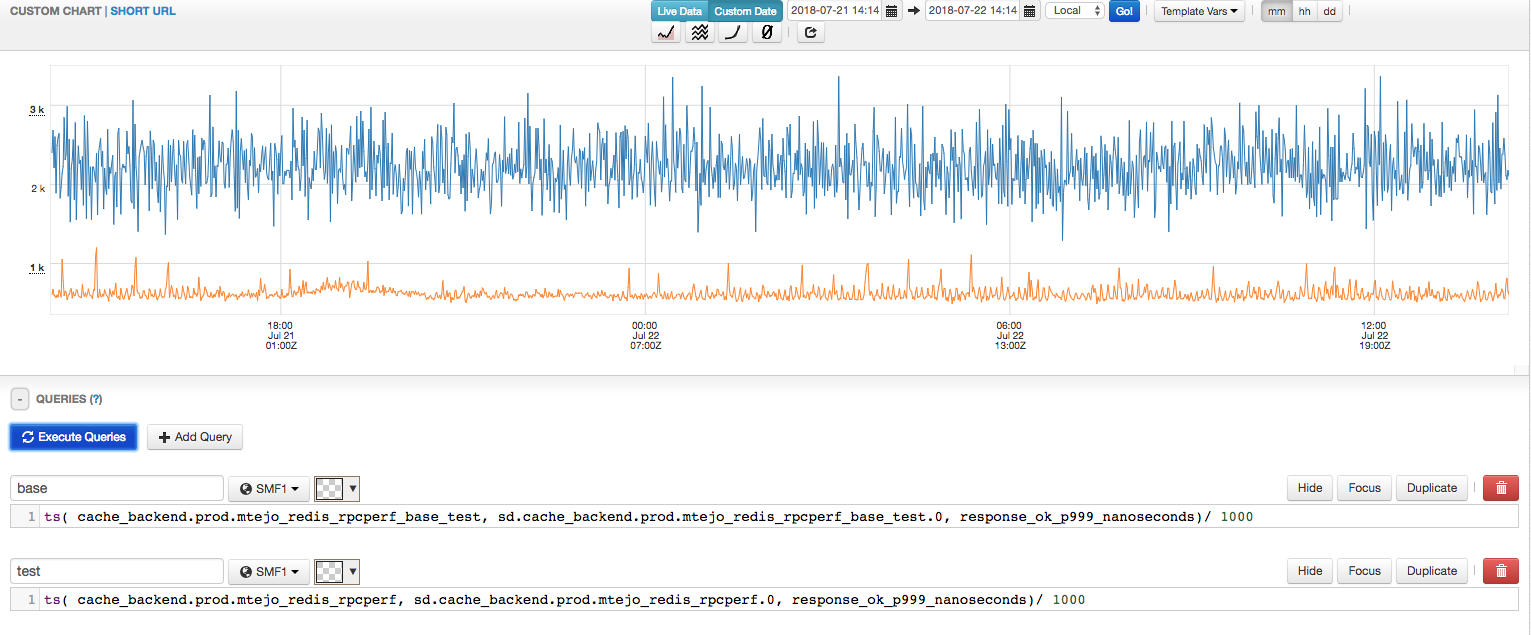 99.9%的以微秒为单位。未修改的Redis在上面,修改的Redis在下面。
99.9%的以微秒为单位。未修改的Redis在上面,修改的Redis在下面。
我们开始研究为什么注释掉这一行会产生如此巨大的差异。由于这是一个if语句,我们首先怀疑的是分支预测。我们利用
gcc’s__builtin_expect
来改变代码的编译方式。但是,这对性能没有任何影响。
接下来,我们查看生成的程序集,以了解究竟发生了什么。
我们将if语句编译成三个重要指令mov、cmp和jg。Mov将加载一些内存到寄存器中,cmp将比较两个寄存器并根据结果设置另一个寄存器,jg将根据另一个寄存器的值执行条件跳转。跳转到的代码将是if块或else块中的代码。我取出if语句并将编译后的程序集放入Redis中。然后我通过注释不同的行来测试每条指令的效果。我测试了mov指令,看看是否存在加载内存或cpu缓存方面的性能问题,但没有发现区别。我测试了cmp指令也没有发现区别。当我使用包含的jg指令运行测试时,延迟会回升到未修改的级别。在找到这个之后,我测试了它是否只是一个跳转,或者是一个特定的jg指令。我添加了非条件跳转指令jmp,跳转然后跳回到代码运行,期间没有出现性能损失。
我们花了一些时间查看不同的性能指标,并尝试了cpu手册中列出的一些自定义指标。关于为什么一条指令会导致这样的性能问题,我们没有任何结论。当执行跳转时,我们有一些与指令缓存缓冲区和cpu行为相关的想法,但是时间不够了,可能的话,我们会在将来再回到这一点。
解析度
既然我们已经很好地理解了问题的原因,那么我们需要选择一个解决这个问题的方法。我们的决定是进行简单的修改,以便能够在启动选项中配置稳定的样本量。这样,我们就能够在延迟和内存使用之间找到一个很好的平衡点。即使删除if语句引起了如此大幅度的改进,如果我们不能解释清楚其原因,我们也很难做出改变。
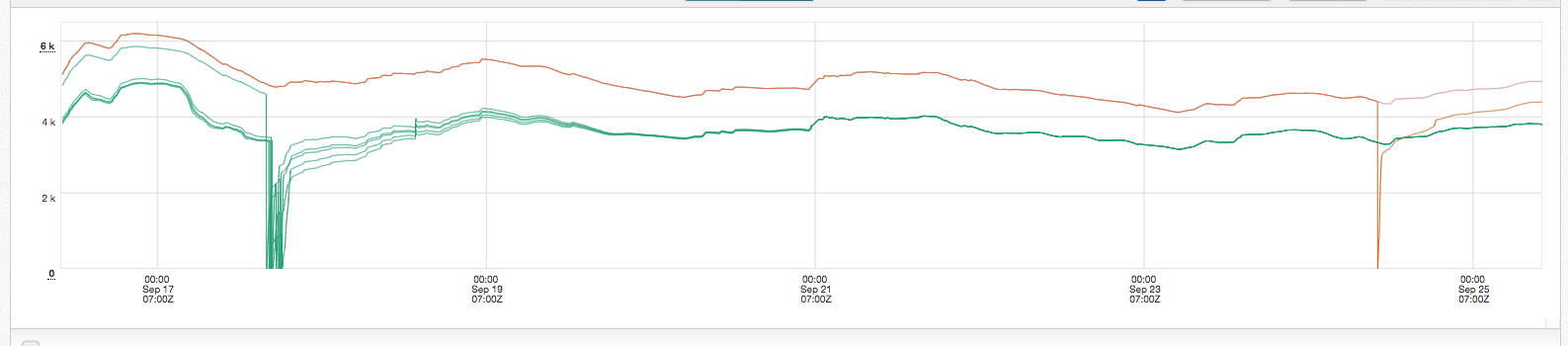 此图是部署到的第一个集群的内存使用情况。顶线(粉红色)隐藏在橙色后面,是集群内存使用的中值。橙色的顶行是一个控件实例。图表的中间部分是新变化的趋势。第三部分显示了一个正在重新启动的控件实例,与淡黄色进行比较。重新启动后,控件的内存使用量迅速增加。
此图是部署到的第一个集群的内存使用情况。顶线(粉红色)隐藏在橙色后面,是集群内存使用的中值。橙色的顶行是一个控件实例。图表的中间部分是新变化的趋势。第三部分显示了一个正在重新启动的控件实例,与淡黄色进行比较。重新启动后,控件的内存使用量迅速增加。
这是一个包括工程师和多个团队的相当大的调查,减少25%的集群大小是一个非常好的结果,从中我们学到了很多!我们想再看一看这段代码,看看在关注性能和调优的其他团队的帮助下,我们可以进行哪些优化。
其他对这项研究做出重大贡献的工程师还有Mike Barry,Rashmi Ramesh和Bart Robinson。
- end -
作者:Matthew Tejo
翻译:许晔
本文转载于外网,原文请戳Improving Key Expiration in Redis

- 关于OpenQuant试用软件的期限的延长问题...如何解决 OpenQuant 过期的问题
- 如何解决MyEclipse过期问题
- redis 批量删除key,与出现的问题解决(MISCONF Redis is configured to save RDB snapshots)
- scrapy-redis所有request爬取完毕,如何解决爬虫空跑问题?
- 如何简便的解决虚拟机里软件过期问题
- 基于redis(key分段,避免一个key过大) 和db实现的 布隆过滤器(解决hash碰撞问题)
- 如何解决前后端token过期问题
- 如何解决wxFrame的key event不好使的问题。
- 如何解决问题“This Class is not Key Value Coding-Compliant for the Key”
- 转-Redis常见的性能问题都有哪些?如何解决?
- 如何确定Kafka的分区数,key和consumer线程数,以及不消费问题解决
- 关于redis主从备份,主机拒绝写入问题 java客户端为保障正常运行该如何操作?( 自码待解决问)
- 阿里JAVA面试题剖析:Redis 的并发竞争问题是什么?如何解决这个问题?
- Next-key locking是如何解决幻读问题的
- 如何解决wxFrame的key event不好使的问题。
- 如何确定Kafka的分区数、key和consumer线程数、以及不消费问题解决
- 如何解决 OpenQuant 过期的问题
- 关于OpenQuant试用软件的期限的延长问题...如何解决 OpenQuant 过期的问题
- 用secureCRT运行redis-cli操作的时候如何解决这样的问题
- 基于redis(key分段,避免一个key过大) 和db实现的 布隆过滤器(解决hash碰撞问题)