Win10系统下Python爬虫常用库的下载04——lxml和beautifulsoup
2019-04-20 15:00
411 查看
版权声明:未经允许,请勿转载! https://blog.csdn.net/weixin_42057995/article/details/89417629
lxml
lxml库结合libxml2快速强大的特性,使用xpath语法来进行文件格式解析,与BeautifulSoup相比,效率更高。主要用于网页解析。
下载1
命令行直接输入pip3 install lxml,进行下载
 这个下载速度非常慢,中途可能会失败,但是可能我人品好,没啥问题,一次成功了。如果出现不能成功下载的情况,不要心慌,下面就是解决办法啦!
这个下载速度非常慢,中途可能会失败,但是可能我人品好,没啥问题,一次成功了。如果出现不能成功下载的情况,不要心慌,下面就是解决办法啦!
下载2
1)查看电脑的Python版本
在命令行输入 python --version,可以看到自己的Python版本,我的是3.7版本

2)安装wheel库
由于lxml是一个.whl文件,所以Python解释器需要先安装wheel库,才能安装.whl文件。
命令行输入:pip3 install wheel
 非常快,就下载好了!
非常快,就下载好了!
3)下载lxml库的.whl文件
lxml下载地址
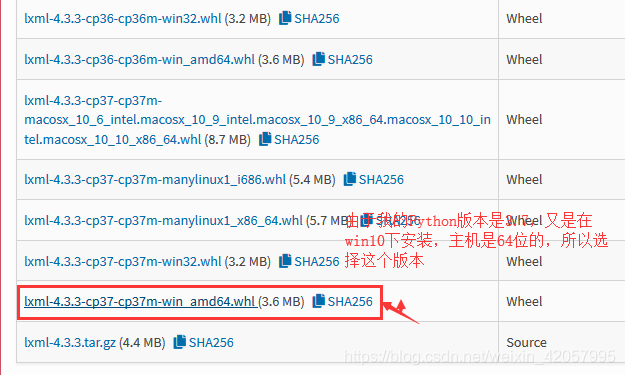 大家根据个人需要下载吧!
大家根据个人需要下载吧!
4)安装
在命令行输入:pip3 install C:\Users\hy\Downloads\lxml-4.3.3-cp37-cp37m-win_amd64.whl
(建议给出全路径,以防命令行找不到你的文件所在)
等待安装完成
5)测试
进入Python解释器,导入lxml包,只要不报错就算安装完成

beautifulsoup
Python解析库,依赖于lxml库。所以在安装beautifulsoup之前,要先安装好lxml,如果还没安装lxml库,请参考我的上一篇博文Win10系统下Python爬虫常用库的下载04——lxml,自行安装。
1)使用pip命令安装
打开cmd,输入pip3 install beautifulsoup4,进行安装!
 2)测试
2)测试
调用以下,不出错就OK啦。详细的使用方法,后续用到的话,再说吧!


相关文章推荐
- 01. windows系统下python爬虫库lxml,BeautifulSoup,Request安装
- python 爬虫 教务系统模拟登陆 并下载课表
- Python爬虫项目班 从零开始实现爬虫系统 百度网盘下载 百度云
- Python爬虫常用模块,BeautifulSoup笔记
- python爬虫:selenuim+phantomjs模拟浏览器操作,用BeautifulSoup解析页面,用requests下载文件
- [python爬虫] 招聘信息定时系统 (一).BeautifulSoup爬取信息并存储MySQL
- Python爬虫beautifulsoup4常用的解析方法总结
- 系统:win10 IDE:pycharm Python版本:2.7 安装第三方插件是报错: 这里写图片描述 报错原因与编码有关,pip把下载的临时文件存放在了用户临时文件中,这个目录一般是C
- 在win10 64位系统安装 lxml (Python 3.5)
- python库学习笔记——爬虫常用的BeautifulSoup的介绍
- 06Python爬虫---正则表达式04之常用表达式
- Python爬虫Scrapy框架学习第1课 Win10系统下scrapy安装和环境搭建
- Python 网络爬虫-正则表达式、BeautifulSoup、lxml三种提取方法
- Python爬虫:常用浏览器的useragent
- Python3之爬虫selenium+chromedriver资源下载及“Message: 'chromedriver' executable needs to be in PATH.处理
- Python爬虫——FileNotFoundError: [WinError 2] 系统找不到指定的文件。
- Python常用的爬虫技巧总结
- WIN10 64位系统 32位Python2.7 PIL安装
- Python爬虫BeautifulSoup用法(1)
- Win10系统Python虚拟环境安装