记录一次服务器“卡死”故障的解决过程

晚上8点多突然收到zabbix报警,服务器负载高,IO负载高。看到报警信息马上就猜到,老问题又出现了上次的方法没能解决问题,故障回顾
故障背景:
系统:ubuntu 14.04
服务器:kvm虚拟机
故障现象:
1.系统存在大量僵死进程,kill -9杀不掉
2.系统IO负载很高
3.执行命令时,终端会卡死
4.reboot无法正常重启服务器,只能杀虚拟机进程
5.系统日志里有以下信息 INFO: task jbd2/vda1-8:775 blocked for more than 120 seconds.
记录一次服务器“卡死”故障的解决过程
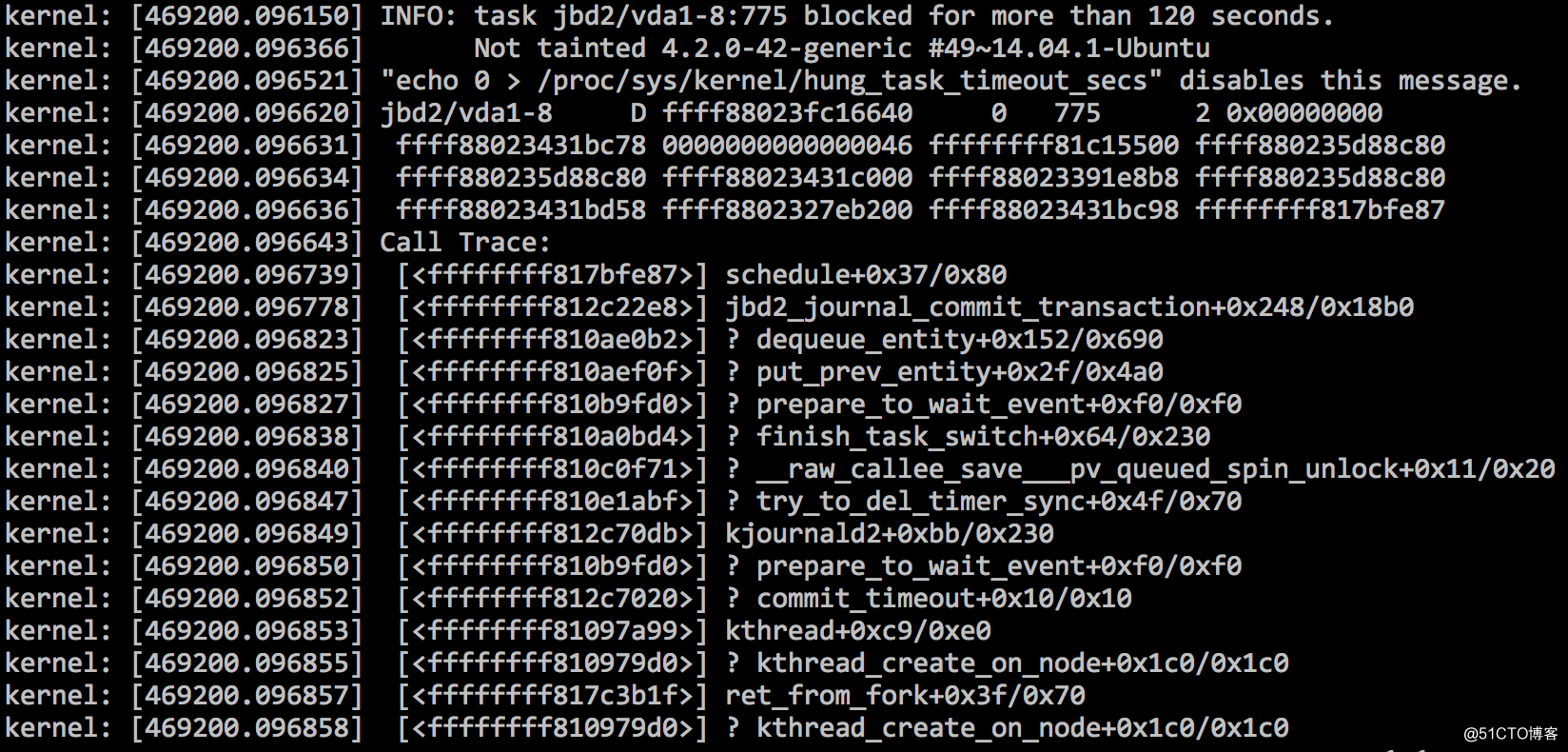
上次出现这个问题是3天前,当时网上查阅资料说是将内存脏页数据刷入磁盘时出现了问题,导致系统阻塞了很多其他进程,从而产生大量僵死进程,按照网上方法,修改调整内核参数:
vm.dirty_ratio = 10 vm.dirty_background_ratio = 5
-------------------------------回顾到此结束--------------------------------
登陆服务器一看,果然还是这个问题,很显然上次的内核参数调整没能解决问题,接下来继续分析,通过一番检查有以下突破性新发现:
1.操作时使用tab补全命令会导致终端卡死,不使用tab则可以正常执行命令
2.一个核心的cpu 100%花在了IO等待上
第一个发现让我想起了一次以前处理故障的经历,/tmp目录满了,导致一使用tab补全命令就卡死,跟今天现象一样,马上检查/tmp分区使用情况,du命令发现/tmp分区是挂载在一个单独100G的硬盘上,只使用了60M,排除空间问题。接着尝试touch /tmp/test测试分区的读写,问题出现了,终端卡死,/tmp分区无法读写,找到了问题突破口
为什么这个分区会无法读写呢,继续排查,mount -l /tmp强制卸载分区然后重新挂载,问题依旧,/tmp无法读写。接着登陆虚拟机控制台,查看块独立硬盘的信息,发现这块独立硬盘用的VirtIO模式,其他硬盘都是IDE模式,很可能问题出在这里。于是新增了一个IDE的硬盘,替换了VirtIO硬盘,然后后重新挂载格式化并重新挂载到/tmp,故障处理告一段落,处理完到今天5天了,问题没在出现,基本可以确定问题是出在虚拟硬盘的模式了。更深一层,为什么virtIO有问题IDE就没问题,要后面继续研究了
总结:
故障第一次出现时没有足够重视,没有深入分析,直接搬用网上”解决方案“,导致故障第二次出现。网上资料很多,也很有用,但要结合实际情况取舍,遇到问题要能独立思考并结合自己以前的经验多分析,提高自己分析问题能力的同时让自己的知识更加融会贯通

原文链接
https://www.geek-share.com/detail/2739698851.html
服务推荐

- 记录一次服务器“卡死”故障的解决过程
- 主板故障导致服务器不定时频繁重启故障解决过程全记录
- 一次线上GC故障解决过程记录
- 记录一次服务器CPU 100%的解决过程
- 一次线上GC故障解决过程记录
- 一次DNS 故障引发的linux telnet 各端口缓慢的问题解决过程
- 记录一次bug解决过程:resultType和手动开启事务
- 记录一次给网站服务器添加SSL(https)的过程
- 记一次服务器被植入挖矿木马cpu飙升200%解决过程
- 一次RAC环境下服务器故障重启后ORACLE启动过程
- 服务器故障排查三板斧:记一次IIS报503/502错误故障排查过程
- 记一次AD域域管理员密码更改导致某系统群集管理器故障排查解决过程
- 记录一次bug解决过程:else未补全导致数据泄露和代码优化
- 记一次网站无法访问解决过程,服务器80端口问题解决过程
- 一次library cache pin故障的解决过程
- 记录由于一次强制断电导致的服务器无法启动的恢复过程
- 一次故障解决过程梳理:mysql varchar text timestamp
- 一次IBM 服务器的磁盘故障更换过程
- 一次服务器被挖矿的处理解决过程
- 记录一次nginx502/504问题解决过程