利用redis实现排行榜的小秘诀
前言
排行榜作为互联网应用中几乎必不可少的一个元素,其能够勾起人类自身对比的欲望,从而来增加商品的销量。
对于排行榜的需求,redis有一个数据结构非常适合做这件事,那就是有序集合(sorted set)。
在日常一些简单的活动开发中,我经常会碰到需要对用户的分值等进行排行,此时一般会选择redis的有序集合对用户的分数进行存储,但是不同的场景排行榜的方式也略有不同,以下根据自己日常的开发进行了一下归纳总结
Redis 有序集合(sorted set)
首先简单介绍下什么是有序集合。
Redis 的Sorted Set 是 String 类型的有序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。 集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
应用场景
场景一:用户得分越高,排行越前面
这是一种最简单基本的应用场景,使用的命令和基本操作如下:
ZADD:添加or更新成员分数
命令参数:ZADD key score member [[score member] [score member] ...]
将一个或多个 member 元素及其 score 值加入到有序集 key 当中。
如果某个 member 已经是有序集的成员,那么更新这个 member 的 score 值,并通过重新插入这个 member 元素,来保证该 member 在正确的位置上。
score 值可以是整数值或双精度浮点数。
如果 key 不存在,则创建一个空的有序集并执行 ZADD 操作。
当 key 存在但不是有序集类型时,返回一个错误。
示例:
// 假设用户A(user1)当前游戏的分数为50,则 ZADD user_rank 50 user1 // 添加用户B(user2)当前游戏的分数为60、用户C(user3)当前游戏的分数为70,则可批量操作 ZADD user_rank 60 user2 70 user3 // 同时添加user2、user3 两个用户的分数,分别为 2、3
ZREVRANK:获取成员当前的排名
命令参数:ZREVRANK key member
返回有序集 key 中成员 member 的排名。其中有序集成员按 score 值递减(从大到小)排序。
排名以 0 为底,也就是说, score 值最大的成员排名为 0 。
示例:
// 获取用户A当前的排名 ZREVRANK user_rank user1 // user1 当前排名为第三,则输出 2
ZSCORE:获取用户排名
命令参数:ZSCORE key member
返回有序集 key 中,成员 member 的 score 值。
如果 member 元素不是有序集 key 的成员,或 key 不存在,返回 nil 。
示例:
// 获取用户A当前的排名 ZSCORE user_rank user1 // user1 当前分数为50,则输出 "50" #注意返回值是字符串
场景二:用户游戏中花费的时间最短,排行越前面
这也算一种最简单基本的应用场景,使用的命令和基本操作和场景一差不多,除了获取排名的命令不一样之外:
ZRANK:获取成员当前的排名
命令参数:ZRANK key member
返回有序集 key 中成员 member 的排名。其中有序集成员按 score 值递增(从小到大)顺序排列。
排名以 0 为底,也就是说, score 值最小的成员排名为 0 。
如何处理以上两个场景中用户分数相同的情况
如果两个用户score相同,redis如何排序呢
在score相同的情况下,redis使用字典排序
那什么是字典排序呢?相信下图就可以解答到这个疑问
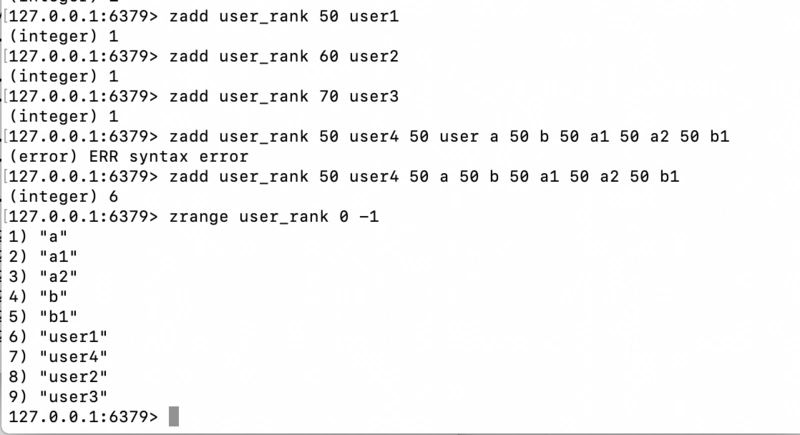
在score相同的情况下,redis使用字典排序,而所谓的字典排序其实就是“ABCDEFG”、"123456..."这样的排序,在首字母相同的情况下,redis会再比较后面的字母,还是按照字典排序
场景一:用户得分越高,排行越前面,如果分数相同情况下,先达成该分数的用户排前面
此场景下,我们需要更改用户的分数构成,具体思路如下:
- 分数相同,用户完成游戏的时间戳也加入到score值的构成中
- 先达成该分数的用户排前面,即游戏所得分数相同的情况下,时间戳越小,越排前
- 如果我们简单地把score结构由:分数+''+时间戳 拼凑,因为分数越大越靠前,而时间戳越小则越靠前,这样两部分的判断规则是相反的,无法简单把两者合成一起成为用户的score
- 但是我们可以逆向思维,可以用同一个足够大的数MAX减去时间戳,时间戳越小,则得到的差值越大,这样我们就可以把score的结构改为:分数+''+(MAX-时间戳),这样就能满足我们的需求了
- 如果使用整数作为score,有一点需要注意的是,js中最大的整数为:
Math.pow(2, 53) - 1 // 9007199254740991 ,16位数
时间戳已经占用了13位数了,因此留给我们保存用户的真正分数的只剩下3位数了
所以最好使用双精度浮点数类型作为score
因此,最好的score结构为:分数+'.'+时间戳,变为浮点数
场景二:用户完成游戏时间最短,排行越前面,如果完成游戏时间相同情况下,先达到该记录的用户排前面
此场景下,我们也需要更改用户的score构成,具体思路如下:
- 完成游戏时间相同,用户完成游戏的时间戳也加入到score值的构成中
- 游戏时间相同,先达到该记录用户排前面,即游戏所得分数相同的情况下,时间戳越小,越排前
- 游戏时间越小越靠前,而时间戳越小也越靠前,这样两部分的判断规则是一致的,我们可以把两者合一起拼凑成score:分数+'.'+时间戳 即可
- 则用户score越小,用户排名越前
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对脚本之家的支持。
您可能感兴趣的文章:

- 利用Redis的有序集合实现排行榜功能实例代码
- 利用redis有序集合实现实时更新阅读排行榜
- 利用多写Redis实现分布式锁原理与实现分析
- Java利用Redis实现消息队列
- 利用redis来实现身份验证的一种方法,类似session机制
- 利用Redis 实现消息队列
- 利用redis-sentinel+consul实现redis高可用
- 如何利用容器实现生产级别的redis sharding集群的一键交付
- 利用scrapy_redis实现分布式爬虫
- 利用redis和php-resque实现后台任务
- redis实现搜索排行榜后记
- 利用Redis 实现消息队列
- redis利用pipline实现发布订阅机制
- Java实现排行榜基于Redis
- 利用redis(spring-data-redis)锁的功能来实现定时器的分布式
- Saltstack 利用pillar实现redis多实例部署
- 利用redis分布式锁的功能来实现定时器的分布式
- Java利用Redis实现消息队列
- 利用redis的订阅和发布来实现实时监控的一个DEMO(Python版本)
- 利用redis实现分布式锁