java集合——HashMap详解(构造哈希函数、解决哈希冲突)
HashMap是基于哈希表的Map接口的实现
所以先来了解一下哈希表吧~
哈希表(散列表)是根据关键码来映射到值的一个数据结构,这个映射函数叫哈希函数(散列函数)。
哈希表中元素是由哈希函数确定的。将数据元素的关键字K作为自变量,通过一定的函数关系(称为哈希函数),计算出的值,即为该元素的存储地址。
表示为:Addr = H(key)
构造哈希函数的方法
- 直接寻址法
取关键字或关键字的某个线性函数值为散列地址。即H(key)=key或H(key) = a·key + b,其中a和b为常数。若其中H(key)中已经有值了,就往下一个找,直到H(key)中没有值了,就放进去。
当关键字基本连续时用这种方法比较方便,若关键字不连续的话将造成内存单元大量浪费。
- 除留余数法
取关键字被某个不大于哈希表表长m的数p除后所得余数为哈希地址(p为素数)
H(key)=key mod p,p<=m (这是最简单,最常用的方法)
这种方法的关键是选好p,使得元素集合中每一个关键字通过该函数转换后映射到哈希表范围的任意地址上的概率相等,尽可能减少冲突。
- 随机数法
选择一个随机函数,取关键字的随机函数值为它的哈希地址。即H(key)= random(key),其中random为随机函数。
此方法适用于关键字长度不等时。
- 数字分析法
分析一组数据,比如一组员工的出生年月日,这时我们发现出生年月日的前几位数字大体相同,这样的话,出现冲突的几率就会很大,但是我们发现年月日的后几位表示月份和具体日期的数字差别很大,如果用后面的数字来构成散列地址,则冲突的几率会明显降低。因此数字分析法就是找出数字的规律,尽可能利用这些数据来构造冲突几率较低的散列地址。
- 平方取中法
当无法确定关键字中哪几位分布较均匀时,可以先求出关键字的平方值,然后按需要取平方值的中间几位作为哈希地址。这是因为:平方后中间几位和关键字中每一位都相关,故不同关键字会以较高的概率产生不同的哈希地址。
- 折叠法
将关键字分割成位数相同的几部分,最后一部分位数可以不同,然后取这几部分的叠加和(去除进位)作为散列地址。数位叠加可以有移位叠加和间界叠加两种方法。移位叠加是将分割后的每一部分的最低位对齐,然后相加;间界叠加是从一端向另一端沿分割界来回折叠,然后对齐相加。
选择不同的哈希函数时应该考虑的因素有:
- 计算哈希函数所需时间
- 关键字的长度
- 哈希表的大小
- 关键字的分布情况
- 记录的查找频率
解决哈希冲突的方法
-
开放地址法
基本思想:当关键字key的哈希地址p = H(key)出现冲突时,以p为基础,产生另一个哈希地址p1,如果p1仍然冲突,再以p为基础,产生另一个哈希地址p2,…,直到找出一个不冲突的哈希地址pi ,将相应元素存入其中。这种方法有一个通用的再散列函数形式:Hi=(H(key)+di)% m i=1,2,…,n
其中di称为增量序列。增量序列的取值方式不同,相应的再散列方式也不同。主要有以下三种:
1.线性探测再散列 di=1,2,3,…,m-1
这种方法的特点是:冲突发生时,顺序查看表中下一单元,直到找出一个空单元或查遍全表。
2.二次探测再散列 di=12,-12,22,-22,…,k2,-k2 ( k<=m/2 )
这种方法的特点是:冲突发生时,在表的左右进行跳跃式探测,比较灵活。
3.伪随机探测再散列 di=伪随机数序列
具体实现时,应建立一个伪随机数发生器,(如i=(i+p) % m),并给定一个随机数做起点。
- 链地址法
基本思想是将所有哈希地址为 i 的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。
- 再哈希法
这种方法是同时构造多个不同的哈希函数:Hi=RH1(key) i=1,2,…,k
当哈希地址Hi=RH1(key)发生冲突时,再计算Hi=RH2(key)……,直到冲突不再产生。这种方法不易产生聚集,但增加了计算时间。
- 建立公共溢出区
基本思想:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
此处知识还可参考哈希表及处理冲突的常用方法
开始HashMap的分析la…
list接口存储的是单个数值,而map接口存储的key-value 键值对
主要特点
- 数据无序
- 键不能重复、值可以重复
- 键和值都能为null
一、继承关系

实现了Map接口,可以克隆、序列化
二、基本属性
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //哈希表中数组默认初始值大小为16
static final int MAXIMUM_CAPACITY = 1 << 30; //哈希表中数组最大容量值
static final float DEFAULT_LOAD_FACTOR = 0.75f; //默认的加载因子(扩容时使用)
static final Entry<?,?>[] EMPTY_TABLE = {};
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
transient int size; //hashMap中存储entry实体的个数
int threshold; //扩容的阈值(capacity * loadFactor)
final float loadFactor; //加载因子
三、底层数据结构
static class Entry<K,V>{
final K key; //键值对的key
V value; //键值对的value
Entry<K,V> next; //next节点
int hash; //和key相关的hash
}
HashMap的底层数据结构是数组+链表实现的,数组中存储的是一个个entry实体,hash到同一个索引位置的数据通过链表链接起来
四、构造函数
- 指定初始容量和加载因子
public HashMap(int initialCapacity, float loa
3ff7
dFactor) { //指定初始容量和加载因子
if (initialCapacity < 0) //基本参数校验
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor; //加载因子初始化
threshold = initialCapacity; //扩容阈值初始化
init();
}
- 通过默认加载因子和指定容量初始化

- 通过默认加载因子和默认容量初始化

- 通过map集合来初始化当前集合

五、GRUD方法解析
1. put() 方法:添加元素
public V put(K key, V value) {
//第一次插入元素,对数组进行初始化
if (table == EMPTY_TABLE) {
inflateTable(threshold); //数组大小为2的指数关系
}
if (key == null) //key为null
return putForNullKey(value); //按下述方法添加
//key不为null
int hash = hash(key);//通过key来哈希找到该数据所存在的索引位置(key相关的哈希值 )
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
//遍历该位置i下面的链表,判断key是否存在
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
//存在替换value,不存在创建新entry
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
//如果插入key为null的情况
private V putForNullKey(V value) {
//key为null存储在table索引位0号位置
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
//遍历该位置下的链表,查看key为null的节点是否存在,存在即将value更新为传入的value
//若该链表下不存在则创建新的entry节点插入该链表
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
hash的过程:
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
通过hash值查找索引:
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}
addEntry():
扩容时机:当前存储元素的个数size>=扩容阈值threshold时考虑扩容
扩容大小为2倍的table.length,(数组要满足2的指数级关系)

扩容函数:

transfer():
创建新的table数组,将原来集合上的元素全部进行hash,找到新的对应位置进行插入

createEntry():
将元素作为当前索引位置的头部元素进行插入

2.get():获取元素
- 通过key来查找value
判断key是否为null
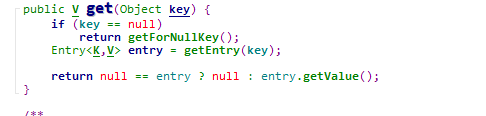
- 如果key为null 长度为0直接return
- 否则直接从0号索引开始查找
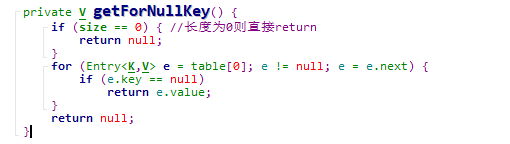
-
size为0直接返回

3.remove():删除元素
- 通过key进行删除元素

- 分为所删除元素是否是头结点来进行删除 如果是头结点,table[i] =next;
- 否则,prev.next = next;

六、常用方法
int size(); map中存储键值对的个数 boolean isEmpty(); 判断集合是否为空 boolean containsKey(Object key); 判断键是否存在 boolean containsValue(Object value); 判断值是否存在 void putAll(Map<? extends K, ? extends V> m); 将map集合添加至该集合中 void clear(); 清除集合
七、迭代器
public class TestHashMap {
public static void main(String[] args) {
HashMap<String,String> hashMap = new HashMap<String,String>();
//插入元素
hashMap.put("zhangSan","1"); //(键,值)
hashMap.put("liSi","2");
hashMap.put("hh","3");
hashMap.put("qq","4");
//对map集合的遍历:3种
//通过键值对遍历
//先将HashMap实例转化为set实例(类型map.entry<>)
Iterator<Map.Entry<String,String>> it = hashMap.entrySet().iterator();
while (it.hasNext()){
Map.Entry<String,String> next = it.next();
String key = next.getKey();
String value = next.getValue();
System.out.print(key+":"+value+" ");
}
System.out.println();
//通过键来遍历
//仅仅对键进行访问
Iterator<String> iterator1 = hashMap.keySet().iterator();
while (iterator1.hasNext()){
String next = iterator1.next();
System.out.print(next+" ");
}
System.out.println();
//通过值遍历
//仅对值进行访问
Iterator<String> iterator2 = hashMap.values().iterator();
while (iterator2.hasNext()){
String next = iterator2.next();
System.out.print(next+" ");
}
System.out.println();
}
}

- Java 集合 2:HashMap(put方法的实现与哈希冲突)
- java集合(2)- java中HashMap详解
- JAVA HashMap判断冲突及其解决冲突策略
- Java集合-HashMap数据结构详解
- java集合中HashMap原理详解
- java基础--HashMap解决hash冲突的方法
- Java集合之HashMap用法详解
- java 解决Hash(散列)冲突的四种方法--开放定址法(线性探测,二次探测,伪随机探测)、链地址法、再哈希、建立公共溢出区
- java中散列表、树所对应的的容器类。HashMap如何解决冲突
- java_集合体系之HashMap详解、源码及示例——09
- java集合中HashMap原理详解
- Java 8中HashMap冲突解决
- 【JAVA集合详解】HashMap
- Java集合之HashMap详解
- 【JAVA集合详解】Java ConcurrentModificationException异常原因和解决方法
- java 中HashMap解决hash冲突问题
- 【Java基础之集合(二)】Java中HashMap详解
- Java集合:HashMap使用详解及源码分析
- Java 8中HashMap冲突解决
- java集合13--WeakHashMap源码详解