Python3+scrapy 爬取喜马拉雅音乐 音乐和歌名 最简单的爬虫
2019-03-17 14:02
417 查看
初学scrapy并爬取 喜马拉雅音乐想和大家分享分享
- 一 、分析数据
- 二 、分析完啦 话不多说 给各位看官上代码!
- 具体代码如下
- 这就是一个简单的爬虫爬取 喜马拉雅的歌曲 👋 本人仍在继续爬着!!!!!!
- 详细项目代码见gitup https://github.com/kong11213613/python3-
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
一 、分析数据
1 https://www.ximalaya.com/yinyue/liuxing/p1/ 这个网址就是我们要爬取的的喜马拉雅网址
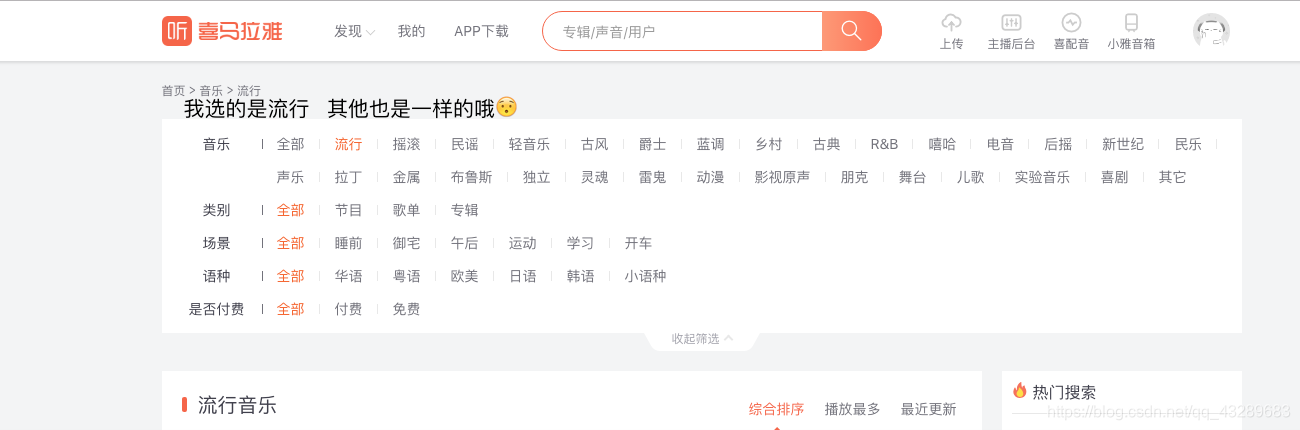
2 是要点击右键分析数据 你可以看到
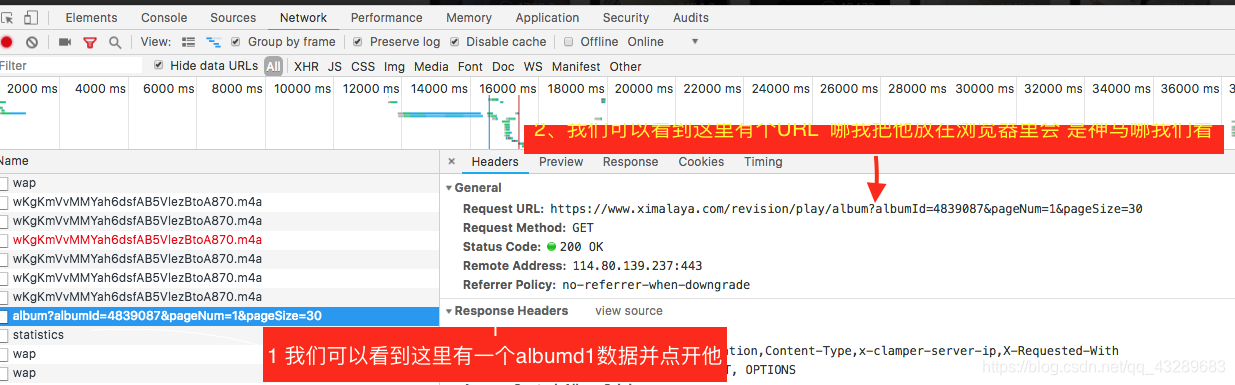
3. 我把这个地址打开以后就会发现 这是json数据
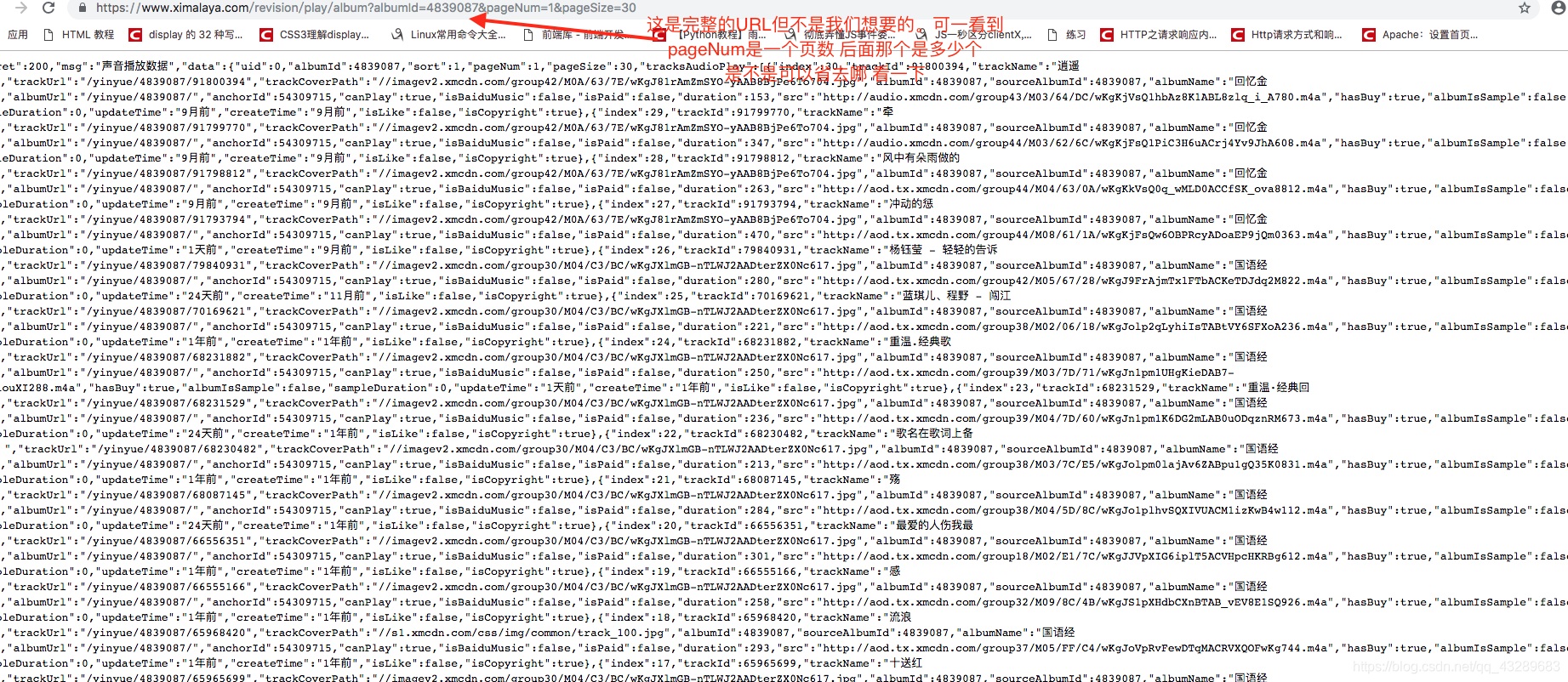
4、我们看一下去掉会是什么样子

5 看到那个后面的id 我还好像在哪见过那 对啦就是在

6 简单的分析结束啦 开始我们的代码之旅吧!
二 、分析完啦 话不多说 给各位看官上代码!
1、这是我们需要的模块 需要引一下 import scrapy import re import json import requests
2
创建一个类并继承 最初的爬虫类 并在start_urls 里添加最初的URL 并将结果交给 parse 函数
class www_ximalaya_com(scrapy.Spider): name = "www_ximalaya_com" start_urls = [ "https://www.ximalaya.com/yinyue/liuxing/p1/" ]
3 接到 网页数据之后 开始解析我们要的 首先是 每个歌曲集合 的id 还有 下一页的 URL 并将获取的数据传到要掉用的parses 函数
页的URL 返回给本身 并进行下一次爬取
def parse(self, response):
"""
该函数负责提取下一页的a链接 并提取歌曲集合的id
拼接url 获取json数据
:param response: 将数据返回给回调函数 parses
:return:
"""
#提取下一页的href 数据 '/yinyue/liuxing/p2/'
a = response.css("li.page-next a.page-link::attr(href)").extract()[0]
#拼接下一页的url
a = "https://www.ximalaya.com" + a
#提取歌曲集合的a链接的href 并进行正则提取id /yinyue/460941/ 这是一个 列表
nums = response.css(" div.album-wrapper-card a::attr(href)").extract()
# 循环列表进行正则和 拼接URL
for val in nums:
# 正则提取id 460941
s = re.search("\d+",val,re.S)
numd = s.group()
#拼接URL
url = "https://www.ximalaya.com/revision/play/album?albumId=" + numd
#发起请求并移交给回调函数 parses
yield scrapy.Request(url,callback=self.parses)
#页数
count = 2
#循环页数
while count <= 34:
#拼接下一页的URL
url = "https://www.ximalaya.com/yinyue/liuxing/p%d/" % count
# 发去请求并移交给本身
yield scrapy.Request(url,callback=self.parse)
count += 1
4 接到 parses 函数的调用时 解析 json数据 并保存文件
def parses(self,response):
"""
该函用于解析 数据 提取数据 发起请求获取数据
并将音乐保存在文件当中
:param response:
:return:
"""
# 获取数据
jsons = response.text
#解析json数据
jslod = json.loads(jsons)
#循环数据
for val in jslod["data"]["tracksAudioPlay"]:
#获取URL
url = val["src"]
#获取歌名
name = val["trackName"]
file_name = val["albumName"]
lists = []
#设置列表
lists.append(file_name)
lists.append(url)
lists.append(name)
# #判断 URL是否为None
if lists[1] != None:
判断目录是否存在
if os.path.isdir(lists[0]) == False:
#不存在就创建目录
os.mkdir(lists[0])
#目录写入文件
with open("./"+ lists[0] + "/" + lists[2] + ".mp3", "wb+") as f:
#发起URL请求并获取内容
r = requests.get(lists[1])
#写入文件
f.write(r.content)
#生成错误日志
self.log("保存文件" + name)
else:
#如果存在直接打开目录写入文
with open("./" + lists[0] + "/" + lists[2] + ".mp3", "wb+") as f:
# 发起URL请求并获取内容
r = requests.get(lists[1])
# 写入文件
f.write(r.content)
# 生成错误日志
self.log("保存文件" + name)
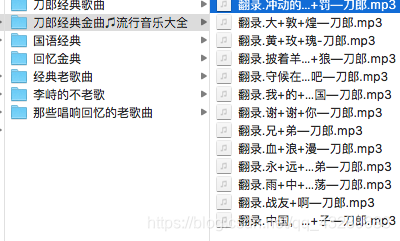
5
结果就是这样的 分目录存放
具体代码如下
import scrapy
import re
import json
import requests
import os
class www_ximalaya_com(scrapy.Spider):
name = "www_ximalaya_com"
start_urls = [
"https://www.ximalaya.com/yinyue/liuxing/p1/"
]
def parse(self, response):
"""
该函数负责提取下一页的a链接 并提取歌曲集合的id
拼接url 获取json数据
:param response: 将数据返回给回调函数 parses
:return:
"""
#提取下一页的href 数据 '/yinyue/liuxing/p2/'
a = response.css("li.page-next a.page-link::attr(href)").extract()[0]
#拼接下一页的url
a = "https://www.ximalaya.com" + a
#提取歌曲集合的a链接的href 并进行正则提取id /yinyue/460941/ 这是一个 列表
nums = response.css(" div.album-wrapper-card a::attr(href)").extract()
# 循环列表进行正则和 拼接URL
for val in nums:
# 正则提取id 460941
s = re.search("\d+",val,re.S)
numd = s.group()
#拼接URL
url = "https://www.ximalaya.com/revision/play/album?albumId=" + numd
#发起请求并移交给回调函数
yield scrapy.Request(url,callback=self.parses)
# 页数
count = 2
#循环页数
while count <= 34:
#拼接下一页的URL
url = "https://www.ximalaya.com/yinyue/liuxing/p%d/" % count
# 发去请求并移交给本身
yield scrapy.Request(url,callback=self.parse)
count += 1
def parses(self,response):
"""
该函用于解析 数据 提取数据 发起请求获取数据
并将音乐保存在文件当中
:param response:
:return:
"""
# 获取数据
jsons = response.text
#解析json数据
jslod = json.loads(jsons)
#循环数据
for val in jslod["data"]["tracksAudioPlay"]:
#获取URL
url = val["src"]
#获取歌名
name = val["trackName"]
file_name = val["albumName"]
lists = []
#设置列表 将歌曲集合 URL 歌名 追加进列表
lists.append(file_name)
lists.append(url)
lists.append(name)
# #判断 URL是否为None
if lists[1] != None:
#打开文件
if os.path.isdir(lists[0]) == False:
os.mkdir(lists[0])
with open("./"+ lists[0] + "/" + lists[2] + ".mp3", "wb+") as f:
#发起URL请求并获取内容
r = requests.get(lists[1])
#写入文件
f.write(r.content)
#生成错误日志
self.log("保存文件" + name)
else:
with open("./" + lists[0] + "/" + lists[2] + ".mp3", "wb+") as f:
# 发起URL请求并获取内容
r = requests.get(lists[1])
# 写入文件
f.write(r.content)
# 生成错误日志
self.log("保存文件" + name)
这就是一个简单的爬虫爬取 喜马拉雅的歌曲 👋 本人仍在继续爬着!!!!!!
详细项目代码见gitup https://github.com/kong11213613/python3-

相关文章推荐
- Python3简单爬虫之下载相关类型音乐(喜马拉雅网站)
- Python的Scrapy爬虫框架简单学习笔记
- [Python]使用Scrapy爬虫框架简单爬取图片并保存本地
- 用Python在喜马拉雅音乐爬虫小试
- Python爬虫 --- 2.3 Scrapy 框架的简单使用
- Python 爬虫 正则抽取网页数据和Scrapy简单使用
- python+selenium+scrapy搭建简单爬虫
- Python之Scrapy爬虫框架安装及简单使用
- python scrapy简单爬虫记录(实现简单爬取知乎)
- python scrapy爬虫简单安装使用
- Python爬虫-scrapy框架简单应用
- python3+scrapy简单爬虫入门
- Python爬虫系列之----Scrapy(四)一个简单的示例
- python+selenium+scrapy搭建简单爬虫
- Python Scrapy简单爬虫-爬取澳洲药店,代购党的福音
- 运维学python之爬虫高级篇(二)用Scrapy框架实现简单爬虫
- Python之Scrapy爬虫框架安装及简单使用
- Python的Scrapy爬虫框架简单学习笔记
- 使用Python的Scrapy框架编写web爬虫的简单示例
- Python之Scrapy爬虫框架安装及简单使用详解