[SQL99]数据库对表内数据的基本操作详解之DQL(数据查询语言)
首先介绍一下SQL的语言分类:
• DQL(数据查询语言)–即本文介绍,之后会写关于case when的额外知识
• select
• DML(数据操作语言)–博客地址:https://blog.csdn.net/a755199443/article/details/88599661
• insert、update、delete
• DDL(数据定义语言)
• create、alter、drop
• DCL(数据控制语言)–博客地址:https://blog.csdn.net/a755199443/article/details/88644069
• grant、revoke
• TCL(事务控制语言)
• SAVEPOINT 、ROLLBACK、SET TRANSACTION ,COMMIT
数据操作语言针对表中的数据,而数据定义语言针对数据库对象(表、索引、视图、触发器、存储过程、函数、表空间等)
今天要讲的是对数据库表中的数据进行CRUD基本操作中的读取查询(Retrieve) ,即DQL中的select.
这里还介绍一下几个意思互等的名称,我把用的较多的名称放"/"的前面:
关系/整个二维表
关系名/表格名称
记录/行数据/元组
字段/列数据/属性
字段名/列名称/属性名
好了,正文开始!
读取查询(Retrieve)
查询是增删改查中最复杂也是最难的,SQL语言全名为Structured Query Language(结构化查询语言),可见查询的重要性.
查询分为单表查询和多表查询还有子查询,我们从浅入深一步一步来,先从单表查询讲起.
先给出单表查询的语法结构(记得多回来看看):
select column[, group_function(column)]
from table
[where condition]
[group by group_by_expression]
[having group_condition]
[order by column];
执行过程:from–where – group by– select-having- order by
- select
select用于指定查询表格中的列信息.
*是通配符,表示所有列.
举例,显示students表中所有字段:
select * from students;

select后面一般接指定列名字.
举例,显示students表中学号和姓名字段:
select sno,sname from students;
支持算术运算和列别名
举例,显示将所有学生年龄加四后的结果,并将结果字段命名为olderage:
select sname,age+4 as olderage from students;
这里的[as]一般省略,想要使用数字/小写字母或特殊符号做别名时要用双引号括起来,直接用小写字母做别名会显示对应的大写字母.
- distinct
用于去除重复行信息
举例,查询学生中所有年龄(若有17岁学生30个,18岁学生40个,只显示两行,分别为17,18):
select distinct age from students;
可以增加不重复的字段名条件,用逗号隔开,如:
select distinct sname,age from students.
- 字符串连接符||
Oracle中, 用单引号表示字符串,注意字符串中大小写敏感.
SQL的||与java的+类似.
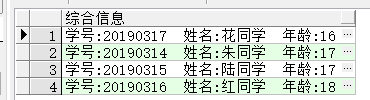
举例:显示学号+姓名+年龄
select '学号:'||sno||' 姓名:'||sname||' 年龄:'||age as 综合信息 from students;
- order by
用于进行排序, 永远写在语句的最后,同时永远也是最后执行,按照指定的字段排序:
order by 字段名 asc 为升序(默认为升序,所以asc一般省略不写)
order by 字段名 desc 为降序
举例,将students学生按年龄降序显示:
select * from students order by age desc;

- where子句
where用于对指定字段增加筛选条件,后面可以跟很多关键字,我们一个一个来,先介绍where的基本用法.
where最基本的用法就是在后面接等值或不等值条件.
举例,分别获得students表中年龄小于18的学生和姓名为朱同学的学生:
select * from students where age<18; select * from students where sname='朱同学';
- like
like用于模糊查询,搭配_和%使用,通配符 _表示一个任意字符 %表示任意个任意字符.
举例,查询students表中名字带’朱’的同学:
select * from students where sname like '%朱%';
为了表示带有_或%的字符串需要使用转义符,escape用于声明转义符,举例如下:
select * from students where sname like 'a_朱' escape 'a';
- is null
判断是否为空值,举例,查询students表中没有填写年龄的学生(即年龄字段为null):
select * from students where age is null;
注意,不能写成age = null
判断非空有两种写法,举例:
select * from students where age is not null; select * from students where not age is null;
- and和or
and表示逻辑与,or表示逻辑或.and的优先级高于or的优先级,当然我们一般用小括号来控制运算顺序.
举例,查询students表中年龄为17,并且名字为朱同学的学生:
select * from students where age=17 and sname='朱同学';
查询students表中年龄为17,或者名字为朱同学/红同学的学生,这里还可以使用 in :
select * from students where age=17 or sname in ('朱同学','红同学');
- group by分组查询
分组查询是查询操作中的第一个难点.
首先介绍一下分组函数(又称多行函数),它对一组数据进行运算,针对一组数据(多行记录)只返回一个结果,分组函数与分组查询息息相关.
常用的分组函数有仅用于数值型:sum() avg() ,也有适用于任何类型:count() max() min() .
多行函数除了count(*)外,都跳过空值而处理非空值,可以用nvl()函数来处理空值.
开始介绍分组查询,语法为:
select column[, group_function(column)]
from table
[where condition]
[group by group_by_expression]
[having group_condition]
[order by column];
执行过程:from–where – group by– select-having- order by
分组查询中的select字段中出现的只能是组函数或分组条件如果要对组进行条件筛选,不能用where,因为sql的执行顺序group by 在where之后执行.
where在分组前筛选入组数据,having在分组后筛选组.
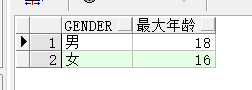
举例,获得students表中男女生中最大的年纪为多少(根据性别分组,获得最大年龄,因此select后只能跟gender字段和分组函数,这里为max()):
select gender , max(age) as "最大年龄" from students group by gender;
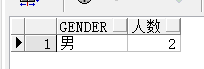
举例,获得students表中男女生中小于18岁的人的数量为多少,分组后组里的最小年龄不能低于17:
select gender,count(*) as "人数" fro 1c6f4 m students where age<18 group by gender having max(age)<=17;
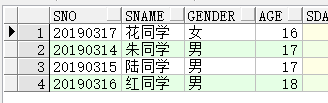
原本的数据表内容为:
select * from students;
单表查询的内容结束,开始介绍多表查询,多表查询又称为连接查询,语法如下:
select 字段列表
from table1
[cross join table2] – cross join 交叉连接
[natural join table2] – natural join 自然连接
[join table2 using (字段名)] – using子句
[join table2 on (table1.column_name = table2.column_name)]– on子句
[(left | right | full outer) join table2
on (table1.column_name = table2.column_name)]; – 左/右/满外连接查询
- cross join 交叉连接
Cross join产生了一个笛卡尔集,其效果等同于在两个表进行连接时未使用WHERE子句限定连
接条件,所以一般用where限定连接条件.
新建一张和性别有关的表status:
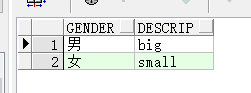
举例1,不用where限定条件,让students和statusj交叉连接在一起:
select s.sno,s.sname,s.age,s.gender,st.gender,st.descrip from students s cross join status st;
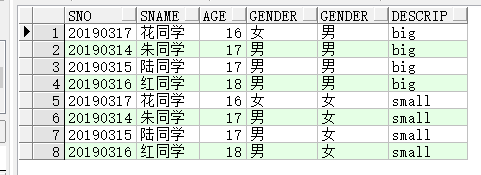
笛卡儿积就是两个集合X,Y,第一个对象是X的成员而第二个对象是Y的所有可能有序对.
这里性别不匹配的记录没有实际意义.
举例2,使用where限定条件,筛选性别一致的记录:
select s.sno,s.sname,s.age,s.gender,st.gender,st.descrip from students s cross join status st where s.gender=st.gender
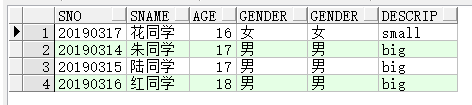
- natural join 自然连接
自然连接有两个特点:
1 在自然连接时, 自动进行所有同名列的等值连接, 不需要写连接的条件.
2 同名列只显示一列, 而且在使用时, 不能加表前缀.
举例,注意下面的gender前面不能加表前缀:
select s.sno,s.sname,s.age,gender,st.descrip from students s natural join status st
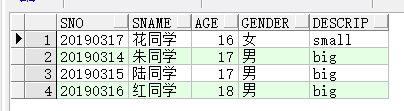
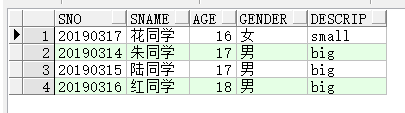
- using 子句
自然连接使用了所有的同名字段进行等值连接,有时候不希望这么做,可以在连接时使用USING子句,由于可能选用多个参照列,需要在参照列上加括号.
注意using子句引用的列和自然连接一样不能使用表名或者别名做前缀
举例:
select s.sno,s.sname,s.age,gender,st.descrip from students s join status st using (gender)
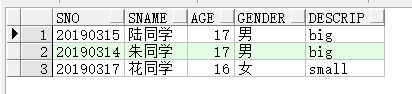
- on 子句
无论是自然连接还是on 子句,使用的都是等值连接,可以使用on子句来设置任意的连接条件或者指定连接的列,on后面的筛选条件也是需要加括号的,
on类似与where(其实在SQL92里现在on的位置使用的就是where)但是on用于给表连接指定筛选条件(即on要搭配join使用).
举例:
select s.sno,s.sname,s.age,s.gender,st.descrip from students s join status st on(s.gender=st.gender and age<18)
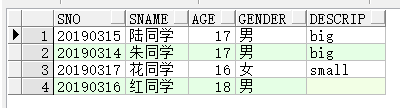
- left/right/full [outer] join 外连接
前面所讲的多表查询都是内连接,就是只显示连接成功的部分数据.而外连接除了能显示满足连接条件的数据以外, 还用于显示不满足连接条件的数据.左右表是通过相对于join的位置判断的,即在join左边的表名代表左表,右边的表名代表右表.
举例,显示上一张表中左表(students)未显示的记录:
select s.sno,s.sname,s.age,s.gender,st.descrip from students s left join status st--只在这一行的最前面加了一个left on(s.gender=st.gender and age<18)
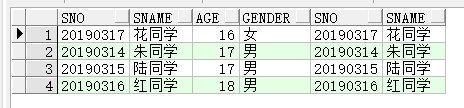
- 自连接
通过重命名一张表两次,可以看作有两张一样的表,那么这两张一样的表之间同样可以使用多表连接查询.
举例:
select s1.sno,s1.sname,s1.age,s1.gender,s2.sno,s2.sname from students s1 join students s2 on(s1.sno=s2.sno)
多表查询的内容到此结束,在多表内容的基础上,还有一种子查询的查询方式,功能非常强大,快让我们一探究竟吧.
子查询
当一次查询的结果是另一次查询所需要的时候, 可以使用子查询,语法格式如下:
select 字段列表from table
where 表达式operator (select 字段列表from table);
子查询的特点:
- 子查询在主查询前执行一次;
- 主查询使用子查询的结果.
子查询的注意事项:
- 在查询是基于未知值时应考虑使用子查询;
- 子查询必须包含在括号内;
- 建议将子查询放在比较运算符的右侧,以增强可读性;
- 除非进行Top-N 分析,否则不要在子查询中使用ORDER BY 子句;
- 如果子查询返回单行结果,则为单行子查询,可以在主查询中对其使用相应的单行记录
比较运算符; - 如果子查询返回单行结果,则为单行子查询,可以在主查询中对其使用相应的单行记录
比较运算符.
子查询分为单行子查询和多行子查询,相关子查询和不相关子查询.
- 单行子查询
当子查询的返回结果是单行数据时,即为单行子查询.
因为自己创建的students表太过单薄,因此需要借用Oracle数据库"SCOTT"账号中的emp表举例.
a) 查询所有比“CLARK”工资高的员工的信息
select * from emp where sal > (select sal from emp where ename='CLARK');
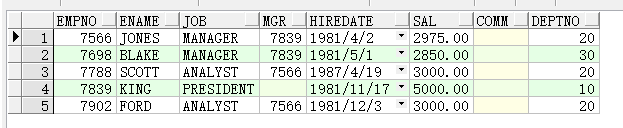
b) 查询工资高于平均工资的雇员名字和工资
select ename, sal from emp where sal>(select avg(sal)from emp);
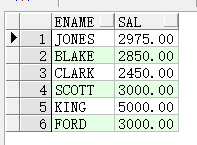
c) 查询和SCOTT同一部门且比他工资低的雇员名字和工资
select ename, sal, deptno from emp where deptno=(select deptno from emp where ename='SCOTT') and sal<(select sal from emp where ename='SCOTT');
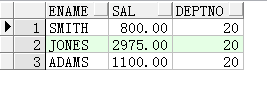
此时括号部分 (select 字段列表from table)可以简单的看作一个属性,可以在主查询中对其使用相应的单行记录比较运算符(大于小于等于).
- 多行子查询
子查询的返回结果是多行数据时称为多行子查询,此时不能再使用普通的比较运算符了,需要用到多行记录比较符号:ANY(跟结果中的任何一个数据进行比较成功即可)/ALL(跟结果中的所有数据进行比较全部成功才行)/IN(等于结果中的任何一个)
举例,查询工资低于任何一个“CLERK”的工资的雇员信息:
select * from emp where sal<ANY(select sal from emp where job='CLERK') and job<>'CLERK';

查询工资比所有的“SALESMAN”都高的雇员的编号、名字和工资:
select empno, ename, sal from emp where sal>ALL(select sal from emp where job='SALESMAN');
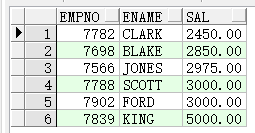
查询部门20中职务同部门10的雇员一样的雇员信息:
select * from emp where job in (select job from emp where deptno=10)and deptno=20;

- 相关子查询和不相关子查询
不相关子查询: 子查询不会用到外查询的数据, 子查询可以独立运行.
相关子查询: 子查询会用到外查询的数据, 子查询不能独立运行.
举例,查询每个部门最高工资的员工:
a) 使用相关子查询的方式
select * from emp e where sal=(select max(sal) from emp where deptno=e.deptno);

b)使用不相关子查询的方式
select * from emp e where (e.deptno, e.sal) in (select deptno, max(sal) from emp group by deptno);
额外的,一次查询的结果就可以看作一张新表,新表就可以和原有的表进行多表连接查询
举例,查询每个部门平均薪水的等级:
select t.deptno, t.avg_sal, s.grade from salgrade s join ( select deptno, avg(sal) avg_sal from emp group by deptno ) t on t.avg_sal between s.losal and s.hisal order by t.deptno;
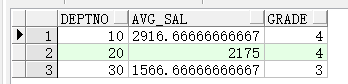
代码中的表salgrade是SCOTT账户中关于薪水等级的表.
查询语言的讲解到此结束,每种查询方式单拿出都不难,但是混合在一起就会让人头晕,这里就要多做题,我的博客中已经有SQL练习分类有大量经典题共同学们练手.

- Hadoop Hive sql语法详解4--DQL 操作:数据查询SQL
- Hadoop Hive sql语法详解4--DQL 操作:数据查询SQL
- Yii 框架里数据库操作详解-[增加、查询、更新、删除的方法 'AR一、查询数据集合
- Mysql的数据查询语言DQL之基本查询
- 【转】数据库基本知识:(十)数据操作 · 查 · (三)使用子查询访问和修改数据
- 009-Hadoop Hive sql语法详解4-DQL 操作:数据查询SQL-select、join、union、udtf
- Hadoop Hive sql语法详解--DQL 操作:数据查询SQL(4)
- JDBC实现数据库的几种基本操作(查询,分页查询,根据关键字进行查询以及插入数据)
- Hadoop Hive sql语法详解4--DQL 操作:数据查询SQL
- 数据库-编程语-SQL / 定义语言-DDL 数据进行定义 操作 查询 控制
- JDBC 数据库连接 创建表格、插入、查询、删除、修改数据 基本操作
- 数据库系统概论03-关系数据库标准语言SQL&模式、基本表、视图操作&连接、查询删改语句
- Hive基础(2): 数据类型、数据库、表、字段、交互式查询的基本操作
- 04.DQL(数据查询语言)基本操作上篇
- 学习Java6(六) 嵌入式数据库Derby(2)一个基本的例子(建数据库、建表、插入数据、查询)
- Oracle数据库数据操作和控制语言详解(精华)
- C# 对sharepoint 列表的一些基本操作,包括添加/删除/查询/上传文件给sharepoint list添加数据
- 使用PDF.NET数据开发框架的实体操作语言OQL构造复杂查询条件
- 数据库学习第四篇(对基本表数据的查询2)
- 【初识Oracle】③数据库对基本数据类型进行操作的函数