一文带你理解卷积神经网络(CNN),附代码实现与CNN网络训练基本概念讲解
在谈CNN之前,我们回顾一下BP神经网络,BP网络每一层节点是一个线性的一维排列状态,层与层的网络节点之间是全连接的,如果我们有100x100像素的图像,有1万个隐层神经元,每个隐层神经元都连接图像的每一个像素点,就有100x100x10000=10810^8108个连接,也就是10810^8108个权值参数,而如果我们隐藏层不止一层,那么权值参数数量是非常巨大的,这样不仅会使网络计算速度变慢,更有可能导致另一个问题:过拟合(overfitting)。我们设想一下,如果BP网络中层与层之间的节点连接不再是全连接,而是局部连接的。我们假设 每一个节点与上层节点同位置附近10x10的窗口相连接,则1万个隐层神经元就只有10000x100,即10610^6106个参数。其权值连接个数比原来减少了两个数量级,这样,就是一种最简单的一维卷积网络。如果我们把上述这个思路扩展到二维,这就是我们所说的卷积神经网络。除了层与层之间的节点连接是局部连接,卷积神经网络另外一个特性是权值共享(即同一个特征映射上的神经元使用相同的卷积核)。
1.卷积神经网络的结构与各组成部分介绍
卷积神经网络的总体结构如下图所示:
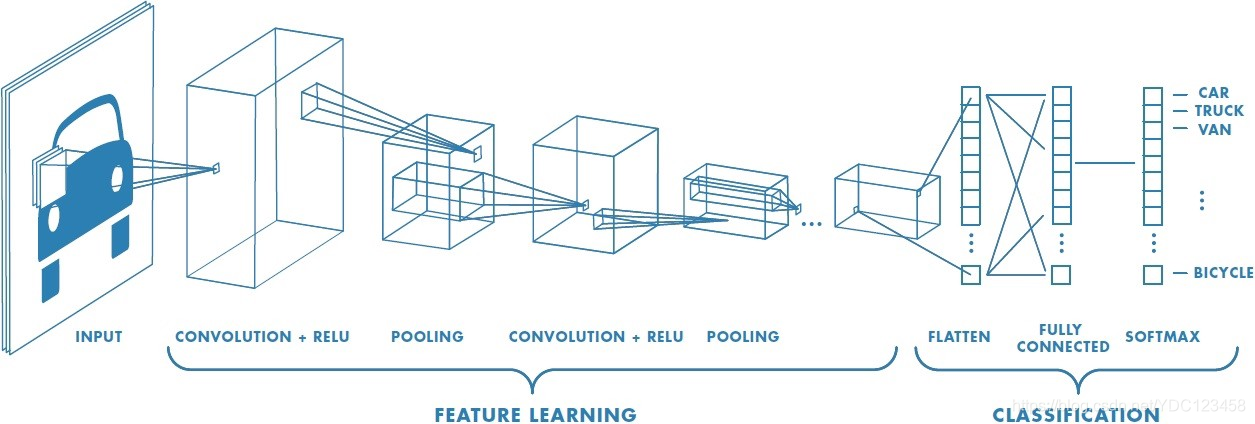
可以看到卷积神经网络一般包括以下几个部分(以常见的图像多分类为例):
(1)输入层(input layer)
图中是一个图形分类的CNN模型。可以看出最左边的图像就是我们的输入层,计算机理解为输入若干个矩阵。
(2)卷积层(Convolution Layer)
卷积层中每一个结点的输入只是上一层神经网络的一小块,这个小块常用大小有3x3、5x5、7x7等。在Resnet、Densenet、Inception、Fishnet等中也应用了非常实用的1x1卷积核,1*1的卷积可以实现多个特征通道线性叠加,在保存图片原有的平面结构的同时,完成升维或降维。一般来说,通过卷积层处理过的节点会使得矩阵变的更深。卷积层的激活函数一般使用的是ReLU,其实质就是ReLU(z)=max(0,z)。
卷积运算如下图所示:可以看出此处使用的卷积核为[101010101]\begin{bmatrix}1&0&1\\0&1&0\\1&0&1\\\end{bmatrix}⎣⎡101010101⎦⎤将卷积核与原图像矩阵进行卷积即可得到右图所示的结果,将此卷积核按照一定步长(stride)进行移动,可以看出此例子中步长为1,并且没有进行padding(填充),直到遍历完此图像矩阵。很多时候我们也会在卷积层中设置Padding,即是否填充像素。
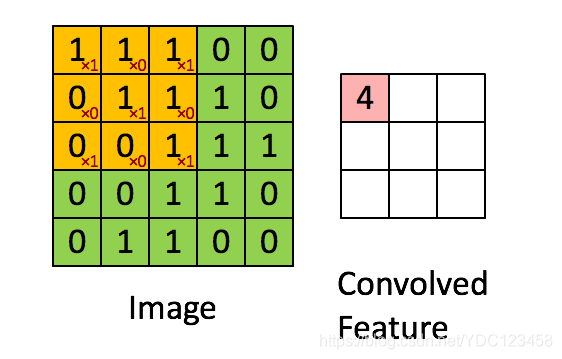
最终会得到下图所示的结果

(3)池化层(pooling layer)
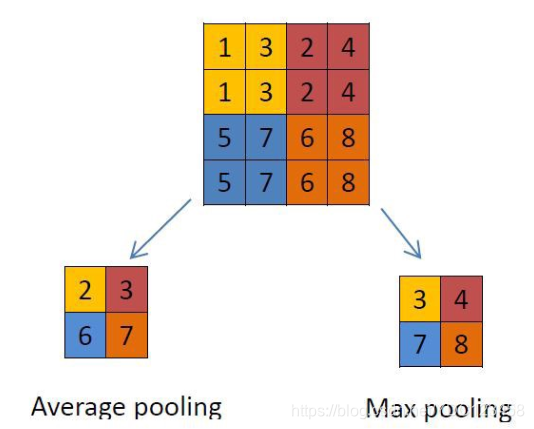
在卷积层后面是池化层(Pooling layer),他不会改变矩阵的深度,但是可以缩小矩阵的大小,从而达到减少整个网络中参数的目的。卷积层+池化层的组合可以在隐藏层出现很多次,这个次数是根据模型的需要而来的。当然我们也可以灵活使用使用卷积层+卷积层,或者卷积层+卷积层+池化层的组合,这些在构建模型的时候没有限制。但是最常见的CNN都是若干卷积层+池化层的组合,如上图中的CNN结构。池化最常用的有最大池化(Max Pooling)、最小池化(Min pooling)、平均池化(Average pooling),最大池化和平均池化如下图所示,可以看出此处所用的是2x2池化。池化层可以非常有效地缩小矩阵的尺寸,从而减少最后全连接层中的参数,加快计算速度的同时也有防止过拟合的作用
(4)全连接层(Fully Connected Layer)& Softmax层
在若干卷积层+池化层后面先是一个Flatten层,将所有学习到的进行展平,以便进行全连接(FC)。此处举例使用的输出层是Softmax激活函数,Softmax一般是来做图像识别的分类,其会计算每个目标类别在所有可能的目标类中的概率。计算出的概率将有助于确定给定输入的目标类别。使用Softmax的主要优点是输出概率的范围,范围为0到1,所有概率的和将等于1。如果将softmax函数用于多分类模型,它会返回每个类别的概率,并且目标类别的概率值会很大,这样即可判断出给定输入到底属于哪个类别,可以看出上图最终会分类出输入图像到底是汽车还是自行车等等。
Softmax原理
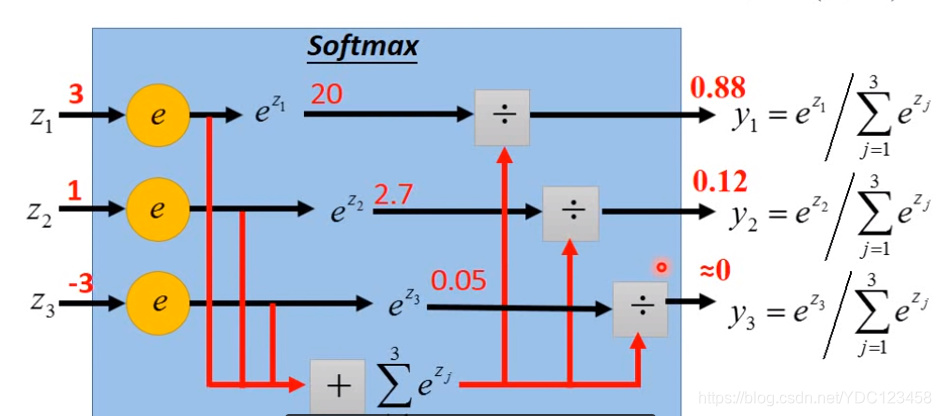
如图所示,每个经过激活函数后的Zi,都进行e^zi运算,然后进行归一化到0-1范围。
2.使用Keras搭建一个简单的CNN网络
我们使用最“有名”的MNIST手写数字数据集,利用Keras框架搭建卷积神经网络完成手写数字的识别
import keras
from keras.datasets import mnist
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense, Conv2D, Flatten, MaxPooling2D, Dropout
import matplotlib.pyplot as plt
(X_train, y_train), (X_test, y_test) = mnist.load_data() # 装载数据集
# reshape图片,MNIST数据集有60000张训练图片,10000张测试图片,图片大小均为28*28
X_train = X_train.reshape(60000, 28, 28, 1)
X_test = X_test.reshape(10000, 28, 28, 1)
#也可先对图片原始数据进行归一化
#X_train = X_train.astype('float32')
#X_test = X_test.astype('float32')
#X_train /= 255
#X_test /= 255
# 对label进行one-hot编码
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
##建立模型
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=(28,28,1))) #卷积层,使用32个核大小3*3的卷积,激活函数为Relu
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2))) #池化层
model.add(Dropout(0.25)) #Dropout即随机丢弃掉一些权重值,可以防止网络过拟合
model.add(Flatten()) #由于有太多维度,使用Flatten进行展平
model.add(Dense(128, activation='relu')) #全连接层
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax')) #共有数字0-9共10类
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy']) #选择损失函数和优化算法,评价指标选择准确率
batch_size = 128 #每次训练送入的Batch大小
num_epoch = 10 #共进行10个epoch
model_log = model.fit(X_train, y_train,
batch_size=batch_size,
epochs=num_epoch,
verbose=1,
validation_data=(X_test, y_test)) #进行模型训练
score = model.evaluate(X_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
# 绘制训练与验证结果
fig = plt.figure()
plt.subplot(2, 1, 1)
plt.plot(model_log.history['acc'])
plt.plot(model_log.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='lower right')
plt.subplot(2, 1, 2)
plt.plot(model_log.history['loss'])
plt.plot(model_log.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper right')
plt.tight_layout()
模型的准确率和损失如下图所示,可以看出测试集的损失从第一个epoch开始就已经很低,准确率也高达90%,而模型在第8个epoch时有略微的抖动(epoch标号为0-9)。
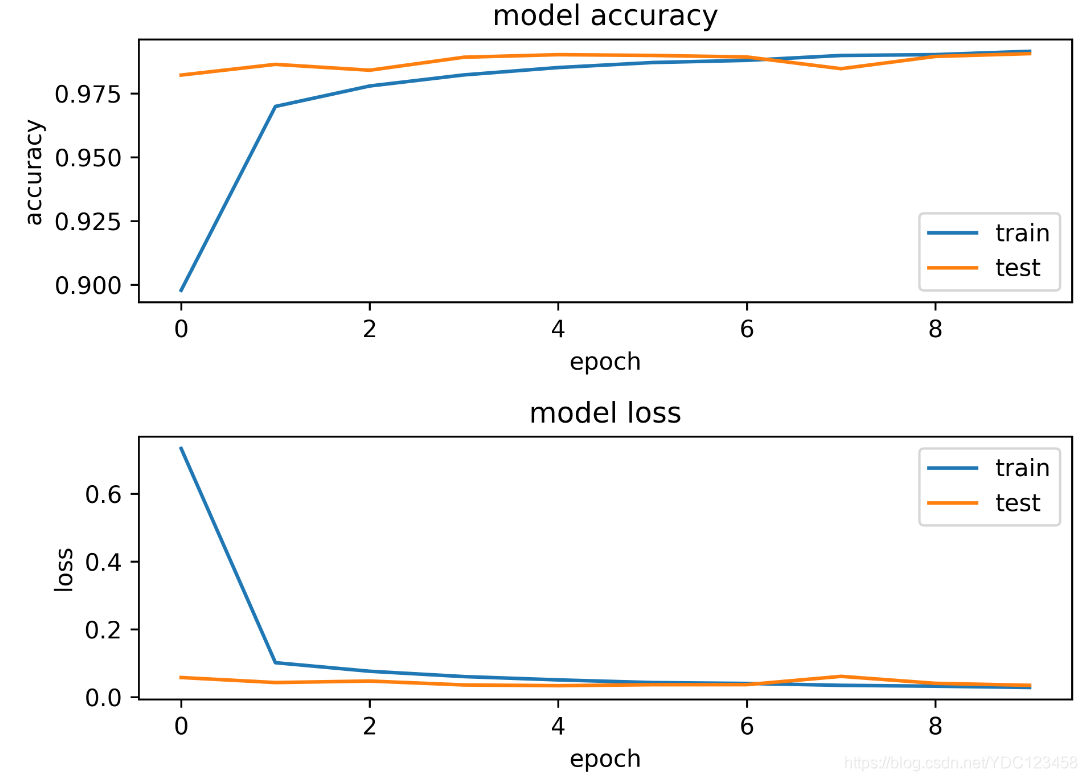
模型最终测试的准确率为99.06%,可以看出此CNN模型在MNIST数据集上是表现比较好的。

解释一下一些基本概念:
epoch:当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一个 epoch。
为什么要使用多于一个 epoch?
在神经网络中传递完整的数据集一次是不够的,我们需要将完整的数据集在同样的神经网络中传递多次。随着 epoch 数量增加,神经网络中的权重的更新次数也增加,曲线从欠拟合变得过拟合。
几个 epoch 才是合适的呢?
不幸的是,这个问题并没有正确的答案。对于不同的数据集,答案是不一样的,但是数据的多样性会影响合适的 epoch 的数量。这些需要根据实际问题来进行调整。
Batch_Size:批大小。在深度学习中,一般采用SGD训练,即每次训练在训练集中取Batch_Size个样本训练
Batch_Size的选择:
相对于正常数据集,如果Batch_Size过小,训练数据就会非常难收敛,从而导致underfitting。
适当的增加Batch_Size的优点:
1.通过并行化提高内存利用率。
2.单次epoch的迭代次数减少,提高运行速度。
3.适当的增加Batch_Size,梯度下降方向准确度增加,训练震动的幅度减小。
但是Batch_Size也不能过大,随着Batch_Size增大,所需内存容量增加,epoch的次数需要增加以达到最好的结果。会导致耗时增加从而速度下降。因此我们需要寻找比较好的Batch_Size,这个参数也是需要根据实际问题需要来进行调整。
可以看出Batch_Size的正确选择是为了在内存效率和内存容量之间寻找最佳平衡。
iteration:1个iteration等于使用batchsize个样本训练一次
举个例子,训练集有1000个样本,batchsize=10,那么训练完整个样本集需要:100次iteration,1次epoch。
优化算法:
代码中提到的优化算法可选择很多种,SGD、Adagrad、Adam、RMSprop等等, 还有最近北大本科生提出的AdaBound(被称像 Adam一样快,又像 SGD一样好的优化器)。感兴趣的可以对这些算法进入深入了解,推荐阅读此文章基于梯度的优化算法,AdaBound原文链接

- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)概念区分理解
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)概念区分理解
- 卷积神经网络(CNN)的训练及代码实现
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)概念区分理解
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)概念区分理解
- python网络爬虫——基本概念及代码实现1
- 卷积神经网络(CNN)的训练及代码实现
- Deep Learning论文笔记之(五)CNN卷积神经网络代码理解
- CNN卷积神经网络应用于人脸识别(详细流程+代码实现)
- 基于matlab的卷积神经网络(CNN)讲解及代码
- DeepLearning tutorial(5)CNN卷积神经网络应用于人脸识别(详细流程+代码实现)
- DeepLearning tutorial——CNN卷积神经网络应用于人脸识别(详细流程+代码实现)
- 深度学习之卷积神经网络CNN及tensorflow代码实现示例
- 卷积神经网络(CNN)的理解和实现
- Deep Learning论文笔记之(五)CNN卷积神经网络代码理解
- 深入理解Neutron -- OpenStack网络实践:概述和基本概念
- DeepLearning tutorial(5)CNN卷积神经网络应用于人脸识别(详细流程+代码实现)
- tensorflow训练cnn网络实现避障与导航(二)V-rep仿真环境的搭建
- 深度学习之卷积神经网络CNN及tensorflow代码实现示例
- Deep Learning论文笔记之(五)CNN卷积神经网络代码理解