史上最简单的spark教程第三章-深入Java+spark案例,理解RDD分布式数据集
2019-03-13 15:45
309 查看
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/youbitch1/article/details/88534173
比如:filter操作[筛选一个RDD元素中包含python的]
示例
其次再输出errorRDD的内容
拆解完后开始编码:代码如下:[在之前的示例代码后追加]
RDD的深入操作和概念(弹性分布式数据集)
史上最简单的spark教程
所有代码示例地址:https://github.com/Mydreamandreality/sparkResearch
(提前声明:文章由作者:张耀峰 结合自己生产中的使用经验整理,最终形成简单易懂的文章,写作不易,转载请注明)
(文章参考:Elasticsearch权威指南,Spark快速大数据分析文档,Elasticsearch官方文档,实际项目中的应用场景)
(帮到到您请点点关注,文章持续更新中!)
Git主页 https://github.com/Mydreamandreality
- 可以发现我们之前的spark程序和java+spark程序都是围绕着sparkcontext和RDD来进行操作的
- RDD是spark对数据的核心抽象(分布式的元素集合,结合之前的java案例就很好理解)
- 在spark中,对于数据的操作,基本是创建RDD.转换RDD.使用RDD操作进行数据的计算,而spark的作用就是自动将RDD的数据分发到集群上,将操作并行化执行(在第二章有提到过)
-
RDD的基础概念
- Spark 中的 RDD 就是一个不可变的分布式对象集合
- 每个RDD都被分为多个分区,这些分区运行在集群中的不同节点上
- RDD 可以包含 Python、Java、Scala 中任意类型的对象
-
创建RDD的方式: [两种]
第一种:读取一个外部的数据集(就是我们之前读取文本文件作为RDD的案例) sparkContext.textFile("/usr/local/data").cache();- 第二种:在驱动器程序中分发驱动器程序中的集合
操作RDD的方式: [两种]
-
第一种: 转化操作
转化操作会由一个RDD生成一个新的RDD
val lines = sc.textFile("你的README文件路径")
val pythonLines = lines.filter(line => line.contains("Python"))
//可以看到我们把包含python的RDD元素生成了新的RDD
- 第二种: 行动操作 行动操作会把计算完的RDD新结果返回到驱动器程序中,或者存储到外部系统,比如HDFS中.
- 比如:first操作[获取第一条记录]
- 示例
val lines = sc.textFile("/usr/local/spark/spark-2.2.3-bin-hadoop2.7/README.md")
lines.first()
总结:转化操作和行动操作的区别在于 Spark 计算 RDD 的方式不同
如果对于一个特定的函数是属于转化操作还是行动操作感到困惑,可以看看它的返回值类 型:转化操作返回的是RDD,行动操作返回的是其他的数据类型
以上说了一些RDD的基本概念,这里就基于以上的概念衍生一些代码示例
先搞一个转化操作的Java示例吧:
- RDD 的转化操作是返回新 RDD 的操作
- 那我们可以这么搞个示例:
- 需求:
- 假如我现在有一个日志文件log,内容是服务器运行的日志,那么需求就是: 我们先搞个简单点的需求,后续再慢慢深入
- 筛选所有的异常日志
- 那么ok,在开始编码前我们先拆解需求:
- 首先创建log的RDD,[现在log就是外部的数据集]
- 其次筛选数据,使用filter函数
- 最后返回新的RDD元素 [新的元素指的就是异常日志]
- 思路清晰后就可以开始编码了
- 代码示例如下:
//........省略初始化sparkContext
JavaRDD<String> inputRDD = sparkContext.textFile("/usr/local/log");
JavaRDD<String> errorRDD = inputRDD.filter(new Function<String, Boolean>() {
@Override
public Boolean call(String s) throws Exception {
return s.contains("error");
}
});
至此非Error的日志就被清洗,Error的日志生成新的RDD
需要注意的是:
filter() 操作不会改变已有的 inputRDD中的数据,该操作会返回一个全新的RDD,在我们的案例中叫做errorRDD,inputRDD在后面的程序中还可以继续使用,比如我们还可以在inputRDD中清洗warning的日志
运行的流程图如下:
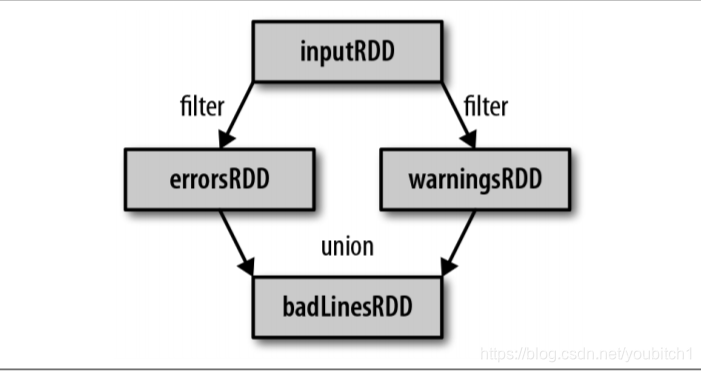
再搞一个行动操作的Java示例吧:
-
刚才我们做的是RDD转换操作.但是我们这个时候又新加了一个需求
-
[又加需求?先杀个产品祭天]
-
新加的需求为
统计error日志出现的次数,并且查看一下这些日志的内容
那么我们还是拆解该需求
-
首先需要对errorRDD进行count()的统计
long errorRDDCount = errorRDD.count();
System.out.println("errorRDD 的总数为: "+errorRDDCount);
for (String rddLine:errorRDD.take(10)){
System.out.println("errorRDD的数据是:"+rddLine);
}
- 我们在驱动器程序中使用 take() 获取了RDD中的少量元素,然后在本 遍历这些元素,并在驱动器端打印出来.RDD 还有一个collect()函数,可以用来获取整个RDD中的数据
- 但是只有当你的整个数据集能在单台机器的内存中放得下时,才能使用collect(),因为这些数据一般都很大,所以通常把数据写入HDFS等其他的分布式文件存储系统中,使用的函数为:
saveAsTextFile()、saveAsSequenceFile(),这个第二章java案例中有使用
理论补充点 [较为重要※],此处参考spark官方文档和书籍:
- 惰性求值
- RDD的转化操作都是惰性求值的,这意味着在被调用行动操作之前Spark不会开始计算
- 这意味着我们在执行map(),filter()等转换操作的时候不会立即执行,spark会先记录需要操作的相关信息,所以我们在调用sparkcontext.textfile(文件路径)时,数据并没有被读取,而是在必要时进行读取的
- 虽然转化操作是惰性求值的,但还是可以随时通过运行一个行动操作来强制Spark执行RDD 的转化操作.比如使用count().方便我们进行测试
今天整理了一下spark+java一些深入的案例
下一章节会整理好分享出来的,
有什么问题可以留言一块交流学习.

相关文章推荐
- 史上最简单的spark教程第五章-阶段性总结SparkJavaApi,RDD分布式数据集
- 史上最简单的spark教程第六章-键值对RDD聚合,分组,统计的Java案例实践-(上集)
- 史上最简单的spark教程第六章-键值对RDD聚合,分组,统计的Java案例实践-(下集)[核心基础完结篇章]
- 史上最简单的spark教程第八章-spark的自定义累加器与广播变量Java案例实践
- 史上最简单的spark教程第四章-Java操作SaprkApi常用案例大集合
- 史上最简单的spark教程第七章-spark的数据读取与保存Java案例实践
- 史上最简单的spark教程第十章-SparkSQL编程Java案例实践(二)
- 史上最简单的spark教程第九章-SparkSQL编程Java案例实践(一)斗图王来辣
- Hive数据分析——Spark是一种基于rdd(弹性数据集)的内存分布式并行处理框架,比于Hadoop将大量的中间结果写入HDFS,Spark避免了中间结果的持久化
- Spark 基础学习第一讲:弹性分布式数据集RDD
- Spark弹性分布式数据集RDD详解
- 深入理解Java虚拟机JVM高级特性与最佳实践阅读总结——第三章垃圾收集器与内存分配策略
- 深入理解Spark的RDD
- Spark(三):弹性分布式数据集(RDD)
- 深入理解Spark 2.1 Core (一):RDD的原理与源码分析
- 3.Java高级教程_深入理解Java并发之synchronized实现原理
- Spark - RDD(弹性分布式数据集)
- 简单工厂-工厂方法-抽象工厂对比,给出理解思路和Java参考案例源码
- 深入理解Java注解(含案例分析)
- [Spark]Spark RDD 指南三 弹性分布式数据集(RDD)