神经网络基础
基本概念:
输入层(Input layer),众多神经元(Neuron)接受大量非线形输入消息。输入的消息称为输入向量。
输出层(Output layer),消息在神经元链接中传输、分析、权衡,形成输出结果。输出的消息称为输出向量。
隐藏层(Hidden layer),简称“隐层”,是输入层和输出层之间众多神经元和链接组成的各个层面。隐层可以有一层或多层。隐层的节点(神经元)数目不定,但数目越多神经网络的非线性越显著,从而神经网络的强健性(robustness)(控制系统在一定结构、大小等的参数摄动下,维持某些性能的特性)更显著。习惯上会选输入节点1.2至1.5倍的节点。
前馈神经网络:
是一种最简单的神经网络,各神经元分层排列。每个神经元只与前一层的神经元相连。接收前一层的输出,并输出给下一层.各层间没有反馈。是目前应用最广泛、发展最迅速的人工神经网络之一。
常见的前馈神经网络有:
感知器网络
感知器(又叫感知机)是最简单的前馈网络,它主要用于模式分类,也可用在基于模式分类的学习控制和多模态控制中。感知器网络可分为单层感知器网络和多层感知器网络。
BP网络
BP网络是指连接权调整采用了反向传播(Back Propagation)学习算法的前馈网络。与感知器不同之处在于,BP网络的神经元变换函数采用了S形函数(Sigmoid函数),因此输出量是0~1之间的连续量,可实现从输入到输出的任意的非线性映射。
RBF网络
RBF网络是指隐含层神经元由RBF神经元组成的前馈网络。RBF神经元是指神经元的变换函数为RBF(Radial Basis Function,径向基函数)的神经元。典型的RBF网络由三层组成:一个输入层,一个或多个由RBF神经元组成的RBF层(隐含层),一个由线性神经元组成的输出层。
正则化:
正则化定义为“对学习算法的修改——旨在减少泛化误差而不是训练误差”。
目前有许多正则化策略。 有些策略向机器学习模型添加限制参数值的额外约束。 有些策略向目标函数增加额外项来对参数值进行软约束。 有时侯,这些约束和惩罚被设计为编码特定类型的先验知识; 其他时候,这些约束和惩罚被设计为偏好简单模型,以便提高泛化能力。 有时,惩罚和约束对于确定欠定的问题是必要的。 其他形式的正则化,如被称为集成的方法,则结合多个假说来解释训练数据。
参数惩罚:
在神经网络中,参数包括每一层仿射变换的权重和偏置,我们通常只对权重做惩罚而不对偏置做正则惩罚。 精确拟合偏置所需的数据通常比拟合权重少得多。 每个权重会指定两个变量如何相互作用。 我们需要在各种条件下观察这两个变量才能良好地拟合权重。 而每个偏置仅控制一个单变量。 这意味着,我们不对其进行正则化也不会导致太大的方差。 另外,正则化偏置参数可能会导致明显的欠拟合。
数据集增强:
让机器学习模型泛化得更好的最好办法是使用更多的数据进行训练。 当然,在实践中,我们拥有的数据量是很有限的。 解决这个问题的一种方法是创建假数据并添加到训练集中。方式包括加入特定噪声(如高斯噪声),做一定的几何变换等等。
另一种正则化模型的噪声使用方式是将其加到权重,这项技术主要用于循环神经网络。 这可以被解释为关于权重的贝叶斯推断的随机实现。 贝叶斯学习过程将权重视为不确定的,并且可以通过概率分布表示这种不确定性。 向权重添加噪声是反映这种不确定性的一种实用的随机方法。
大多数数据集的yy标签都有一定错误。 错误的yy不利于最大化logp(y∣x)logp(y∣x)。 避免这种情况的一种方法是显式地对标签上的噪声进行建模。 例如,我们可以假设,对于一些小常数ϵϵ,训练集标记yy是正确的概率是1−ϵ1−ϵ,(以ϵϵ的概率)任何其他可能的标签也可能是正确的。 这个假设很容易就能解析地与代价函数结合,而不用显式地抽取噪声样本。 例如,标签平滑(label smoothing)通过把确切分类目标从0和1替换成ϵk−1ϵk−1和1−ϵ1−ϵ,正则化具有kk个输出的softmax函数的模型。 标准交叉熵损失可以用在这些非确切目标的输出上。 使用softmax函数和明确目标的最大似然学习可能永远不会收敛—— softmax函数永远无法真正预测0概率或1概率,因此它会继续学习越来越大的权重,使预测更极端。 使用如权重衰减等其他正则化策略能够防止这种情况。 标签平滑的优势是能够防止模型追求确切概率而不影响模型学习正确分类。
常用的神经元激活函数主要有以下几种:
sigmoid
tanh
ReLU
sigmoid非线性函数的数学公式是:
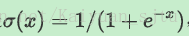
函数图像如下图所示。
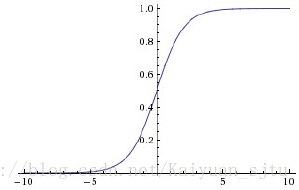
主要缺点:
(1)Sigmoid函数饱和使梯度消失。
(2)Sigmoid函数的输出不是零中心的。
tanh激活函数:由sigmoid修正得到
表达式: y=(ex−e−x)/(ex+e−x)
函数图像如下图所示:
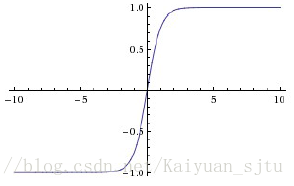
它的输出是零中心的
ReLu函数:
全称为Rectified Linear Units,函数表达式为y=max(0,x)。函数图像如下图所示:
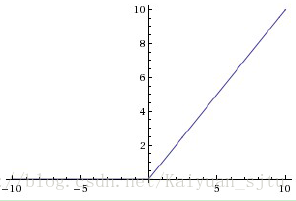
优点:
1、相较于sigmoid和tanh函数,ReLU对于随机梯度下降的收敛有巨大的加速作用。据称这是由它的线性,非饱和的公式导致的。
2、sigmoid和tanh神经元含有指数运算等耗费计算资源的操作,而ReLU可以简单地通过对一个矩阵进行阈值计算得到。
缺点:
在训练的时候,ReLU单元比较脆弱并且可能“死掉”。举例来说,当一个很大的梯度流过ReLU的神经元的时候,可能会导致梯度更新到一种特别的状态,在这种状态下神经元将无法被其他任何数据点再次激活。如果这种情况发生,那么从此所以流过这个神经元的梯度将都变成0。也就是说,这个ReLU单元在训练中将不可逆转的死亡,因为这导致了数据多样化的丢失。例如,如果学习率设置得太高,可能会发现网络中40%的神经元都会死掉(在整个训练集中这些神经元都不会被激活)。通过合理设置学习率,这种情况的发生概率会降低。
正则化:
在所有可能的模型中选择能够很好的解释数据且十分简单的模型。防止过拟合,提高泛化能力。
L1和L2正则都是比较常见和常用的正则化项,L1是绝对距离,L2是平方距离,都可以达到防止过拟合的效果。L1正则化的解具有稀疏性,可用于特征选择。L2正则化的解都比较小,抗扰动能力强。

- 一名工程师对于深度学习的理解-神经网络基础ANN
- 一名工程师对于深度学习的理解-神经网络基础ANN
- 神经网络基础知识
- 神经网络与深度学习学习笔记:numpy基础
- 循环神经网络(RNN) 基础详解
- 吴恩达深度学习入门学习笔记之神经网络和深度学习(第二周:神经网络基础)
- 人工神经网络基础
- 【直观理解】一文搞懂RNN(循环神经网络)基础篇
- 基于神经网络的机器学习基础
- 深度学习基础1(神经网络)
- MATLAB 神经网络基础(2)
- 神经网络入门基础文章
- 神经网络基础概念
- 神经网络基础算法
- 神经网络理论基础及Python实现详解
- 吴恩达《深度学习工程师》Part1.Week2 神经网络基础
- Tensorflow基础知识与神经网络构建--step by step 入门TensorFlow(一)
- [置顶] 无人驾驶汽车系统入门(九)——神经网络基础
- 深度学习基础模型算法原理及编程实现--04.改进神经网络的方法
- 神经网络的理论基础