深度学习常见主流经典算法概述(一)(从k近邻,线性分类器,SVM,神经网络讲起)
一、概述
CNN主要发展过程可由下图所示。(下图来自刘昕博士)《CNN的近期进展与实用技巧》。
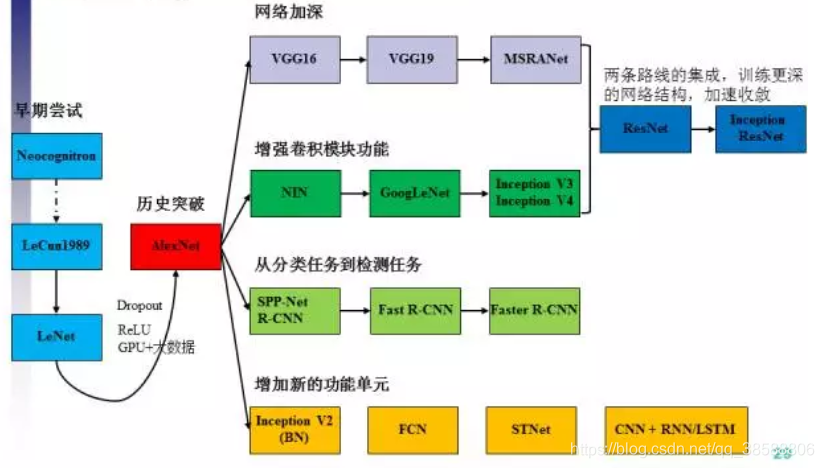
本文的目的不止于此,本文将深入理解CNN的四大类应用:图像分类模型,目标检测模型,语义分割模型,语义slam模型:
图像分类模型叙述步骤如下:CNN之前模型->leNet->AlexNet->VGG16系列->MSRANet->GoogLeNet->Inception系列->ResNet系列->Inception-Resnet系列->SENet。
目标检测模型叙述步骤如下:大致思路->RCNN->FastRCNN->FasterRCNN->SSD->YOLO家族->MASK-RCNN。
语义分割模型叙述步骤如下:大致思路->FCN->SegNet->MSAC->CRFs->MPRN->PSPNet->GCN->ASPP->FCIS.
语义slam模型叙述步骤如下:大致思路->CNN-SLAM->DenseSLAM->VSSLAM->OSS->LCS->RKS->MOSLAM->SF->PUSLAM->MFES->DELS->DEEPVO。
本人的研究方向主要在SLAM上,故整篇主题都是为语义slam服务的。
二、图像分类模型
本部分叙述步骤如下:CNN之前模型->leNet->AlexNet->VGG16系列->MSRANet->GoogLeNet->Inception系列->ResNet系列->Inception-Resnet系列->SENet。
2.1、CNN之前的模型
之前我们在做图像分类的时候,常用K近邻,SVM等,即一些传统机器学习的方法。
2.1.1 K近邻
说白了举一个简单的例子,假定我们有两张图片,一张是猫的,一张是狗的:


然后我们有另外1000张图片,我想知道这些图片里显示的是猫还是狗,很简单,比方说,我拿出了一张图片,我们知道图片是由像素组成的,表示为一个矩阵,RGB图片,可以是一个三维矩阵,每一维度的(x,y)表示的是这个点在图片什么位置,而这三维分别表示(R,G,B)的值,我们拿最简单的方法来说,我直接让每个点的像素值(RGB)分别与已经确定是猫的图片的每个像素值(RGB)做欧式距离后相加,得到一个数,同样的,我们让该图片对狗也做这样的处理,也得到一个数。比较这两个值,哪个大就把这张图片归为哪类。欧式距离如下定义:

那后来肯定有改进,比如马氏距离,对图像某些点我们看的更重要些,这就需要度量矩阵了,你可以把它化简即可发现M矩阵是每个点的权重,公式如下:

其他的还有刻画非线性特性的余弦距离等,那么关键是什么,在K近邻中,关键是找到距离的衡量方式,即找到如何衡量两张图片相近程度的衡量方法。一种简单的实现可见K近邻教程
但是在做次工作时往往带有人的主观性,即人的先验知识,(因为人的思考系统组成参数与你这个系统不一样,你把这个参数迁移到你设计的数学模型往往行不通)。要摆脱这种问题肯定是让机器形成自己的先验,如神经网络。
2.1.2 线性模型
这个太简单了,说白了,找一条线(超平面)把数据集正反例分开,什么是超平面,看我下面说的SVM,比起SVM,线性模型只是没了那条勾。
2.1.3 SVM
SVM是机器学习的里程碑,对样本不平衡问题仍然有比较好的效果,因为SVM只需要两个决策向量(即两个点,每个点都有很多个属性,所以构成向量)(注:tensorflow称张量)下图来自百度百科。

对此必须先明白,点动成线,线动成面,面动成体,体是三维物体,那体动成啥呢? 体其实可以看做一个点,其运动就是由一个体点构成的线,它再运动就是体点构成的线构成的面,总之,三维以上我们无法理解,及把它称(超体),而因为一个数据往往有几十个属性,就是几十个维度,那其实就是超体了,对于二维平面,我们是找到一条线将这些点按正负样例分开,对三维是一个平面将点分开,那四维就是找到一个体将四维正负样例分开,那么我们知道,对于N维点,我们可以找到一个N-1维表述的超体将其分开,我们称此为超平面。
SVM的目的就是找到一个超平面,做如下事情1.找到距离该超平面距离最小的点 2.调整超平面到这些点的距离最小。即让到该超平面距离最小的点到该超平面的距离最小。之所以你觉得绕口是因为这是个迭代的过程。最你反复重复1.2之后就得到了这样一个超平面。
但是实际上对于XOR情况,或者如图情况,我们找不到一条超平面能将整个数据集按正负样本分开,怎么办,我们可以将点映射到更高维即可,说白了就是对距离做手脚,之前我们不是说找到距离该超平面距离最小的点吗,这个距离如何衡量?你可以换成二维距离啊,马氏距离也可以,高斯核距离也可以呀。引用SVM实现这篇文章

这个仿佛是对单属性的,但是实现上没那么简单,SVM研究源远流长,其问题核心和k近邻一样,就是如何衡量相似度,特别注意的是高斯核是无穷维映射,为什么无穷维?把他泰勒展开,是不是指数从0到无穷大的项都有,然而越高阶越不敏感(因为分母是个阶乘),如果我们初始化各属性都是0,那么相当于给了高阶一个非常接近0的初值,且这个不易改变,但是万分之一万和一分之一毕竟是一样的吧。
接下来关键是如何衡量相似度,我们可以用一些计算机图形学的方法去有选择的考虑各个点及各个维度,也可以考虑去傅里叶变换后与没傅里叶变换的图组成一个N维的矩阵去计算距离,人们在构造这个的时候,提出了各种花哨的办法,导致SVM计算速度甚至比百层的resnet更慢,这样得不偿失,而且测试集正确率也没增加多少。但是关键是什么,关键是人的思考系统组成参数与你这个系统不一样,你把这个参数迁移到你设计的数学模型往往行不通,这里又强调了一遍,希望读者能理解这个意思。
然后SVM的变种有SVR(用于回归),软间隔分类器,在SVM的两条道之间允许有少量反例样本。具体可见周志华机器学习,这不是我们的重点。
2.1.4 神经网络
既然我们想让机器能自己去学习符合机器本身特性的先验,我们就提出了神经网络,从早期的感知机,到现在,这个发展很快,因为它只有少量的人类先验(如结构,连接等)。之前一直被称为黑盒模型,但却不是真的如此,神经网络的含义越来越能被解释了,

引用百度百科这张图片,最左边是输入,每条线是个权重,神经网络还有激活函数,它的功能就是叠加,下面解释这个的意思。
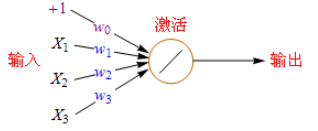
我们在求圆面积的时候可以用多边形去近似一个圆,当多边形边趋于无穷大时就变成了圆,注意这个近似,如果我们使用线性激活函数,每个激活函数的输出都是一条线,那么我们有多个激活函数,集合在一起就变成了多段的线,这样,我们就可以得到任意近似了。具体可以参考神经网络入门教程,激活函数的意思可见常见激活函数。现在一般用selu,见激活函数发展历史介绍
现给出下列被证明的理论:
1.当准确率足够高时,局部最小值与全局最小值差不多,因为鞍点都集中在准确率比较低的地方。
2.深层网络需要的参数比浅层网络少,这也是我们为什么用深层的原因。
3.线性激活函数通过SGD可以直接达到全局最小,relu不可以。
4.神经网络越深VC维越大,但泛化能力不一定就减弱,可能更强。
5.深度学习一般不是一个凸优化问题。
6.对图像进行分类的时候,发现对下一神经元影响最大的往往集中在相应神经元周围(比如8邻域),越远离那么权重越小,所以前人做了一个尝试:CNN(当然有个过程)这里可以自己去了解。
所以我们由6可以提出一个新的模型CNN:引用自LeNet详解

你看,神经元直接不是全连接的,而是一个模板一个模板的连接在一起,这就是卷积。
好了本章结束了,下次我们将详解图像分类CNN模型,不定期更新,欢迎订阅。

- 深度学习常见主流经典算法概述(三)(图像分类从AlexNet到SENet)
- 深度学习常见主流经典算法概述(二)(CNN的本质,以LeNet为例)
- 【神经网络与深度学习】迁移学习:经典算法解析
- CS231n 学习笔记(2)——神经网络 part2 :线性分类器,SVM
- 【备忘】2017年最新整理神经网络深度学习算法全套视频教程
- arxiv | 技术概述深度学习:详解前馈、卷积和循环神经网络
- 技术文章 | 深度学习的这些坑你都遇到过吗?神经网络11大常见陷阱及应对方法
- 利用遗传算法优化神经网络:Uber提出深度学习训练新方式
- 深度学习算法实践7---前向神经网络算法原理
- 【深度学习 论文综述】深度神经网络全面概述:从基本概念到实际模型和硬件基础
- 深度学习算法实践3---神经网络常用操作实现
- 深度学习算法实践3---神经网络常用操作实现
- 深度学习算法之卷积神经网络简介
- 线性神经网络模型与学习算法
- 史上最简单的深度学习教程,带你快速入门深度学习———艺术风格化的神经网络算法
- 深度学习进阶(二)--神经网络结构算法以及梯度下降法
- 深度学习-002 NISP: Pruning Networks using Neuron Importance Score Propagation 神经网络剪枝算法
- 深度学习算法之卷积神经网络简介
- 深度学习算法实践3---神经网络常用操作实现
- 深度学习基础模型算法原理及编程实现--04.改进神经网络的方法