身份证文字信息及人脸图片采集
2019-03-01 17:48
513 查看
结合openCV来做身份证上的人脸识别,并将识别到的人脸保存下来,再用Tesseract的java实现tess4j做身份证文字信息采集案例
注:身份证人脸截图能够实现,身份证文字信息采集识别率不高,需要自己训练中文识别器来提高识别率。如何训练不在这里讨论。
1.openCV相关包
下载地址:
https://download.csdn.net/download/l_sunrise/10965150
以idea为例配置openCV
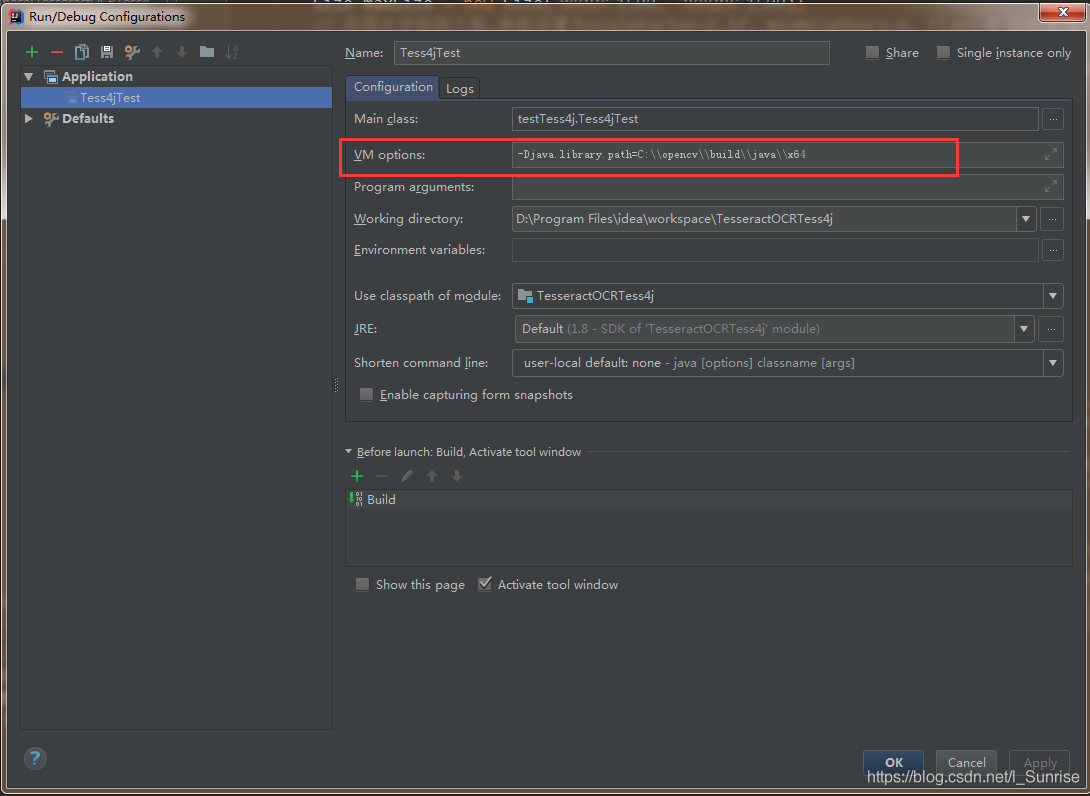
1.1. 在VM options 中配置opencv_java320.dll文件的位置
1.2. 创建人脸识别器
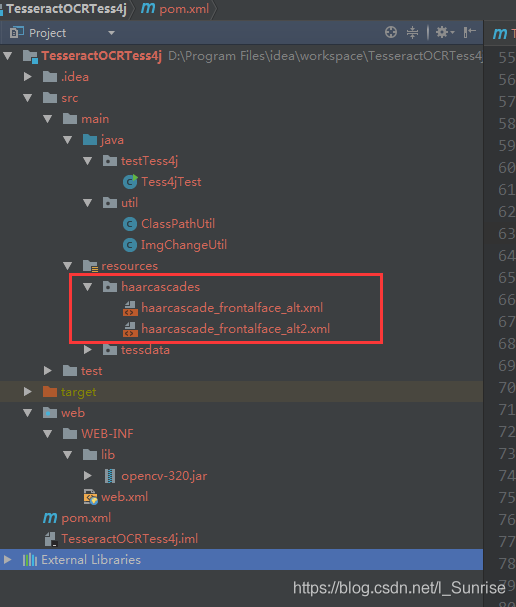
注意路径问题 ,可直接根据lbpcascade_frontalface.xml文件所在磁盘位置绝对路径来创建,也可将此文件引入到工程资源文件夹下,根据其路径找到该文件创建人脸识别器
2.配置OCR
由于Tesseract默认支持的是英文和数字的检查,若想其支持中文检查,需要自己下载中文检测器并放入tessdata文件夹下,可将整个文件夹拷贝进工程资源文件夹下,然后指明tessdata文件夹位置和扫描时需要识别中文

OCR资料:
包含中文包,以tess4j的方式使用Tesseract做OCR,只需要其中的D:\tesseract\Tesseract-OCR\tessdata文件夹里的东西
下载地址:
https://download.csdn.net/download/l_sunrise/10988911
3.Maven依赖
[code]<dependency> <groupId>net.java.dev.jna</groupId> <artifactId>jna</artifactId> <version>4.1.0</version> </dependency> <dependency> <groupId>net.sourceforge.tess4j</groupId> <artifactId>tess4j</artifactId> <version>3.2.1</version> <exclusions> <exclusion> <groupId>com.sun.jna</groupId> <artifactId>jna</artifactId> </exclusion> </exclusions> </dependency>
4.代码实现:
[code]package testTess4j;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import net.sourceforge.tess4j.util.ImageHelper;
import org.opencv.core.*;
import org.opencv.objdetect.CascadeClassifier;
import util.ClassPathUtil;
import util.ImgChangeUtil;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
/**
* @author LBW
* @name 身份证信息采集及人脸图片采集
* @date 2019/2/28 - 15:10
*/
public class Tess4jTest {
static {
//运行需要配置 VM options:-Djava.library.path=C:\\opencv\\build\\java\\x64(opencv_java320.dll的位置)
//因为用到openCV,在调用之前,一定要加上这句话,目的是加载OpenCV API相关的DLL支持,没有它是不会正确运行的
System.loadLibrary(Core.NATIVE_LIBRARY_NAME);
}
public static void main(String[] args) throws IOException {
ITesseract instance = new Tesseract();
//设置tessdata目录绝对路径
instance.setDatapath(ClassPathUtil.getPath()+"tessdata");
//如果需要识别英文之外的语种,需要指定识别语种,并且需要将对应的语言包放进项目中
instance.setLanguage("chi_sim");
// 指定需要识别的图片
File imageFile = new File("F:\\imgs\\3225d9bc0bf5835aaacb5db0e1a3904.jpg");
BufferedImage img= ImageIO.read(imageFile);
/**************************************截取身份证人脸图 start***********************************/
long startTime = System.currentTimeMillis();
BufferedImage faceImg = img;
//用来记录人脸坐标
int[] rectPosition = new int[4];
//从配置文件lbpcascade_frontalface.xml中创建一个人脸识别器
//该文件在openCV包C:\opencv\sources\data\haarcascades\中
CascadeClassifier faceDetector = new CascadeClassifier(ClassPathUtil.getPath()+"/haarcascades/haarcascade_frontalface_alt2.xml");
//将BufferedImage转换为Mat对象
Mat mat = ImgChangeUtil.BufImg2Mat(faceImg,BufferedImage.TYPE_3BYTE_BGR, CvType.CV_8UC3);
//指定人脸识别的最大和最小像素范围
Size minSize = new Size(500, 500);
Size maxSize = new Size(1500, 1500);
// 在图片中检测人脸,参数设置为scaleFactor=1.1f, minNeighbors=4, flags=0 以此来增加识别人脸的正确率
MatOfRect faceDetections = new MatOfRect();
faceDetector.detectMultiScale(mat, faceDetections,1.1f, 4, 0, minSize, maxSize);
//人脸坐标
Rect[] rects = faceDetections.toArray();
//如果检测到人脸
if (rects != null && rects.length >= 1) {
System.out.println("识别到人脸,执行保存!");
for (Rect rect : rects) {
rectPosition[0]=rect.x-120;
rectPosition[1]=rect.y-240;
rectPosition[2]=rect.width+200;
rectPosition[3]=rect.height+600;
}
//将Mat对象转换回BufferedImage对象
faceImg = ImgChangeUtil.Mat2BufImg(mat,".jpg");
//截取图片
faceImg=ImageHelper.getSubImage(faceImg, rectPosition[0], rectPosition[1], rectPosition[2], rectPosition[3]);
ImageIO.write(faceImg,"jpg",new File("F:\\imgs\\faceImg1.jpg"));
}
System.out.println("人脸图片检测并保存耗时:"+(System.currentTimeMillis()-startTime)+"ms");
/**************************************截取身份证人脸图 end***********************************/
/***************************************提高 OCR 效率 start**********************************/
//int width=new Double(img.getWidth()*0.6).intValue();
//int height=new Double(img.getHeight()*0.25).intValue();
//如果需要识别的信息位置固定,可以截取图片,只识别那一部分,以提高识别效率
//img=ImageHelper.getSubImage(img, width, height, 1100, 1200);
//图片置灰
img = ImageHelper.convertImageToGrayscale(img);
//图片锐化
img = ImageHelper.convertImageToBinary(img);
//图片放大5倍,增强识别率
//img = ImageHelper.getScaledInstance(img, img.getWidth() * 5, img.getHeight() * 5);
/***************************************提高 OCR 效率 end***********************************/
startTime = System.currentTimeMillis();
String ocrResult = null;
try {
//执行OCR扫描识别文字
ocrResult = instance.doOCR(img);
} catch (TesseractException e) {
System.out.println("识别失败!");
e.printStackTrace();
}
// 输出识别结果
System.out.println("OCR Result: \n" + ocrResult + "\n耗时:" + (System.currentTimeMillis() - startTime) + "ms");
}
}
其中用到的工具类:
ClassPathUtil:
[code]package util;//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//
import java.net.URLDecoder;
public class ClassPathUtil {
public ClassPathUtil() {
}
public static String getPath() {
String path = null;
try {
path = ClassPathUtil.class.getClassLoader().getResource("").getPath().toString();
String systemName = System.getProperty("os.name");
if (systemName.startsWith("Windows")) {
path = URLDecoder.decode(path.substring(1), "utf-8");
} else {
path = URLDecoder.decode(path, "utf-8");
}
} catch (Exception var2) {
var2.printStackTrace();
}
return path;
}
}
ImgChangeUtil:
[code]package util;
import org.opencv.core.Mat;
import org.opencv.core.MatOfByte;
import org.opencv.imgcodecs.Imgcodecs;
import javax.imageio.ImageIO;
import java.awt.*;
import java.awt.image.BufferedImage;
import java.awt.image.DataBufferByte;
import java.io.ByteArrayInputStream;
import java.io.InputStream;
/**
* @author
* @name openCV - Mat 对象与 BufferedImage 互转
* @date 2019/3/1 - 11:10
*/
public class ImgChangeUtil {
/**
* Mat转换成BufferedImage
*
* @param matrix
* 要转换的Mat
* @param fileExtension
* 格式为 ".jpg", ".png", etc
* @return
*/
public static BufferedImage Mat2BufImg (Mat matrix, String fileExtension) {
// convert the matrix into a matrix of bytes appropriate for
// this file extension
MatOfByte mob = new MatOfByte();
Imgcodecs.imencode(fileExtension, matrix, mob);
// convert the "matrix of bytes" into a byte array
byte[] byteArray = mob.toArray();
BufferedImage bufImage = null;
try {
InputStream in = new ByteArrayInputStream(byteArray);
bufImage = ImageIO.read(in);
} catch (Exception e) {
e.printStackTrace();
}
return bufImage;
}
/**
* BufferedImage转换成Mat
*
* @param original
* 要转换的BufferedImage
* @param imgType
* bufferedImage的类型 如 BufferedImage.TYPE_3BYTE_BGR
* @param matType
* 转换成mat的type 如 CvType.CV_8UC3
*/
public static Mat BufImg2Mat (BufferedImage original, int imgType, int matType) {
if (original == null) {
throw new IllegalArgumentException("original == null");
}
// Don't convert if it already has correct type
if (original.getType() != imgType) {
// Create a buffered image
BufferedImage image = new BufferedImage(original.getWidth(), original.getHeight(), imgType);
// Draw the image onto the new buffer
Graphics2D g = image.createGraphics();
try {
g.setComposite(AlphaComposite.Src);
g.drawImage(original, 0, 0, null);
} finally {
g.dispose();
}
}
byte[] pixels = ((DataBufferByte) original.getRaster().getDataBuffer()).getData();
Mat mat = Mat.eye(original.getHeight(), original.getWidth(), matType);
mat.put(0, 0, pixels);
return mat;
}
}

相关文章推荐
- Android 百度人脸识别、人脸采集、文字识别(身份证),人证对比
- python 识别图片中的文字信息方法
- Android ListView 列表分隔,条目中添加分类信息(文字,图片等)
- ASP.NET:图片添加文字信息
- 通过阿里云API 身份证图片或拍身份证 读取身份证正反面信息
- 用正则表达式采集网页上的图片信息
- 使用Office自动的软件将图片中的文字信息转换成word文档
- 在用户上传的图片上加上版权或者一些其他的附加文字信息
- html 提交表单,图片和文字一起提交,图片存入服务器,图片地址和表单信息存入数据库,带后端php代码
- HTML+CSS实现图片下半部分遮罩文字效果(仿微信推送信息的图片文字效果)
- launcher修改--获取widget信息(图片,文字等)(源码追踪)
- 关于使用阿里云服务调用识别身份证图片、营业执照的信息抓取接口的简单实现
- android Bitmap转化成Base64 String 人脸识别 身份证识别 驾照识别 图片转化成String
- java获取文件exif信息-添加图片文字水印
- dedecms 5.1版的文字图片采集教程
- launcher修改--获取widget信息(图片,文字等)(源码追踪)
- 采集资源的方法(文字,图片) [图片]
- 鼠标滑过列表文字显示图片及详细信息信息信息 visual studio 08
- jpgraph之如果无值则在图片中间输出文字信息
- 滚动播放文字或者图片信息效果