shell中的文本处理正则表达式
1.grep 文本过滤命令
1).grep
Global search regular expression and print out theline:全面搜索研究正则表达式并显示出来
grep 命令是一种强大的文本搜索工具 , 根据用户指定的“模式”对目标文本进行匹配检查 , 打印匹配到的行由正则表达式或者字符及基本文本字符所编写的过滤条件
2).grep 的格式
例如
| grep | 匹配条件 | 处理文件 |
|---|---|---|
| grep | root | passwd |
| grep | ^root | passwd |
| grep | root$ | passwd |
| grep | -i root | passwd |
| grep | -E "root|ROOT" | passwd |

默认过滤root
 不区分大小写过滤root
不区分大小写过滤root

不区分大小写过滤root前无字符的字符串

不区分大小写过滤root后无字符的字符串

不区分大小写过滤只是root的字符串

不区分大小写过滤以root开头的且只是root的

不区分大小写过滤以root开头的
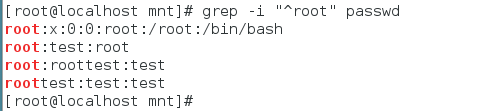
不区分大小写过滤以root结尾的且只是root的

不区分大小写过滤只以root开头的或只是root结尾的,“|”是扩展过滤命令,所以要加 -E,或用egrep命令

不区分大小写过滤除去只以root开头的或只是root结尾的

不区分大小写过滤除去只以root开头的或只是root结尾的且只含有root的

3).grep中的正则表达式
^ 关键字
关键字 $
< 关键字
关键字 >
< 关键字 >
4).grep 中字符的匹配次数设定
| * | 字符出现 [0- 任意次 ] |
| ? | 字符出现 [0-1 次 ] |
| + | 字符出现 [1- 任意次 ] |
| {n} | 字符出现 [n 次 ] |
| {m,n} | 字符出现 [ 最少出现 m 次,最多出现 n 次 ] |
| {0,n} | 字符出现 [0-n 次 ] |
| {m,} | 字符出现 [ 至少 m 次 ] |
| (xy){n} | xy 关键字出现 [n 次 ] |
| . | 关键字之间匹配任意字符 |

默认过滤x

过滤出现0-1次的x

过滤出现1到任意次的x

过滤出现2次的x

过滤出现1-3次的x

过滤出现1-3次的x

过滤出现0-1次的x和任意次y

过滤以x开始的出现0-1次的x和一次
 过滤出现2次的x和任意次y
过滤出现2次的x和任意次y

过滤出现0-2次的x和任意次y

过滤出现2次以上的x和任意次y

过滤出现1次的x和多次y

过滤出现多次的xy

过滤出现多次的xy并且以xy结尾

5).grep 正则表达式与扩展正则表达式
正规的 grep 不支持扩展的正则表达式子 , 竖线是用于表示”或”的扩展正则表达式元字符 , 正规的 grep 无法识别加上反斜杠 , 这个字符就被翻译成扩展正则表达式 , 就像 egrp和grep -E 一样
2.sed 行编辑器
1).stream editor
用来操作纯 ASCII 码的文本
处理时 , 把当 前处理的行存储在临时缓冲区中 , 称为“模式空间” (pattern space) 可以指定仅仅处理哪些行sed 符合模式条件的处理 不符合条件的不予处理处理完成之后把缓冲区的内容送往屏幕接着处理下一行 , 这样不断重复 , 直到文件末尾
2).sed命令格式
调用 sed 命令有两种形式:
sed [options] ‘command’ file(s)
sed [options] -f scriptfile file(s)
2).sed对字符的处理
| 参数 | 含义 |
|---|---|
| p | 显示 |
| d | 删除 |
| a | 添加 |
| c | 替换 |
| w | 写入 |
| i | 插入 |
3).p模式操作
eg:
| sed -n ‘/:/p’ fstab | 显示有“:“的行 |
| sed -n ‘/UUID$/p’ fstab | 显示有UUID结尾的字符串的行 |
| sed -n ‘/^UUID/p’ fstab | 显示以UUID开头的行 |
| sed -n ‘2,6p’ fstab | 显示2,6行 |
| sed -n ‘2,6!p’ fstab | 显示除了2,6行的所有 |

忽略空白行

不忽略空白行

显示以#开头的行
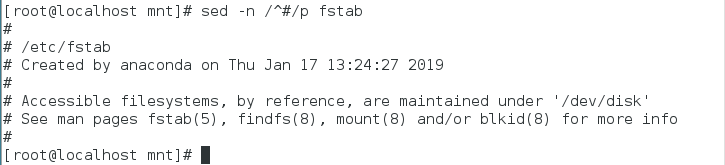
显示不是#开头的行

不忽略空白行,显示2-6行

不忽略空白行,只显示第6行

不忽略空白行,显示第6行和第2行(-e表示执行,两次-e表示执行两次)
方法1:

方法2:

不忽略空白行,显示除去第2行和第6行

4).d模式操作
| sed ‘/^UUID/d’ /etc/fstab | 显示除去UUID开头的行 |
| sed ‘/^#/d’ /etc/fstab | 显示除去#开头的行 |
| sed ‘/^$/d’/etc/fstab | 显示除去空白行的行 |
| sed ‘1,4d’/etc/fstab | 显示除去1-4行的行 |
| sed –n ‘/^UUID/!d’ /etc/fstab | 显示UUID开头的行 |
显示除去#开头的行


显示除去#开头的行和空白行
 显示除去4-6行的行
显示除去4-6行的行

显示除去第4行的行

显示除去第4行和第6行的行

显示除去UUID开头的行
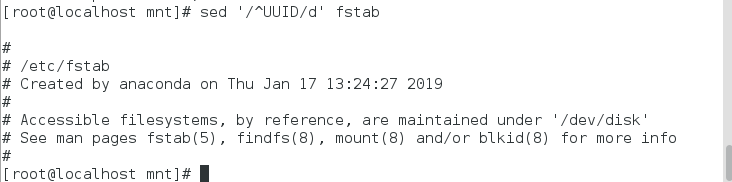
显示UUID开头的行

5).a模式操作
| sed ‘/^UUID/ahello’ fstab | 显示在UUID开头后加上hello的fstab |
| sed ‘/^UUID/ahello\nwestos’ fstab | 显示在UUID开头后加上两行hello行和westos行的fstab |

默认添加hello会添加到fstab的每一行之后
 追加到最后一行可以使用echo命令
追加到最后一行可以使用echo命令


删除最后一行hello
显示在UUID开头后加上两行hello行和westos行的fstab

6).i 模式操作
| sed ‘/^UUID/ihello’ fstab | 在以UUID开头的行的前一行加入hello |
| sed ‘/^UUID/ihello\nwestos’ fstab | 在以UUID开头的行的前两行加入hello行和westos行 |


7).c 模式操作
| sed ‘/^#/c\hello\nwestos’ fstab | 将以#开头的行换成hello行和westos行并将换后的文件内容显示出来 |
| sed ‘/^#/c\hello’ fstab | 将以#开头的行换成hello并将换后的文件内容显示出来 |
将以#开头的行换成hello并将换后的文件内容显示出来

将以#开头的行换成hello行和westos行并将换后的文件内容显示出来

8).w 模式操作
| sed ‘/^UUID/w /tmp/fstab.txt’ /etc/fstab | 将fstab中的以UUID开头的行整合到tmp下的fstab中并显示出来 |
| sed -n’/^UUID/w /tmp/fstab.txt’ /etc/fstab | 将fstab中的以UUID开头的行整合到tmp下的fstab中,不显示出来 |
| sed ‘/^UUID/=’/etc/fstab | 将fstab中的以UUID开头的行的行数显示出来 |
| sed ‘5r /etc/issue’ /etc/fstab | 将issue文件中的内容整合到fstab中的第5行开始 |
将fstab中的以#开头的行整合到mnt下的testfile中并显示出来


将hello文件中的内容整合到fstab中的第5行开始

9).sed 的其他用法
| sed -n ‘/^UUID/=’ fstab | 只显示以UUID开头的行的行号 |
| sed -n -e ‘/^UUID/p’ -e ‘/^UUID/=’ fstab | 显示以UUID开头的行的行以及行号 |
| sed -e ‘s/brown/green/; s/dog/cat/’ data | 将brown换成green,将dog换成cat并显示data中所有的内容 |
| sed -f rulesfile file | 对file执行rulesfile中的规则并显示出来 |
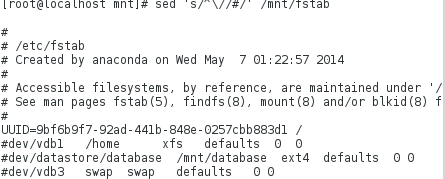
| sed ‘s/^//#/’ /etc/fstab | 将以/开始的行的/换成#并显示出来 |
| sed ‘s@^/@#@g’ /etc/fstab | 将以/开始的行的/换成#并显示出来 |
| sed ‘s///#/’/etc/ fstab | 将/换成#并显示出来 |
| sed ‘G’ data | 在每一行后添加一行空白行 |
| sed ‘$!G’ data | 在每一行后添加一行空白行,最后一行不添加 |
| sed ‘=’ data | sed ‘N; s/\n/ /’ |
| sed -n ‘$p’ data | 输出最后一行 |
只显示以UUID开头的行的行号

显示以UUID开头的行的行以及行号

显示以UUID开头的行的行以及行号显示在每一行之前

显示以UUID开头的行的行以及行号显示在每一行之前且空一格

将以/开始的行的/换成#并显示出来
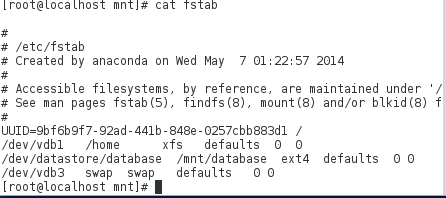

rule中的规则是显示以UUID开头的并显示出行号

将nologin修改为bash


将1-5行中的nologin变成bash其他不变

修改第5行中的nologin成bash

修改第5行和第3行,将nologin变成bash

修改从daemon行到mail行中的nologin成dash

将:修改为#####,将nologin修改为redhat

修改/为空

修改/为空(可以将/变成@,但是转义的/不能变)

修改nologin成bash

在每一行后添加一行空白行

在每一行后添加一行空白行,最后一行不添加

显示行号且和每一行有个空格

3.awk 报告生成器
1).awk
awk 处理机制:awk 会逐行处理文件,支持在处理第一行之前做一些准备工作 , 以及在处理完最后一行做一些总结性质的工作 , 在命令格式上分别体现如下 :
| BEGIN{} | 读入第一行文本之前执行 , 一般用来初始化操作 |
| {} | 逐行处理 , 逐行读入文本执行相应的处理 , 是最常见的编辑指令快 |
| END{} | 处理完最后一行文本之后执行 , 一般用来输出处理结果 |
2).awk 基本用法
linux 上面默认使用 gawk
| awk ‘{print FILENAME}’ /etc/passwd | 每一行都显示出目录的名字 |
| awk ‘{print NR}’ /etc/passwd | 每一行输出行号,默认以空格为分隔符 |
| awk ‘{print NF}’ /etc/passwd | 每一行输出有多少列 |
| awk ‘BEGIN{print “NAME”}’ | 在开始的时候输出NAME这个字符串 |
| awk ‘END{print “WESTOS”}’ | 在结尾输出WESTOS这个字符串 |
| awk -F : ‘BEGIN{print “NAME”}{print $1}END{print “WESTOS”}’ | 以":"为分隔符,输出第一列,在开头输出NAME,结尾输出WESTOS |
| awk ‘/bash$/’ /etc/passwd | 输出以bash结尾的行 |
| awk -F : ‘/bash$/{print $1}’ | 以“:”为分隔符,输出以bash结尾的第一列 |
以:为分隔符,输出hello

以":"为分隔符,输出第一列,在开头输出hello,结尾输出end


输出以bash结尾的人的个数

目录中的每一行都显示出目录的名字

以:为分隔符输出行号

以:为分隔符输出每一行有几列

在开始的时候输出NAME这个字符串
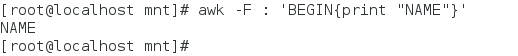
“:”为分隔符,输出第一列

以“:”为分隔符,输出以bash结尾的第一列

以“:”为分隔符,输出不以bash结尾的第一列

计算100+50

awk 'BEGIN{a=34;print a+12}' #计算34+12
awk -F : '/^ro/{print}' /etc/passwd #输出以ro开头的行
awk -F : '/^[a-d]/{print $1,$6}' passwd.txt #以:为分隔符输出以a到d开头的行的第1和第6列
awk -F : '/^a|nologin$/{print $1,$7}' passwd.txt #以:为分隔符输出以a开头的或以nologin结尾的行的第1和第6列
awk -F : '$6~/bin$/{print $1,$6}' #以:为分隔符,输出第6列是bin结尾的行的第1和第6列
awk -F : '$7!~/nologin$/{print $1,$7}' passwd.txt #以:为分隔符,输出第7列不是nologin结尾的行的第1和第7列
计算100+50
输出以a到d开头的行

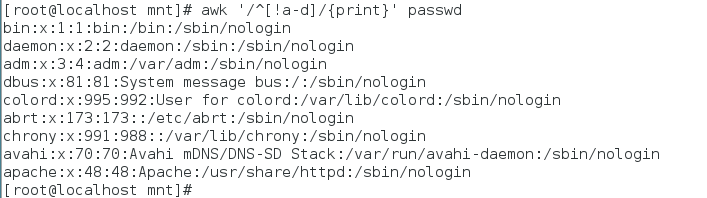

输出不是以a到d开头的行(两种方法)


输出不是以a开头的或以bash结尾的行

输出以a开头的或以bash结尾的行

输出不是以a开头但是以bash结尾的行

以:为分隔符,输出第6列是bin结尾的行

以:为分隔符,输出第6列只是bin结尾的行

以:为分隔符,输出第6列不是bin结尾的行

输出第6列是/home开头且以bash结尾的行的第一列

输出第6列是/home开头且以bash结尾的行的人数(可以登陆系统的人数)(循环)

3).awk测试
抓取网卡的ip
此台主机网卡名称为ens3


在系统中可以登陆系统的用户

- shell中文本处理正则表达式
- R语言:文本(字符串)处理与正则表达式
- PHP扩展之文本处理(二)——PCRE正则表达式语法3——转义序列(反斜线)
- Shell 正则表达式 字符串处理
- 文本处理(grep、sed)、正则表达式、vim基础
- 字符及文本处理之二:grep及正则表达式详解
- R语言进阶之二:文本(字符串)处理与正则表达式
- 正则表达式搭配js轻松处理json文本方便而老古
- shell字符处理命令,通配符,正则表达式
- linux文本处理之常用正则表达式整理
- Linux学习第七课-文本处理工具及正则表达式
- PHP扩展之文本处理(二)——PCRE正则表达式语法4——Unicode字符属性
- Shell中的正则表达式及字符串处理
- 关于 文本处理工具、正则表达式、grep 的简单举例
- 用正则表达式和js轻松处理json文本
- 正则表达式搭配js轻松处理json文本方便而老古
- Java中使用正则表达式处理文本数据
- PHP扩展之文本处理(二)——PCRE正则表达式语法5——锚和句点
- Shell正则表达式 & Grep正则表达式 & shell字符串处理
- Linux 文本处理,文本工具,查看,分析,统计文本文件,grep,正则表达式