深入浅出Redis-redis底层数据结构(下)
原文:https://www.geek-share.com/detail/2695200861.html
作者:jaycekong
概述:
学习使用Redis,其实并不需要去研究其底层数据的实现。我们只需要了解他有哪些常用的数据类型,然后熟练使用,就可以很好的掌握Redis 这个工具了。但是这样的学习方法只适合Redis 的入门,“工欲善其事必先利其器”,我们想要用好Redis,则必须深入了解Redis 的底层到底是如何实现的,我们在选择数据结构的时候才能做出正确的选择。
在上一篇博客《深入浅出Redis-redis底层数据结构(上)》中,我们已经讲解了Redis 中的 动态字符串,链表,字典
在这里我们简单回顾一下他们的特点:
-
动态字符串SDS:区别于C语言字符串,具有良好的伸缩性,在获取字符串长度,字符串修改,防止缓存区溢出等性能都比C语言字符串好
-
链表:顺序存储对象信息,有用于缓存链表长度的属性,在插入删除对象功能中有良好性能,避免环的产生
-
字典:key-value 存储方式,通过hash值计算,判断key的存储,当容量过大,会通过rehash重新分配字典大小
5、跳跃表
5.1 概述
跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。跳跃表是一种随机化的数据,跳跃表以有序的方式在层次化的链表中保存元素,效率和平衡树媲美 ——查找、删除、添加等操作都可以在对数期望时间下完成,并且比起平衡树来说,跳跃表的实现要简单直观得多。
Redis 只在两个地方用到了跳跃表,一个是实现有序集合键,另外一个是在集群节点中用作内部数据结构。
5.2 跳跃表的定义
我们先来看一下一整个跳跃表的完整结构:
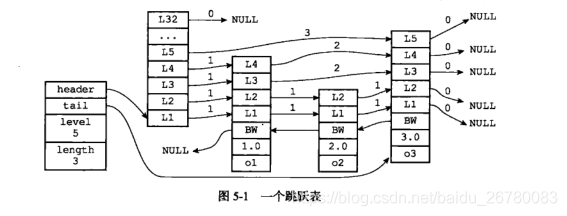
Redis 的跳跃表 主要由两部分组成:zskiplist(链表)和zskiplistNode (节点)
5.2.1 zskiplistNode(节点) 数据结构:
typedef struct zskiplistNode{
//层
struct zskiplistLevel{
//前进指针
struct zskiplistNode *forward;
//跨度
unsigned int span;
} level[];
//后退指针
struct zskiplistNode *backward;
//分值
double score;
//成员对象
robj *obj;
}
-
层:level 数组可以包含多个元素,每个元素都包含一个指向其他节点的指针。
-
前进指针:用于指向表尾方向的前进指针
-
跨度:用于记录两个节点之间的距离
-
后退指针:用于从表尾向表头方向访问节点
-
分值和成员:跳跃表中的所有节点都按分值从小到大排序。成员对象指向一个字符串,这个字符串对象保存着一个SDS值
5.2. zskiplist 数据结构:
typedef struct zskiplist {
//表头节点和表尾节点
structz skiplistNode *header,*tail;
//表中节点数量
unsigned long length;
//表中层数最大的节点的层数
int level;
}
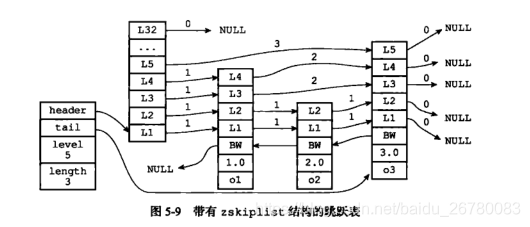
从结构图中我们可以清晰的看到,header,tail分别指向跳跃表的头结点和尾节点。level 用于记录最大的层数,length 用于记录我们的节点数量。
5.3 总结
- 跳跃表是有序集合的底层实现之一
- 主要有zskiplist 和zskiplistNode两个结构组成
- 每个跳跃表节点的层高都是1至32之间的随机数
- 在同一个跳跃表中,多个节点可以包含相同的分值,但每个节点的对象必须是唯一的
- 节点按照分值的大小从大到小排序,如果分值相同,则按成员对象大小排序
6、整数集合(Intset)
6.1 概述
《Redis 设计与实现》 中这样定义整数集合:“整数集合是集合的底层实现之一,当一个集合中只包含整数,且这个集合中的元素数量不多时,redis就会使用整数集合intset作为集合的底层实现。”
我们可以这样理解整数集合,他其实就是一个特殊的集合,里面存储的数据只能够是整数,并且数据量不能过大。
6.2 整数集合的实现
typedef struct intset{
//编码方式
uint32_t enconding;
// 集合包含的元素数量
uint32_t length;
//保存元素的数组
int8_t contents[];
}
我们观察一下一个完成的整数集合结构图:
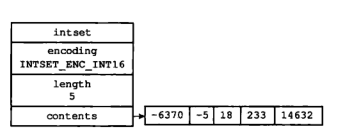
-
encoding:用于定义整数集合的编码方式
-
length:用于记录整数集合中变量的数量
-
contents:用于保存元素的数组,虽然我们在数据结构图中看到,intset将数组定义为int8_t,但实际上数组保存的元素类型取决于encoding
6.3 整数集合的升级
在上述数据结构图中我们可以看到,intset 在默认情况下会帮我们设定整数集合中的编码方式,但是当我们存入的整数不符合整数集合中的编码格式时,就需要使用到Redis 中的升级策略来解决
Intset 中升级整数集合并添加新元素共分为三步进行:
- 根据新元素的类型,扩展整数集合底层数组的空间大小,并为新元素分配空间
- 将底层数组现有的所有元素都转换成新的编码格式,重新分配空间
- 将新元素加入到底层数组中
比如,我们现在有如下的整数集合:
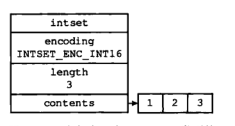
我们现在需要插入一个32位的整数,这显然与整数集合不符合,我们将进行编码格式的转换,并为新元素分配空间:

第二步,将原有数据他们的数据类型转换为与新数据相同的类型:(重新分配空间后的数据)

第三部,将新数据添加到数组中:

6.3.1 整数集合升级的好处
-
提升灵活性
-
节约内存
6.4 总结
-
整数集合是集合键的底层实现之一
-
整数集合的底层实现为数组,这个数组以有序,无重复的范式保存集合元素,在有需要时,程序会根据新添加的元素类型改变这个数组的类型
-
升级操作为整数集合带来了操作上的灵活性,并且尽可能地节约了内存
-
整数集合只支持升级操作,不支持降级操作
7、压缩列表
7.1 概述
压缩列表是列表键和哈希键的底层实现之一。当一个列表键只包含少量列表项,并且每个列表项要么就是小整数,要么就是长度比较短的字符串,那么Redis 就会使用压缩列表来做列表键的底层实现。
7.2 压缩列表的构成
一个压缩列表的组成如下:

-
zlbytes:用于记录整个压缩列表占用的内存字节数
-
zltail:记录压缩列表尾节点距离压缩列表的起始地址有多少字节
-
zllen:记录了压缩列表包含的节点数量。
-
entryX:压缩列表包含的各个节点
-
zlend:用于标记压缩列表的末端

7.3 总结
-
压缩列表是一种为了节约内存而开发的顺序型数据结构
-
压缩列表被用作列表键和哈希键的底层实现之一
-
压缩列表可以包含多个节点,每个节点可以保存一个字节数组或者整数值
-
添加新节点到压缩列表,可能会引发连锁更新操作。

- 深入浅出Redis-redis底层数据结构(下)
- 深入浅出Redis-redis底层数据结构(上)
- redis 列表的底层数据结构链表
- REDIS系列之底层数据结构
- Redis底层数据结构之链表
- redis底层数据结构之dict 字典2
- redis底层数据结构之intset
- redis底层数据结构之dict 字典1
- 深入浅出从底层分析 Redis client/server交互流程(干货)
- redis数据结构底层(个人记忆使用)
- Redis 3.0 源码解析---底层数据结构分析(3)
- Redis数据结构底层知识总结
- redis 底层数据结构 整数集合intset
- Redis底层数据结构之简单动态字符串
- Redis底层数据结构之字典
- Redis数据库底层数据结构设计
- Redis数据结构底层知识总结
- Redis源码分析(1)-底层数据结构SDS
- redis底层数据结构之adlist
- ssdb底层实现——ssdb底层是leveldb,leveldb根本上是skiplist(例如为存储多个list items,必然有多个item key,而非暴力string cat),用它来做redis的list和set等,势必在数据结构和算法层面上有诸多不适