python项目实战:用多进程(multiprocessing)+多线程(threading)的方式并发爬取淘宝商品信息并存入MongoDB
用多进程(multiprocessing)+多线程(threading)的方式并发爬取淘宝商品信息并存入MongoDB
声明:本文仅供学习用,旨在分享
基于上次写的python实战:将cookies添加到requests.session中实现淘宝的模拟登录 ,此次我们实现在该登陆状况下抓取淘宝商品信息(以抓取美食信息为例),并用并发方式来对请求的URL进行访问爬取数据后存入MongoDB。
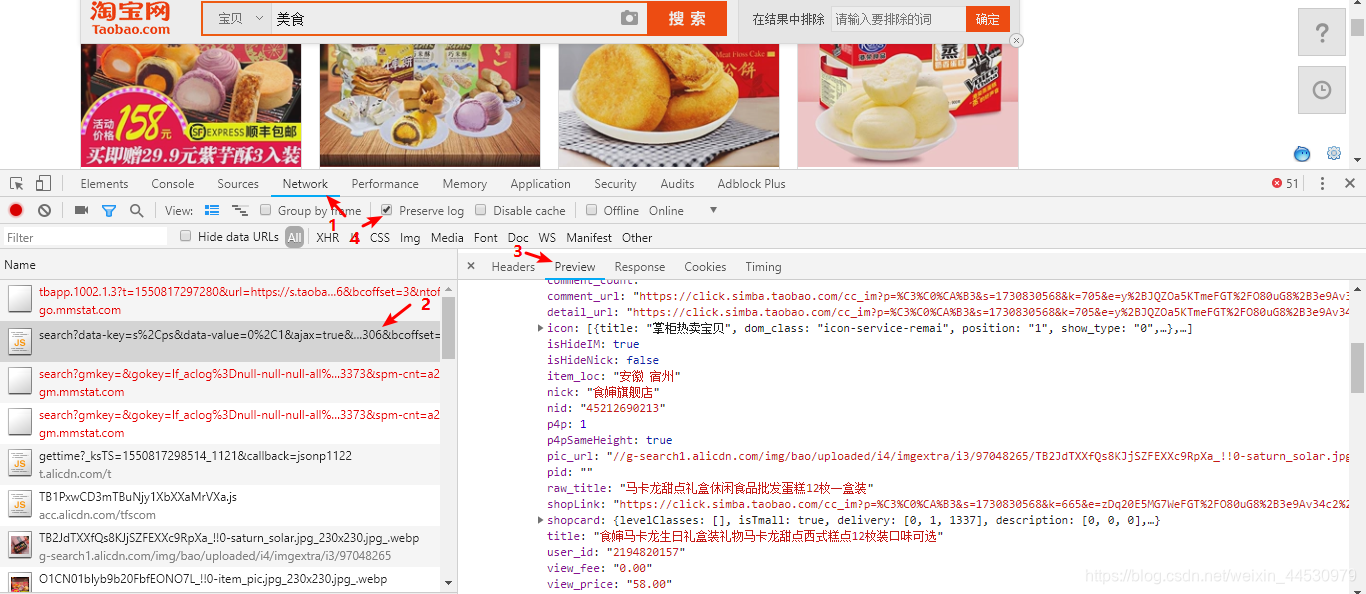
**1、**首先分析URL的请求规律。打开chrome的开发者工具,刷新页面后找出数据是由哪个URL请求得到的。经分析可知该URL为:https://s.taobao.com/search?data-key=s%2Cps&data-value=0%2C1&ajax=true&_ksTS=1550817297379_1096&callback=jsonp1097&q=美食&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2018.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=0&ntoffset=6&p4ppushleft=1%2C48&s=44 ,返回的数据格式是JSON。如下图所示:
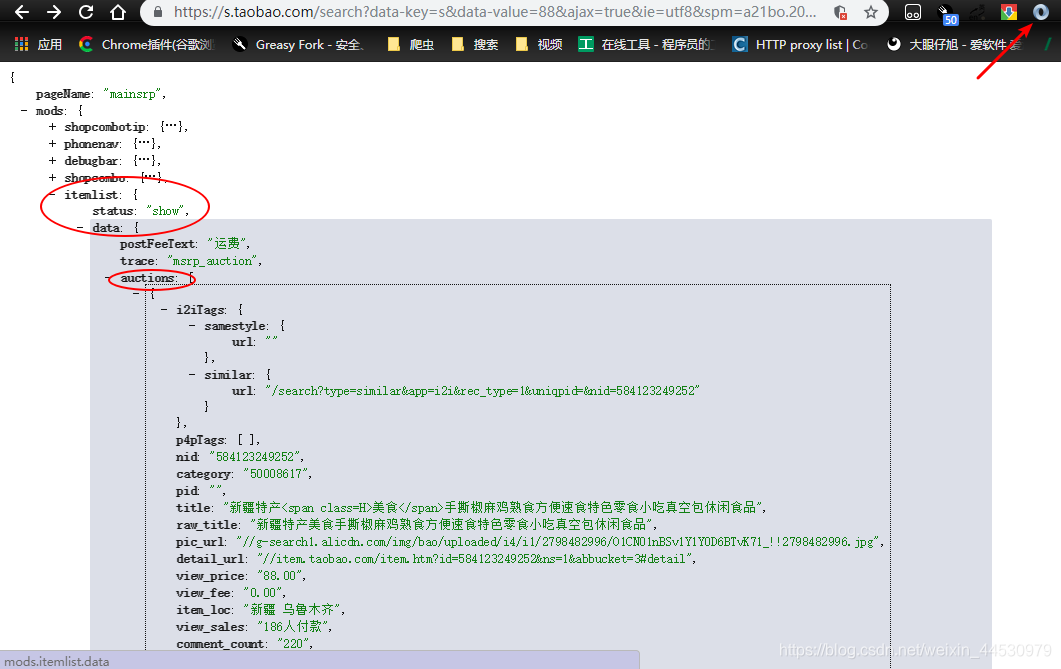
**2、**为了能得到URL的请求规律,我们在Network中选中Preserve log标签,然后点击下一页获取请求的URL为 https://s.taobao.com/search?data-key=s&data-value=44&ajax=true&_ksTS=1550817667669_1346&callback=jsonp1347&q=美食&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2018.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=3&ntoffset=0&p4ppushleft=1%2C48&s=0 ,将这俩次的请求URL进行对比会看到有些字段的值是不同的,针对这些字段我们逐个剔除,以其返回的数据是否仍包括我们所需的为依据,测试几次后得到了其简化的请求URL为: https://s.taobao.com/search?data-key=s&data-value={页码-1*44}&ajax=true&ie=utf8&spm=aa21bo.2017.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&q=美食 ,测试效果如下图:
**3、**知道其规律后我们基于上次写的python实战:将cookies添加到requests.session中实现淘宝的模拟登录 ,开始编写爬取淘宝数据程序:
主程序:taobao_spider,py
import requests
import threading
import multiprocessing
from config import *
import json
import pymongo
from urllib.parse import quote
client = pymongo.MongoClient(MONGO_URL, connect=False)
class TaoBao:
def __init__(self):
self.url_temp='https://s.taobao.com/search?data-key=s&data-value={}&ajax=true&ie=utf8&spm=aa21bo.2017.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&q='
self.headers={"Origin":"https://login.taobao.com",
"Upgrade-Insecure-Requests":"1",
"Content-Type":"application/x-www-form-urlencoded",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Referer":"https://login.taobao.com/member/login.jhtml?redirectURL=https%3A%2F%2Fwww.taobao.com%2F",
"Accept-Encoding":"gzip, deflate, br",
"Accept-Language":"zh-CN,zh;q=0.9",
"User-Agent":set_user_agent()}
self.cookies = {} # 申明一个用于存储手动cookies的字典
self.res_cookies_txt = ""# 申明刚开始浏览器返回的cookies为空字符串
self.keyword = "美食"
#读取mycookies.txt中的cookies
def read_cookies(self):
with open("mycookies.txt",'r',encoding='utf-8') as f:
cookies_txt = f.read().strip(';') #读取文本内容
#由于requests只保持 cookiejar 类型的cookie,而我们手动复制的cookie是字符串需先将其转为dict类型后利用requests.utils.cookiejar_from_dict转为cookiejar 类型
for cookie in cookies_txt.split(';'):
name,value=cookie.strip().split('=',1) #用=号分割,分割1次
self.cookies[name]=value #为字典cookies添加内容
#将字典转为CookieJar:
cookiesJar = requests.utils.cookiejar_from_dict(self.cookies, cookiejar=None,overwrite=True)
return cookiesJar
#保存模拟登陆成功后从服务器返回的cookies,通过对比可以发现是有所不同的
def set_cookies(self,cookies):
# 将CookieJar转为字典:
res_cookies_dic = requests.utils.dict_from_cookiejar(cookies)
#将新的cookies信息更新到手动cookies字典
for i in res_cookies_dic.keys():
self.cookies[i] = res_cookies_dic[i]
#将更新后的cookies写入到文本
for k in self.cookies.keys():
self.res_cookies_txt += k+"="+self.cookies[k]+";"
#将服务器返回的cookies写入到mycookies.txt中实现更新
with open('mycookies.txt',"w",encoding="utf-8") as f:
f.write(self.res_cookies_txt)
def parse_url(self,url):
# 开启一个session会话
session = requests.session()
# 设置请求头信息
session.headers = self.headers
# 将cookiesJar赋值给会话
session.cookies = self.read_cookies()
# 向目标网站发起请求
response = session.get(url)
self.set_cookies(response.cookies)
return response.content.decode()
def get_goods_list(self,json_str):
dirt_ret=json.loads(json_str)
goods_list=dirt_ret["mods"]["itemlist"]["data"]["auctions"]
if goods_list:
for goods in goods_list:
goods_content = {}
goods_content['title'] = goods['raw_title'] # 名称
goods_content['url'] = goods['detail_url'] # 商品详情页链接
goods_content['price'] = goods['view_price'] # 价格
goods_content['address'] = goods['item_loc'] # 发货地址
goods_content['sales'] = goods['view_sales'] # 已付款人数
goods_content['shops'] = goods['nick'] # 店名
goods_content['comment_count'] = goods['comment_count'] # 评论数
self.save_to_mongo(goods_content)
def save_to_mongo(self, goods_content):
db = client[taget_DB]
if db[taget_TABLE].update_one(goods_content, {'$set': goods_content}, upsert=True):
print('Successfully Saved to Mongo', goods_content)
def run(self, page_num):
page_size = page_num*44
url = self.url_temp.format(page_size)+quote(self.keyword)
json_str = self.parse_url(url)
self.get_goods_list(json_str)
if __name__ == '__main__':
page_num = 2 # 总页码数
taobao=TaoBao()
pool = multiprocessing.Pool()
# 多进程
thread = threading.Thread(target=pool.map, args=(taobao.run, [i for i in range(page_num)]))
thread.start()
thread.join()
辅助程序:config.py,用于连接MongoDB,及设置随机请求UA以应对反爬
import random MONGO_URL = 'localhost' taget_DB = "TAOBAO" taget_TABLE = "TAOBAO" def set_user_agent(): USER_AGENTS = [ "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)", "Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)", "Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)", "Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0", "Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5" ] user_agent = random.choice(USER_AGENTS) return user_agent
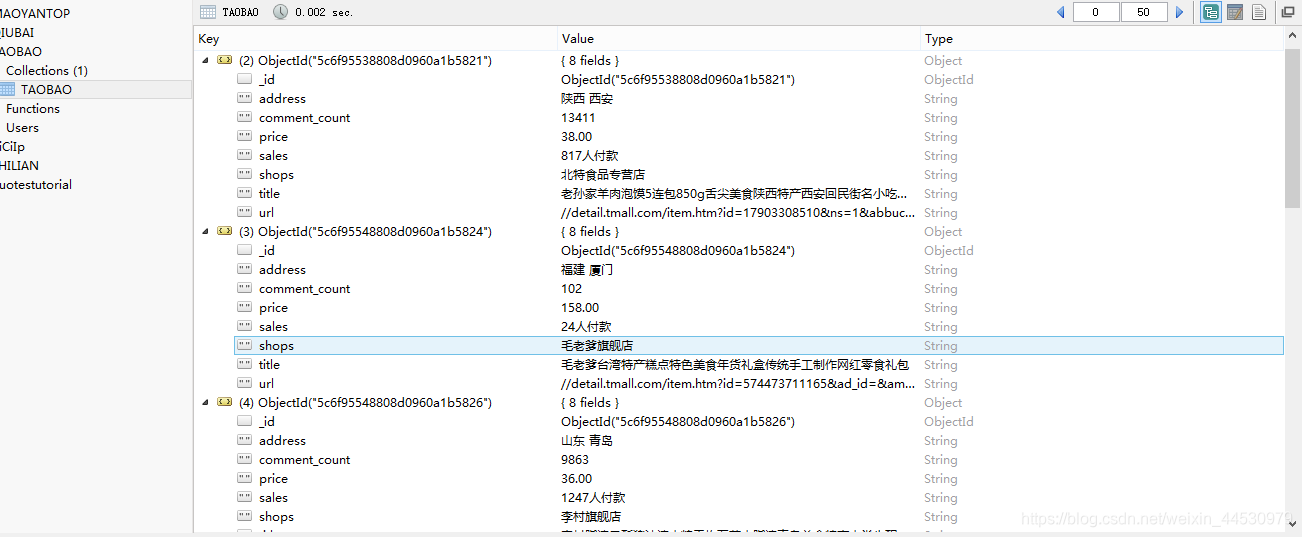
爬取结果如下图:


- Python多线程/进程:os、sys、Queue、multiprocessing、threading
- python3实现爬取淘宝页面的商品的数据信息(selenium+pyquery+mongodb)
- Python实战_1_第一周_第二节练习项目:爬取商品信息
- 简单的抓取淘宝关键字信息、图片的Python爬虫|Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第二篇)
- 实战项目---模拟商品采购中心信息平台
- python爬虫笔记(六):实战(二)淘宝商品比价定向爬虫
- python按综合、销量排序抓取100页的淘宝商品列表信息
- python爬虫爬取淘宝商品信息(selenum+phontomjs)
- 多线程&多进程解析:Python、os、sys、Queue、multiprocessing、threading
- Python多进程并发(multiprocessing)
- Python多进程并发(multiprocessing)
- Python多进程并发(multiprocessing)
- Python的多线程(threading)与多进程(multiprocessing )
- python 多进程并发与多线程并发总结
- python爬虫爬取淘宝商品信息
- python爬取淘宝商品信息并加入购物车
- python 多进程并发与多线程并发总结
- python通信+多线程动手项目——多用户IM ---------- stedy:综合实战项目
- EasyCMS在幼儿园视频直播项目实战中以redis操作池的方式应对高并发的redis操作问题
- Python多进程并发与多线程并发编程实例总结